 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightBagel: A Light-weighted, Double Fusion Framework for Unified Multimodal Understanding and Generation
Oct 27, 2025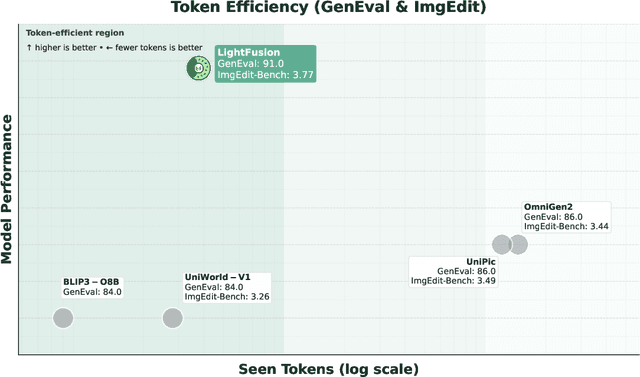
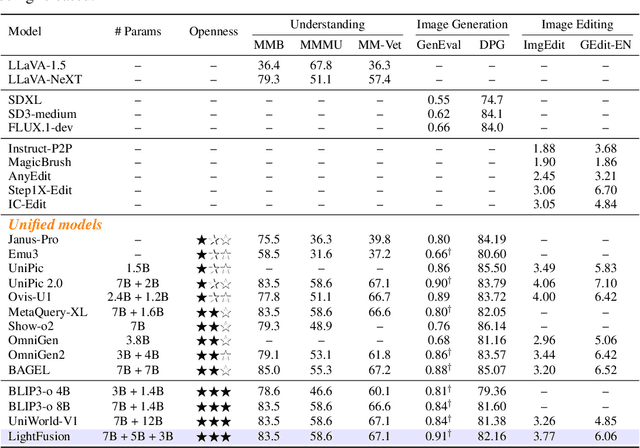
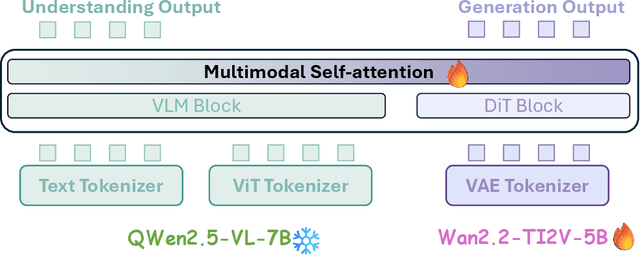
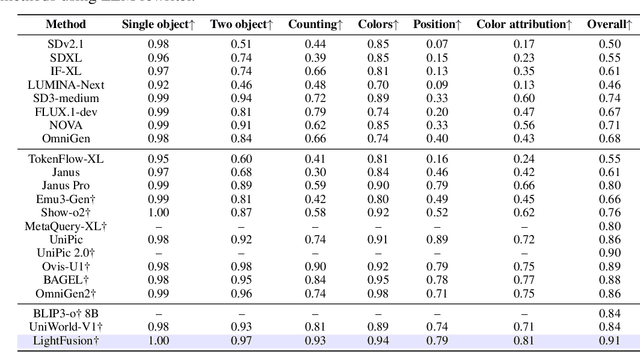
Unified multimodal models have recently shown remarkable gains in both capability and versatility, yet most leading systems are still trained from scratch and require substantial computational resources. In this paper, we show that competitive performance can be obtained far more efficiently by strategically fusing publicly available models specialized for either generation or understanding. Our key design is to retain the original blocks while additionally interleaving multimodal self-attention blocks throughout the networks. This double fusion mechanism (1) effectively enables rich multi-modal fusion while largely preserving the original strengths of the base models, and (2) catalyzes synergistic fusion of high-level semantic representations from the understanding encoder with low-level spatial signals from the generation encoder. By training with only ~ 35B tokens, this approach achieves strong results across multiple benchmarks: 0.91 on GenEval for compositional text-to-image generation, 82.16 on DPG-Bench for complex text-to-image generation, 6.06 on GEditBench, and 3.77 on ImgEdit-Bench for image editing. By fully releasing the entire suite of code, model weights, and datasets, we hope to support future research on unified multimodal modeling.
Artificial Hippocampus Networks for Efficient Long-Context Modeling
Oct 08, 2025Long-sequence modeling faces a fundamental trade-off between the efficiency of compressive fixed-size memory in RNN-like models and the fidelity of lossless growing memory in attention-based Transformers. Inspired by the Multi-Store Model in cognitive science, we introduce a memory framework of artificial neural networks. Our method maintains a sliding window of the Transformer's KV cache as lossless short-term memory, while a learnable module termed Artificial Hippocampus Network (AHN) recurrently compresses out-of-window information into a fixed-size compact long-term memory. To validate this framework, we instantiate AHNs using modern RNN-like architectures, including Mamba2, DeltaNet, and Gated DeltaNet. Extensive experiments on long-context benchmarks LV-Eval and InfiniteBench demonstrate that AHN-augmented models consistently outperform sliding window baselines and achieve performance comparable or even superior to full-attention models, while substantially reducing computational and memory requirements. For instance, augmenting the Qwen2.5-3B-Instruct with AHNs reduces inference FLOPs by 40.5% and memory cache by 74.0%, while improving its average score on LV-Eval (128k sequence length) from 4.41 to 5.88. Code is available at: https://github.com/ByteDance-Seed/AHN.
AsyMoE: Leveraging Modal Asymmetry for Enhanced Expert Specialization in Large Vision-Language Models
Sep 16, 2025Large Vision-Language Models (LVLMs) have demonstrated impressive performance on multimodal tasks through scaled architectures and extensive training. However, existing Mixture of Experts (MoE) approaches face challenges due to the asymmetry between visual and linguistic processing. Visual information is spatially complete, while language requires maintaining sequential context. As a result, MoE models struggle to balance modality-specific features and cross-modal interactions. Through systematic analysis, we observe that language experts in deeper layers progressively lose contextual grounding and rely more on parametric knowledge rather than utilizing the provided visual and linguistic information. To address this, we propose AsyMoE, a novel architecture that models this asymmetry using three specialized expert groups. We design intra-modality experts for modality-specific processing, hyperbolic inter-modality experts for hierarchical cross-modal interactions, and evidence-priority language experts to suppress parametric biases and maintain contextual grounding. Extensive experiments demonstrate that AsyMoE achieves 26.58% and 15.45% accuracy improvements over vanilla MoE and modality-specific MoE respectively, with 25.45% fewer activated parameters than dense models.
X-GRM: Large Gaussian Reconstruction Model for Sparse-view X-rays to Computed Tomography
May 21, 2025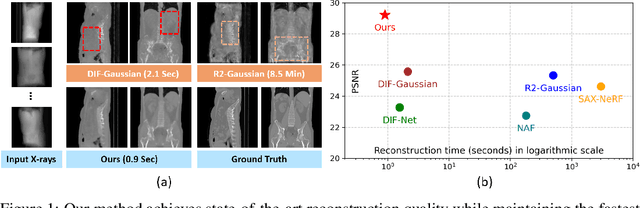

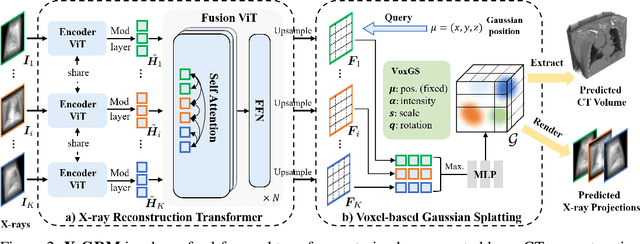
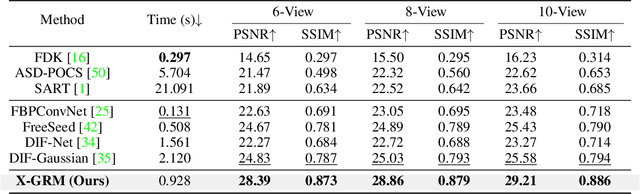
Computed Tomography serves as an indispensable tool in clinical workflows, providing non-invasive visualization of internal anatomical structures. Existing CT reconstruction works are limited to small-capacity model architecture, inflexible volume representation, and small-scale training data. In this paper, we present X-GRM (X-ray Gaussian Reconstruction Model), a large feedforward model for reconstructing 3D CT from sparse-view 2D X-ray projections. X-GRM employs a scalable transformer-based architecture to encode an arbitrary number of sparse X-ray inputs, where tokens from different views are integrated efficiently. Then, tokens are decoded into a new volume representation, named Voxel-based Gaussian Splatting (VoxGS), which enables efficient CT volume extraction and differentiable X-ray rendering. To support the training of X-GRM, we collect ReconX-15K, a large-scale CT reconstruction dataset containing around 15,000 CT/X-ray pairs across diverse organs, including the chest, abdomen, pelvis, and tooth etc. This combination of a high-capacity model, flexible volume representation, and large-scale training data empowers our model to produce high-quality reconstructions from various testing inputs, including in-domain and out-domain X-ray projections. Project Page: https://github.com/CUHK-AIM-Group/X-GRM.
MonoSplat: Generalizable 3D Gaussian Splatting from Monocular Depth Foundation Models
May 21, 2025Recent advances in generalizable 3D Gaussian Splatting have demonstrated promising results in real-time high-fidelity rendering without per-scene optimization, yet existing approaches still struggle to handle unfamiliar visual content during inference on novel scenes due to limited generalizability. To address this challenge, we introduce MonoSplat, a novel framework that leverages rich visual priors from pre-trained monocular depth foundation models for robust Gaussian reconstruction. Our approach consists of two key components: a Mono-Multi Feature Adapter that transforms monocular features into multi-view representations, coupled with an Integrated Gaussian Prediction module that effectively fuses both feature types for precise Gaussian generation. Through the Adapter's lightweight attention mechanism, features are seamlessly aligned and aggregated across views while preserving valuable monocular priors, enabling the Prediction module to generate Gaussian primitives with accurate geometry and appearance. Through extensive experiments on diverse real-world datasets, we convincingly demonstrate that MonoSplat achieves superior reconstruction quality and generalization capability compared to existing methods while maintaining computational efficiency with minimal trainable parameters. Codes are available at https://github.com/CUHK-AIM-Group/MonoSplat.
Emerging Properties in Unified Multimodal Pretraining
May 20, 2025



Unifying multimodal understanding and generation has shown impressive capabilities in cutting-edge proprietary systems. In this work, we introduce BAGEL, an open0source foundational model that natively supports multimodal understanding and generation. BAGEL is a unified, decoder0only model pretrained on trillions of tokens curated from large0scale interleaved text, image, video, and web data. When scaled with such diverse multimodal interleaved data, BAGEL exhibits emerging capabilities in complex multimodal reasoning. As a result, it significantly outperforms open-source unified models in both multimodal generation and understanding across standard benchmarks, while exhibiting advanced multimodal reasoning abilities such as free-form image manipulation, future frame prediction, 3D manipulation, and world navigation. In the hope of facilitating further opportunities for multimodal research, we share the key findings, pretraining details, data creation protocal, and release our code and checkpoints to the community. The project page is at https://bagel-ai.org/
Top-Down Compression: Revisit Efficient Vision Token Projection for Visual Instruction Tuning
May 17, 2025Visual instruction tuning aims to enable large language models to comprehend the visual world, with a pivotal challenge lying in establishing an effective vision-to-language projection. However, existing methods often grapple with the intractable trade-off between accuracy and efficiency. In this paper, we present LLaVA-Meteor, a novel approach designed to break this deadlock, equipped with a novel Top-Down Compression paradigm that strategically compresses visual tokens without compromising core information. Specifically, we construct a trainable Flash Global Fusion module based on efficient selective state space operators, which aligns the feature space while enabling each token to perceive holistic visual context and instruction preference at low cost. Furthermore, a local-to-single scanning manner is employed to effectively capture local dependencies, thereby enhancing the model's capability in vision modeling. To alleviate computational overhead, we explore a Visual-Native Selection mechanism that independently assesses token significance by both the visual and native experts, followed by aggregation to retain the most critical subset. Extensive experiments show that our approach reduces visual tokens by 75--95% while achieving comparable or superior performance across 12 benchmarks, significantly improving efficiency.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
X$^{2}$-Gaussian: 4D Radiative Gaussian Splatting for Continuous-time Tomographic Reconstruction
Mar 27, 2025Four-dimensional computed tomography (4D CT) reconstruction is crucial for capturing dynamic anatomical changes but faces inherent limitations from conventional phase-binning workflows. Current methods discretize temporal resolution into fixed phases with respiratory gating devices, introducing motion misalignment and restricting clinical practicality. In this paper, We propose X$^2$-Gaussian, a novel framework that enables continuous-time 4D-CT reconstruction by integrating dynamic radiative Gaussian splatting with self-supervised respiratory motion learning. Our approach models anatomical dynamics through a spatiotemporal encoder-decoder architecture that predicts time-varying Gaussian deformations, eliminating phase discretization. To remove dependency on external gating devices, we introduce a physiology-driven periodic consistency loss that learns patient-specific breathing cycles directly from projections via differentiable optimization. Extensive experiments demonstrate state-of-the-art performance, achieving a 9.93 dB PSNR gain over traditional methods and 2.25 dB improvement against prior Gaussian splatting techniques. By unifying continuous motion modeling with hardware-free period learning, X$^2$-Gaussian advances high-fidelity 4D CT reconstruction for dynamic clinical imaging. Project website at: https://x2-gaussian.github.io/.
Polyp-Gen: Realistic and Diverse Polyp Image Generation for Endoscopic Dataset Expansion
Jan 29, 2025



Automated diagnostic systems (ADS) have shown significant potential in the early detection of polyps during endoscopic examinations, thereby reducing the incidence of colorectal cancer. However, due to high annotation costs and strict privacy concerns, acquiring high-quality endoscopic images poses a considerable challenge in the development of ADS. Despite recent advancements in generating synthetic images for dataset expansion, existing endoscopic image generation algorithms failed to accurately generate the details of polyp boundary regions and typically required medical priors to specify plausible locations and shapes of polyps, which limited the realism and diversity of the generated images. To address these limitations, we present Polyp-Gen, the first full-automatic diffusion-based endoscopic image generation framework. Specifically, we devise a spatial-aware diffusion training scheme with a lesion-guided loss to enhance the structural context of polyp boundary regions. Moreover, to capture medical priors for the localization of potential polyp areas, we introduce a hierarchical retrieval-based sampling strategy to match similar fine-grained spatial features. In this way, our Polyp-Gen can generate realistic and diverse endoscopic images for building reliable ADS. Extensive experiments demonstrate the state-of-the-art generation quality, and the synthetic images can improve the downstream polyp detection task. Additionally, our Polyp-Gen has shown remarkable zero-shot generalizability on other datasets. The source code is available at https://github.com/CUHK-AIM-Group/Polyp-Gen.