 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Autoregressive Video Diffusion with Dummy Head
Jan 28, 2026The autoregressive video diffusion model has recently gained considerable research interest due to its causal modeling and iterative denoising. In this work, we identify that the multi-head self-attention in these models under-utilizes historical frames: approximately 25% heads attend almost exclusively to the current frame, and discarding their KV caches incurs only minor performance degradation. Building upon this, we propose Dummy Forcing, a simple yet effective method to control context accessibility across different heads. Specifically, the proposed heterogeneous memory allocation reduces head-wise context redundancy, accompanied by dynamic head programming to adaptively classify head types. Moreover, we develop a context packing technique to achieve more aggressive cache compression. Without additional training, our Dummy Forcing delivers up to 2.0x speedup over the baseline, supporting video generation at 24.3 FPS with less than 0.5% quality drop. Project page is available at https://csguoh.github.io/project/DummyForcing/.
PhyGDPO: Physics-Aware Groupwise Direct Preference Optimization for Physically Consistent Text-to-Video Generation
Dec 31, 2025Recent advances in text-to-video (T2V) generation have achieved good visual quality, yet synthesizing videos that faithfully follow physical laws remains an open challenge. Existing methods mainly based on graphics or prompt extension struggle to generalize beyond simple simulated environments or learn implicit physical reasoning. The scarcity of training data with rich physics interactions and phenomena is also a problem. In this paper, we first introduce a Physics-Augmented video data construction Pipeline, PhyAugPipe, that leverages a vision-language model (VLM) with chain-of-thought reasoning to collect a large-scale training dataset, PhyVidGen-135K. Then we formulate a principled Physics-aware Groupwise Direct Preference Optimization, PhyGDPO, framework that builds upon the groupwise Plackett-Luce probabilistic model to capture holistic preferences beyond pairwise comparisons. In PhyGDPO, we design a Physics-Guided Rewarding (PGR) scheme that embeds VLM-based physics rewards to steer optimization toward physical consistency. We also propose a LoRA-Switch Reference (LoRA-SR) scheme that eliminates memory-heavy reference duplication for efficient training. Experiments show that our method significantly outperforms state-of-the-art open-source methods on PhyGenBench and VideoPhy2. Please check our project page at https://caiyuanhao1998.github.io/project/PhyGDPO for more video results. Our code, models, and data will be released at https://github.com/caiyuanhao1998/Open-PhyGDPO
Flow-Matching Guided Deep Unfolding for Hyperspectral Image Reconstruction
Oct 02, 2025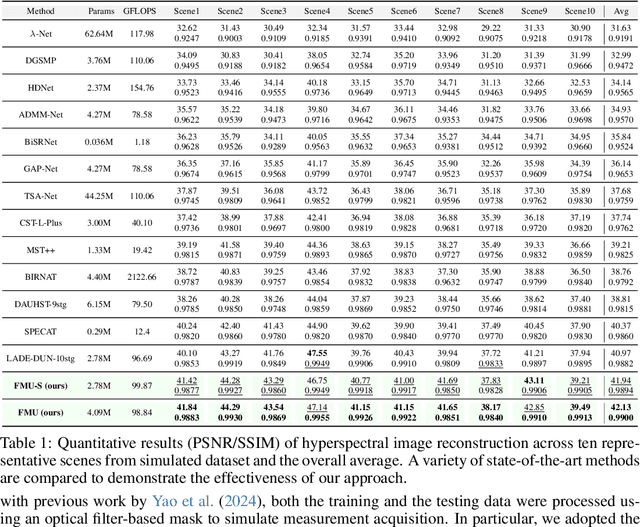

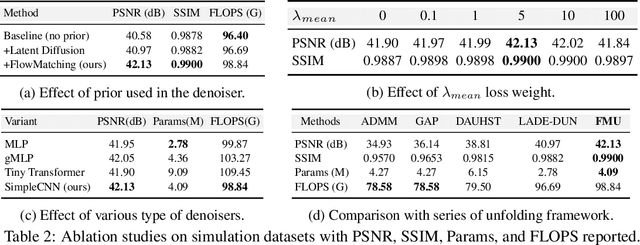
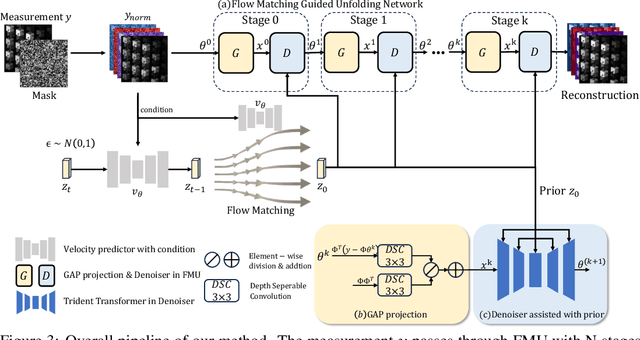
Hyperspectral imaging (HSI) provides rich spatial-spectral information but remains costly to acquire due to hardware limitations and the difficulty of reconstructing three-dimensional data from compressed measurements. Although compressive sensing systems such as CASSI improve efficiency, accurate reconstruction is still challenged by severe degradation and loss of fine spectral details. We propose the Flow-Matching-guided Unfolding network (FMU), which, to our knowledge, is the first to integrate flow matching into HSI reconstruction by embedding its generative prior within a deep unfolding framework. To further strengthen the learned dynamics, we introduce a mean velocity loss that enforces global consistency of the flow, leading to a more robust and accurate reconstruction. This hybrid design leverages the interpretability of optimization-based methods and the generative capacity of flow matching. Extensive experiments on both simulated and real datasets show that FMU significantly outperforms existing approaches in reconstruction quality. Code and models will be available at https://github.com/YiAi03/FMU.
X$^{2}$-Gaussian: 4D Radiative Gaussian Splatting for Continuous-time Tomographic Reconstruction
Mar 27, 2025Four-dimensional computed tomography (4D CT) reconstruction is crucial for capturing dynamic anatomical changes but faces inherent limitations from conventional phase-binning workflows. Current methods discretize temporal resolution into fixed phases with respiratory gating devices, introducing motion misalignment and restricting clinical practicality. In this paper, We propose X$^2$-Gaussian, a novel framework that enables continuous-time 4D-CT reconstruction by integrating dynamic radiative Gaussian splatting with self-supervised respiratory motion learning. Our approach models anatomical dynamics through a spatiotemporal encoder-decoder architecture that predicts time-varying Gaussian deformations, eliminating phase discretization. To remove dependency on external gating devices, we introduce a physiology-driven periodic consistency loss that learns patient-specific breathing cycles directly from projections via differentiable optimization. Extensive experiments demonstrate state-of-the-art performance, achieving a 9.93 dB PSNR gain over traditional methods and 2.25 dB improvement against prior Gaussian splatting techniques. By unifying continuous motion modeling with hardware-free period learning, X$^2$-Gaussian advances high-fidelity 4D CT reconstruction for dynamic clinical imaging. Project website at: https://x2-gaussian.github.io/.
X-LRM: X-ray Large Reconstruction Model for Extremely Sparse-View Computed Tomography Recovery in One Second
Mar 09, 2025Sparse-view 3D CT reconstruction aims to recover volumetric structures from a limited number of 2D X-ray projections. Existing feedforward methods are constrained by the limited capacity of CNN-based architectures and the scarcity of large-scale training datasets. In this paper, we propose an X-ray Large Reconstruction Model (X-LRM) for extremely sparse-view (<10 views) CT reconstruction. X-LRM consists of two key components: X-former and X-triplane. Our X-former can handle an arbitrary number of input views using an MLP-based image tokenizer and a Transformer-based encoder. The output tokens are then upsampled into our X-triplane representation, which models the 3D radiodensity as an implicit neural field. To support the training of X-LRM, we introduce Torso-16K, a large-scale dataset comprising over 16K volume-projection pairs of various torso organs. Extensive experiments demonstrate that X-LRM outperforms the state-of-the-art method by 1.5 dB and achieves 27x faster speed and better flexibility. Furthermore, the downstream evaluation of lung segmentation tasks also suggests the practical value of our approach. Our code, pre-trained models, and dataset will be released at https://github.com/caiyuanhao1998/X-LRM
Motion-X++: A Large-Scale Multimodal 3D Whole-body Human Motion Dataset
Jan 09, 2025



In this paper, we introduce Motion-X++, a large-scale multimodal 3D expressive whole-body human motion dataset. Existing motion datasets predominantly capture body-only poses, lacking facial expressions, hand gestures, and fine-grained pose descriptions, and are typically limited to lab settings with manually labeled text descriptions, thereby restricting their scalability. To address this issue, we develop a scalable annotation pipeline that can automatically capture 3D whole-body human motion and comprehensive textural labels from RGB videos and build the Motion-X dataset comprising 81.1K text-motion pairs. Furthermore, we extend Motion-X into Motion-X++ by improving the annotation pipeline, introducing more data modalities, and scaling up the data quantities. Motion-X++ provides 19.5M 3D whole-body pose annotations covering 120.5K motion sequences from massive scenes, 80.8K RGB videos, 45.3K audios, 19.5M frame-level whole-body pose descriptions, and 120.5K sequence-level semantic labels. Comprehensive experiments validate the accuracy of our annotation pipeline and highlight Motion-X++'s significant benefits for generating expressive, precise, and natural motion with paired multimodal labels supporting several downstream tasks, including text-driven whole-body motion generation,audio-driven motion generation, 3D whole-body human mesh recovery, and 2D whole-body keypoints estimation, etc.
VideoLifter: Lifting Videos to 3D with Fast Hierarchical Stereo Alignment
Jan 03, 2025



Efficiently reconstructing accurate 3D models from monocular video is a key challenge in computer vision, critical for advancing applications in virtual reality, robotics, and scene understanding. Existing approaches typically require pre-computed camera parameters and frame-by-frame reconstruction pipelines, which are prone to error accumulation and entail significant computational overhead. To address these limitations, we introduce VideoLifter, a novel framework that leverages geometric priors from a learnable model to incrementally optimize a globally sparse to dense 3D representation directly from video sequences. VideoLifter segments the video sequence into local windows, where it matches and registers frames, constructs consistent fragments, and aligns them hierarchically to produce a unified 3D model. By tracking and propagating sparse point correspondences across frames and fragments, VideoLifter incrementally refines camera poses and 3D structure, minimizing reprojection error for improved accuracy and robustness. This approach significantly accelerates the reconstruction process, reducing training time by over 82% while surpassing current state-of-the-art methods in visual fidelity and computational efficiency.
Baking Gaussian Splatting into Diffusion Denoiser for Fast and Scalable Single-stage Image-to-3D Generation
Nov 21, 2024



Existing feed-forward image-to-3D methods mainly rely on 2D multi-view diffusion models that cannot guarantee 3D consistency. These methods easily collapse when changing the prompt view direction and mainly handle object-centric prompt images. In this paper, we propose a novel single-stage 3D diffusion model, DiffusionGS, for object and scene generation from a single view. DiffusionGS directly outputs 3D Gaussian point clouds at each timestep to enforce view consistency and allow the model to generate robustly given prompt views of any directions, beyond object-centric inputs. Plus, to improve the capability and generalization ability of DiffusionGS, we scale up 3D training data by developing a scene-object mixed training strategy. Experiments show that our method enjoys better generation quality (2.20 dB higher in PSNR and 23.25 lower in FID) and over 5x faster speed (~6s on an A100 GPU) than SOTA methods. The user study and text-to-3D applications also reveals the practical values of our method. Our Project page at https://caiyuanhao1998.github.io/project/DiffusionGS/ shows the video and interactive generation results.
LucidFusion: Generating 3D Gaussians with Arbitrary Unposed Images
Oct 21, 2024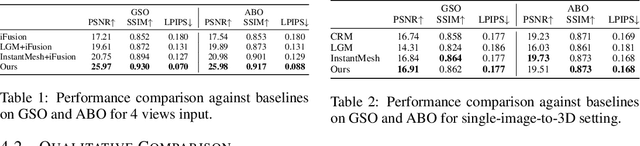
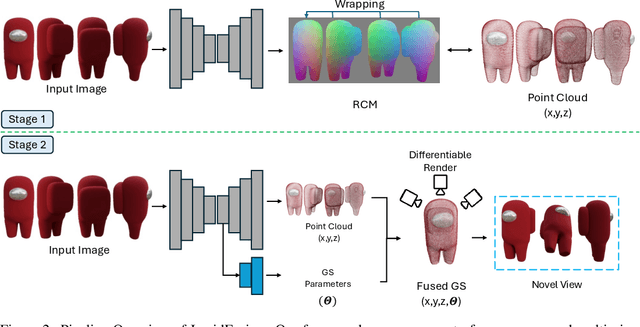

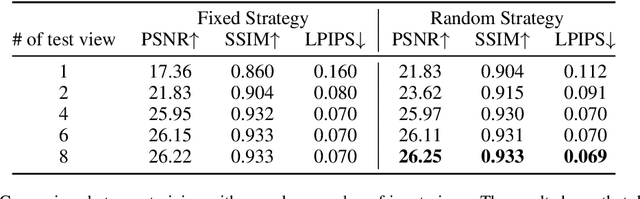
Recent large reconstruction models have made notable progress in generating high-quality 3D objects from single images. However, these methods often struggle with controllability, as they lack information from multiple views, leading to incomplete or inconsistent 3D reconstructions. To address this limitation, we introduce LucidFusion, a flexible end-to-end feed-forward framework that leverages the Relative Coordinate Map (RCM). Unlike traditional methods linking images to 3D world thorough pose, LucidFusion utilizes RCM to align geometric features coherently across different views, making it highly adaptable for 3D generation from arbitrary, unposed images. Furthermore, LucidFusion seamlessly integrates with the original single-image-to-3D pipeline, producing detailed 3D Gaussians at a resolution of $512 \times 512$, making it well-suited for a wide range of applications.
Unveiling Advanced Frequency Disentanglement Paradigm for Low-Light Image Enhancement
Sep 03, 2024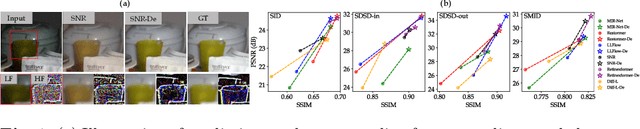
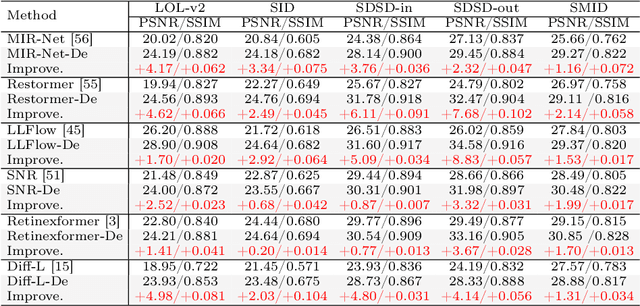
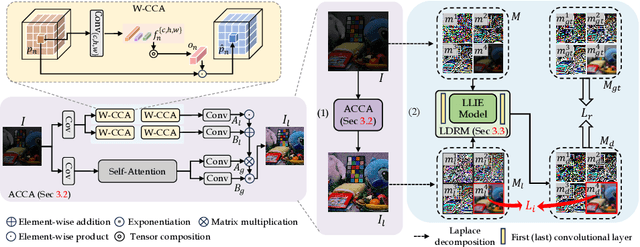

Previous low-light image enhancement (LLIE) approaches, while employing frequency decomposition techniques to address the intertwined challenges of low frequency (e.g., illumination recovery) and high frequency (e.g., noise reduction), primarily focused on the development of dedicated and complex networks to achieve improved performance. In contrast, we reveal that an advanced disentanglement paradigm is sufficient to consistently enhance state-of-the-art methods with minimal computational overhead. Leveraging the image Laplace decomposition scheme, we propose a novel low-frequency consistency method, facilitating improved frequency disentanglement optimization. Our method, seamlessly integrating with various models such as CNNs, Transformers, and flow-based and diffusion models, demonstrates remarkable adaptability. Noteworthy improvements are showcased across five popular benchmarks, with up to 7.68dB gains on PSNR achieved for six state-of-the-art models. Impressively, our approach maintains efficiency with only 88K extra parameters, setting a new standard in the challenging realm of low-light image enhancement.