 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMartian World Models: Controllable Video Synthesis with Physically Accurate 3D Reconstructions
Jul 10, 2025



Synthesizing realistic Martian landscape videos is crucial for mission rehearsal and robotic simulation. However, this task poses unique challenges due to the scarcity of high-quality Martian data and the significant domain gap between Martian and terrestrial imagery. To address these challenges, we propose a holistic solution composed of two key components: 1) A data curation pipeline Multimodal Mars Synthesis (M3arsSynth), which reconstructs 3D Martian environments from real stereo navigation images, sourced from NASA's Planetary Data System (PDS), and renders high-fidelity multiview 3D video sequences. 2) A Martian terrain video generator, MarsGen, which synthesizes novel videos visually realistic and geometrically consistent with the 3D structure encoded in the data. Our M3arsSynth engine spans a wide range of Martian terrains and acquisition dates, enabling the generation of physically accurate 3D surface models at metric-scale resolution. MarsGen, fine-tuned on M3arsSynth data, synthesizes videos conditioned on an initial image frame and, optionally, camera trajectories or textual prompts, allowing for video generation in novel environments. Experimental results show that our approach outperforms video synthesis models trained on terrestrial datasets, achieving superior visual fidelity and 3D structural consistency.
Can Test-Time Scaling Improve World Foundation Model?
Mar 31, 2025World foundation models, which simulate the physical world by predicting future states from current observations and inputs, have become central to many applications in physical intelligence, including autonomous driving and robotics. However, these models require substantial computational resources for pretraining and are further constrained by available data during post-training. As such, scaling computation at test time emerges as both a critical and practical alternative to traditional model enlargement or re-training. In this work, we introduce SWIFT, a test-time scaling framework tailored for WFMs. SWIFT integrates our extensible WFM evaluation toolkit with process-level inference strategies, including fast tokenization, probability-based Top-K pruning, and efficient beam search. Empirical results on the COSMOS model demonstrate that test-time scaling exists even in a compute-optimal way. Our findings reveal that test-time scaling laws hold for WFMs and that SWIFT provides a scalable and effective pathway for improving WFM inference without retraining or increasing model size. The code is available at https://github.com/Mia-Cong/SWIFT.git.
VideoLifter: Lifting Videos to 3D with Fast Hierarchical Stereo Alignment
Jan 03, 2025



Efficiently reconstructing accurate 3D models from monocular video is a key challenge in computer vision, critical for advancing applications in virtual reality, robotics, and scene understanding. Existing approaches typically require pre-computed camera parameters and frame-by-frame reconstruction pipelines, which are prone to error accumulation and entail significant computational overhead. To address these limitations, we introduce VideoLifter, a novel framework that leverages geometric priors from a learnable model to incrementally optimize a globally sparse to dense 3D representation directly from video sequences. VideoLifter segments the video sequence into local windows, where it matches and registers frames, constructs consistent fragments, and aligns them hierarchically to produce a unified 3D model. By tracking and propagating sparse point correspondences across frames and fragments, VideoLifter incrementally refines camera poses and 3D structure, minimizing reprojection error for improved accuracy and robustness. This approach significantly accelerates the reconstruction process, reducing training time by over 82% while surpassing current state-of-the-art methods in visual fidelity and computational efficiency.
APOLLO: SGD-like Memory, AdamW-level Performance
Dec 09, 2024



Large language models (LLMs) are notoriously memory-intensive during training, particularly with the popular AdamW optimizer. This memory burden necessitates using more or higher-end GPUs or reducing batch sizes, limiting training scalability and throughput. To address this, various memory-efficient optimizers have been proposed to reduce optimizer memory usage. However, they face critical challenges: (i) reliance on costly SVD operations; (ii) significant performance trade-offs compared to AdamW; and (iii) still substantial optimizer memory overhead to maintain competitive performance. In this work, we identify that AdamW's learning rate adaptation rule can be effectively coarsened as a structured learning rate update. Based on this insight, we propose Approximated Gradient Scaling for Memory-Efficient LLM Optimization (APOLLO), which approximates learning rate scaling using an auxiliary low-rank optimizer state based on pure random projection. This structured learning rate update rule makes APOLLO highly tolerant to further memory reductions while delivering comparable pre-training performance. Even its rank-1 variant, APOLLO-Mini, achieves superior pre-training performance compared to AdamW with SGD-level memory costs. Extensive experiments demonstrate that the APOLLO series performs on-par with or better than AdamW, while achieving greater memory savings by nearly eliminating the optimization states of AdamW. These savings provide significant system-level benefits: (1) Enhanced Throughput: 3x throughput on an 8xA100-80GB setup compared to AdamW by supporting 4x larger batch sizes. (2) Improved Model Scalability: Pre-training LLaMA-13B with naive DDP on A100-80GB GPUs without system-level optimizations. (3) Low-End GPU Friendly Pre-training: Pre-training LLaMA-7B on a single GPU using less than 12 GB of memory with weight quantization.
PACE: Pacing Operator Learning to Accurate Optical Field Simulation for Complicated Photonic Devices
Nov 05, 2024



Electromagnetic field simulation is central to designing, optimizing, and validating photonic devices and circuits. However, costly computation associated with numerical simulation poses a significant bottleneck, hindering scalability and turnaround time in the photonic circuit design process. Neural operators offer a promising alternative, but existing SOTA approaches, NeurOLight, struggle with predicting high-fidelity fields for real-world complicated photonic devices, with the best reported 0.38 normalized mean absolute error in NeurOLight. The inter-plays of highly complex light-matter interaction, e.g., scattering and resonance, sensitivity to local structure details, non-uniform learning complexity for full-domain simulation, and rich frequency information, contribute to the failure of existing neural PDE solvers. In this work, we boost the prediction fidelity to an unprecedented level for simulating complex photonic devices with a novel operator design driven by the above challenges. We propose a novel cross-axis factorized PACE operator with a strong long-distance modeling capacity to connect the full-domain complex field pattern with local device structures. Inspired by human learning, we further divide and conquer the simulation task for extremely hard cases into two progressively easy tasks, with a first-stage model learning an initial solution refined by a second model. On various complicated photonic device benchmarks, we demonstrate one sole PACE model is capable of achieving 73% lower error with 50% fewer parameters compared with various recent ML for PDE solvers. The two-stage setup further advances high-fidelity simulation for even more intricate cases. In terms of runtime, PACE demonstrates 154-577x and 11.8-12x simulation speedup over numerical solver using scipy or highly-optimized pardiso solver, respectively. We open sourced the code and dataset.
Large Spatial Model: End-to-end Unposed Images to Semantic 3D
Oct 24, 2024



Reconstructing and understanding 3D structures from a limited number of images is a well-established problem in computer vision. Traditional methods usually break this task into multiple subtasks, each requiring complex transformations between different data representations. For instance, dense reconstruction through Structure-from-Motion (SfM) involves converting images into key points, optimizing camera parameters, and estimating structures. Afterward, accurate sparse reconstructions are required for further dense modeling, which is subsequently fed into task-specific neural networks. This multi-step process results in considerable processing time and increased engineering complexity. In this work, we present the Large Spatial Model (LSM), which processes unposed RGB images directly into semantic radiance fields. LSM simultaneously estimates geometry, appearance, and semantics in a single feed-forward operation, and it can generate versatile label maps by interacting with language at novel viewpoints. Leveraging a Transformer-based architecture, LSM integrates global geometry through pixel-aligned point maps. To enhance spatial attribute regression, we incorporate local context aggregation with multi-scale fusion, improving the accuracy of fine local details. To tackle the scarcity of labeled 3D semantic data and enable natural language-driven scene manipulation, we incorporate a pre-trained 2D language-based segmentation model into a 3D-consistent semantic feature field. An efficient decoder then parameterizes a set of semantic anisotropic Gaussians, facilitating supervised end-to-end learning. Extensive experiments across various tasks show that LSM unifies multiple 3D vision tasks directly from unposed images, achieving real-time semantic 3D reconstruction for the first time.
InstantSplat: Unbounded Sparse-view Pose-free Gaussian Splatting in 40 Seconds
Mar 29, 2024While novel view synthesis (NVS) has made substantial progress in 3D computer vision, it typically requires an initial estimation of camera intrinsics and extrinsics from dense viewpoints. This pre-processing is usually conducted via a Structure-from-Motion (SfM) pipeline, a procedure that can be slow and unreliable, particularly in sparse-view scenarios with insufficient matched features for accurate reconstruction. In this work, we integrate the strengths of point-based representations (e.g., 3D Gaussian Splatting, 3D-GS) with end-to-end dense stereo models (DUSt3R) to tackle the complex yet unresolved issues in NVS under unconstrained settings, which encompasses pose-free and sparse view challenges. Our framework, InstantSplat, unifies dense stereo priors with 3D-GS to build 3D Gaussians of large-scale scenes from sparseview & pose-free images in less than 1 minute. Specifically, InstantSplat comprises a Coarse Geometric Initialization (CGI) module that swiftly establishes a preliminary scene structure and camera parameters across all training views, utilizing globally-aligned 3D point maps derived from a pre-trained dense stereo pipeline. This is followed by the Fast 3D-Gaussian Optimization (F-3DGO) module, which jointly optimizes the 3D Gaussian attributes and the initialized poses with pose regularization. Experiments conducted on the large-scale outdoor Tanks & Temples datasets demonstrate that InstantSplat significantly improves SSIM (by 32%) while concurrently reducing Absolute Trajectory Error (ATE) by 80%. These establish InstantSplat as a viable solution for scenarios involving posefree and sparse-view conditions. Project page: instantsplat.github.io.
Enhancing NeRF akin to Enhancing LLMs: Generalizable NeRF Transformer with Mixture-of-View-Experts
Aug 22, 2023Cross-scene generalizable NeRF models, which can directly synthesize novel views of unseen scenes, have become a new spotlight of the NeRF field. Several existing attempts rely on increasingly end-to-end "neuralized" architectures, i.e., replacing scene representation and/or rendering modules with performant neural networks such as transformers, and turning novel view synthesis into a feed-forward inference pipeline. While those feedforward "neuralized" architectures still do not fit diverse scenes well out of the box, we propose to bridge them with the powerful Mixture-of-Experts (MoE) idea from large language models (LLMs), which has demonstrated superior generalization ability by balancing between larger overall model capacity and flexible per-instance specialization. Starting from a recent generalizable NeRF architecture called GNT, we first demonstrate that MoE can be neatly plugged in to enhance the model. We further customize a shared permanent expert and a geometry-aware consistency loss to enforce cross-scene consistency and spatial smoothness respectively, which are essential for generalizable view synthesis. Our proposed model, dubbed GNT with Mixture-of-View-Experts (GNT-MOVE), has experimentally shown state-of-the-art results when transferring to unseen scenes, indicating remarkably better cross-scene generalization in both zero-shot and few-shot settings. Our codes are available at https://github.com/VITA-Group/GNT-MOVE.
Deep Image Harmonization with Learnable Augmentation
Aug 01, 2023



The goal of image harmonization is adjusting the foreground appearance in a composite image to make the whole image harmonious. To construct paired training images, existing datasets adopt different ways to adjust the illumination statistics of foregrounds of real images to produce synthetic composite images. However, different datasets have considerable domain gap and the performances on small-scale datasets are limited by insufficient training data. In this work, we explore learnable augmentation to enrich the illumination diversity of small-scale datasets for better harmonization performance. In particular, our designed SYthetic COmposite Network (SycoNet) takes in a real image with foreground mask and a random vector to learn suitable color transformation, which is applied to the foreground of this real image to produce a synthetic composite image. Comprehensive experiments demonstrate the effectiveness of our proposed learnable augmentation for image harmonization. The code of SycoNet is released at https://github.com/bcmi/SycoNet-Adaptive-Image-Harmonization.
Reference-based Painterly Inpainting via Diffusion: Crossing the Wild Reference Domain Gap
Jul 20, 2023
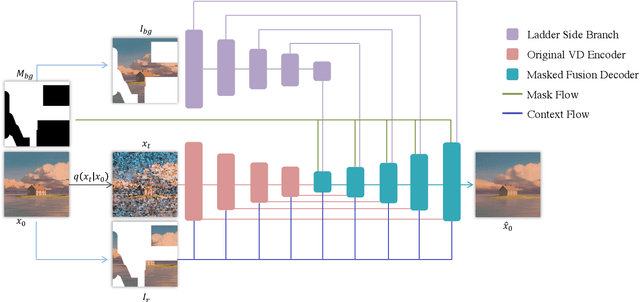


Have you ever imagined how it would look if we placed new objects into paintings? For example, what would it look like if we placed a basketball into Claude Monet's ``Water Lilies, Evening Effect''? We propose Reference-based Painterly Inpainting, a novel task that crosses the wild reference domain gap and implants novel objects into artworks. Although previous works have examined reference-based inpainting, they are not designed for large domain discrepancies between the target and the reference, such as inpainting an artistic image using a photorealistic reference. This paper proposes a novel diffusion framework, dubbed RefPaint, to ``inpaint more wildly'' by taking such references with large domain gaps. Built with an image-conditioned diffusion model, we introduce a ladder-side branch and a masked fusion mechanism to work with the inpainting mask. By decomposing the CLIP image embeddings at inference time, one can manipulate the strength of semantic and style information with ease. Experiments demonstrate that our proposed RefPaint framework produces significantly better results than existing methods. Our method enables creative painterly image inpainting with reference objects that would otherwise be difficult to achieve. Project page: https://vita-group.github.io/RefPaint/