 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Path Not Taken: RLVR Provably Learns Off the Principals
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) reliably improves the reasoning performance of large language models, yet it appears to modify only a small fraction of parameters. We revisit this paradox and show that sparsity is a surface artifact of a model-conditioned optimization bias: for a fixed pretrained model, updates consistently localize to preferred parameter regions, highly consistent across runs and largely invariant to datasets and RL recipes. We mechanistically explain these dynamics with a Three-Gate Theory: Gate I (KL Anchor) imposes a KL-constrained update; Gate II (Model Geometry) steers the step off principal directions into low-curvature, spectrum-preserving subspaces; and Gate III (Precision) hides micro-updates in non-preferred regions, making the off-principal bias appear as sparsity. We then validate this theory and, for the first time, provide a parameter-level characterization of RLVR's learning dynamics: RLVR learns off principal directions in weight space, achieving gains via minimal spectral drift, reduced principal-subspace rotation, and off-principal update alignment. In contrast, SFT targets principal weights, distorts the spectrum, and even lags RLVR. Together, these results provide the first parameter-space account of RLVR's training dynamics, revealing clear regularities in how parameters evolve. Crucially, we show that RL operates in a distinct optimization regime from SFT, so directly adapting SFT-era parameter-efficient fine-tuning (PEFT) methods can be flawed, as evidenced by our case studies on advanced sparse fine-tuning and LoRA variants. We hope this work charts a path toward a white-box understanding of RLVR and the design of geometry-aware, RLVR-native learning algorithms, rather than repurposed SFT-era heuristics.
APOLLO: SGD-like Memory, AdamW-level Performance
Dec 09, 2024



Large language models (LLMs) are notoriously memory-intensive during training, particularly with the popular AdamW optimizer. This memory burden necessitates using more or higher-end GPUs or reducing batch sizes, limiting training scalability and throughput. To address this, various memory-efficient optimizers have been proposed to reduce optimizer memory usage. However, they face critical challenges: (i) reliance on costly SVD operations; (ii) significant performance trade-offs compared to AdamW; and (iii) still substantial optimizer memory overhead to maintain competitive performance. In this work, we identify that AdamW's learning rate adaptation rule can be effectively coarsened as a structured learning rate update. Based on this insight, we propose Approximated Gradient Scaling for Memory-Efficient LLM Optimization (APOLLO), which approximates learning rate scaling using an auxiliary low-rank optimizer state based on pure random projection. This structured learning rate update rule makes APOLLO highly tolerant to further memory reductions while delivering comparable pre-training performance. Even its rank-1 variant, APOLLO-Mini, achieves superior pre-training performance compared to AdamW with SGD-level memory costs. Extensive experiments demonstrate that the APOLLO series performs on-par with or better than AdamW, while achieving greater memory savings by nearly eliminating the optimization states of AdamW. These savings provide significant system-level benefits: (1) Enhanced Throughput: 3x throughput on an 8xA100-80GB setup compared to AdamW by supporting 4x larger batch sizes. (2) Improved Model Scalability: Pre-training LLaMA-13B with naive DDP on A100-80GB GPUs without system-level optimizations. (3) Low-End GPU Friendly Pre-training: Pre-training LLaMA-7B on a single GPU using less than 12 GB of memory with weight quantization.
Generative Model-based Simulation of Driver Behavior when Using Control Input Interface for Teleoperated Driving in Unstructured Canyon Terrains
May 17, 2023


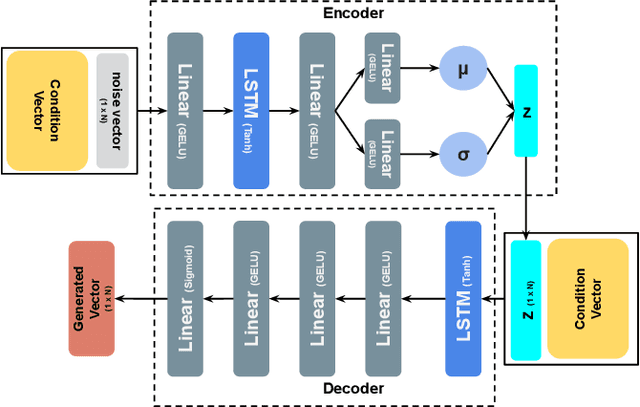
Unmanned ground vehicles (UGVs) in unstructured environments mostly operate through teleoperation. To enable stable teleoperated driving in unstructured environments, some research has suggested driver assistance and evaluation methods that involve user studies, which can be costly and require lots of time and effort. A simulation model-based approach has been proposed to complement the user study; however, the models on teleoperated driving do not account for unstructured environments. Our proposed solution involves simulation models of teleoperated driving for drivers that utilize a deep generative model. Initially, we build a teleoperated driving simulator to imitate unstructured environments based on previous research and collect driving data from drivers. Then, we design and implement the simulation models based on a conditional variational autoencoder (CVAE). Our evaluation results demonstrate that the proposed teleoperated driving model can generate data by simulating the driver appropriately in unstructured canyon terrains.
Machining feature recognition using descriptors with range constraints for mechanical 3D models
Jan 09, 2023In machining feature recognition, geometric elements generated in a three-dimensional computer-aided design model are identified. This technique is used in manufacturability evaluation, process planning, and tool path generation. Here, we propose a method of recognizing 16 types of machining features using descriptors, often used in shape-based part retrieval studies. The base face is selected for each feature type, and descriptors express the base face's minimum, maximum, and equal conditions. Furthermore, the similarity in the three conditions between the descriptors extracted from the target face and those from the base face is calculated. If the similarity is greater than or equal to the threshold, the target face is determined as the base face of the feature. Machining feature recognition tests were conducted for two test cases using the proposed method, and all machining features included in the test cases were successfully recognized. Also, it was confirmed through an additional test that the proposed method in this study showed better feature recognition performance than the latest artificial neural network.
GoonDAE: Denoising-Based Driver Assistance for Off-Road Teleoperation
Sep 08, 2022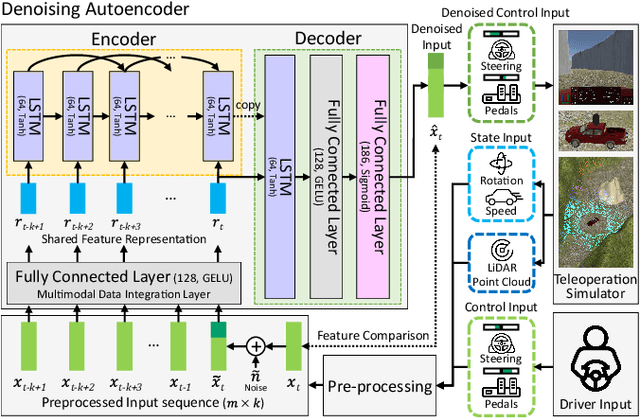
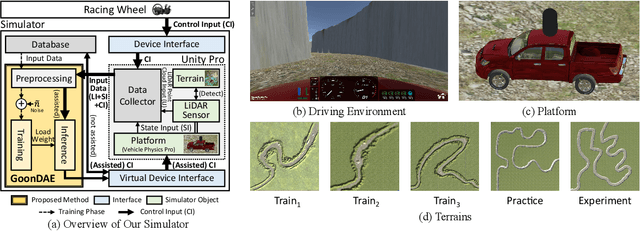
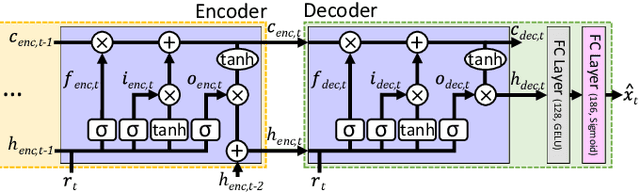

Because of the limitations of autonomous driving technologies, teleoperation is widely used in dangerous environments such as military operations. However, the teleoperated driving performance depends considerably on the driver's skill level. Moreover, unskilled drivers need extensive training time for teleoperations in unusual and harsh environments. To address this problem, we propose a novel denoising-based driver assistance method, namely GoonDAE, for real-time teleoperated off-road driving. The unskilled driver control input is assumed to be the same as the skilled driver control input but with noise. We designed a skip-connected long short-term memory (LSTM)-based denoising autoencoder (DAE) model to assist the unskilled driver control input by denoising. The proposed GoonDAE was trained with skilled driver control input and sensor data collected from our simulated off-road driving environment. To evaluate GoonDAE, we conducted an experiment with unskilled drivers in the simulated environment. The results revealed that the proposed system considerably enhanced driving performance in terms of driving stability.
LSQ+: Improving low-bit quantization through learnable offsets and better initialization
Apr 20, 2020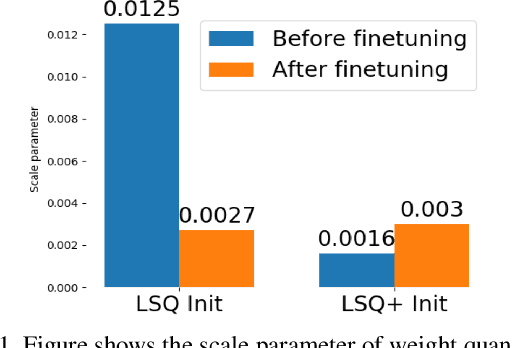

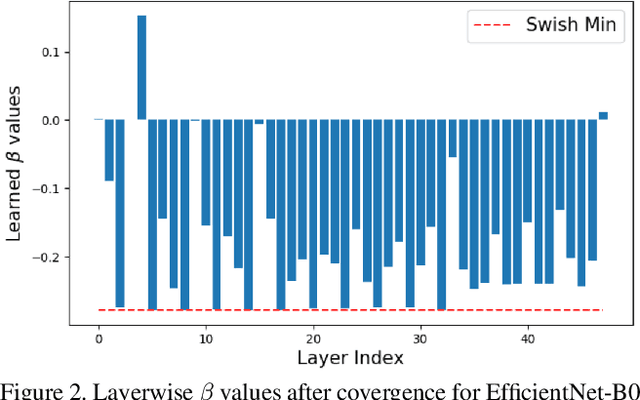
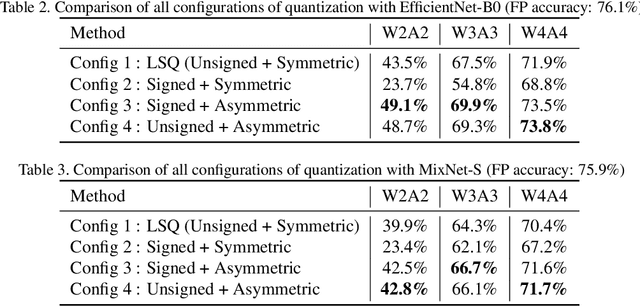
Unlike ReLU, newer activation functions (like Swish, H-swish, Mish) that are frequently employed in popular efficient architectures can also result in negative activation values, with skewed positive and negative ranges. Typical learnable quantization schemes [PACT, LSQ] assume unsigned quantization for activations and quantize all negative activations to zero which leads to significant loss in performance. Naively using signed quantization to accommodate these negative values requires an extra sign bit which is expensive for low-bit (2-, 3-, 4-bit) quantization. To solve this problem, we propose LSQ+, a natural extension of LSQ, wherein we introduce a general asymmetric quantization scheme with trainable scale and offset parameters that can learn to accommodate the negative activations. Gradient-based learnable quantization schemes also commonly suffer from high instability or variance in the final training performance, hence requiring a great deal of hyper-parameter tuning to reach a satisfactory performance. LSQ+ alleviates this problem by using an MSE-based initialization scheme for the quantization parameters. We show that this initialization leads to significantly lower variance in final performance across multiple training runs. Overall, LSQ+ shows state-of-the-art results for EfficientNet and MixNet and also significantly outperforms LSQ for low-bit quantization of neural nets with Swish activations (e.g.: 1.8% gain with W4A4 quantization and upto 5.6% gain with W2A2 quantization of EfficientNet-B0 on ImageNet dataset). To the best of our knowledge, ours is the first work to quantize such architectures to extremely low bit-widths.
Ordering Chaos: Memory-Aware Scheduling of Irregularly Wired Neural Networks for Edge Devices
Mar 04, 2020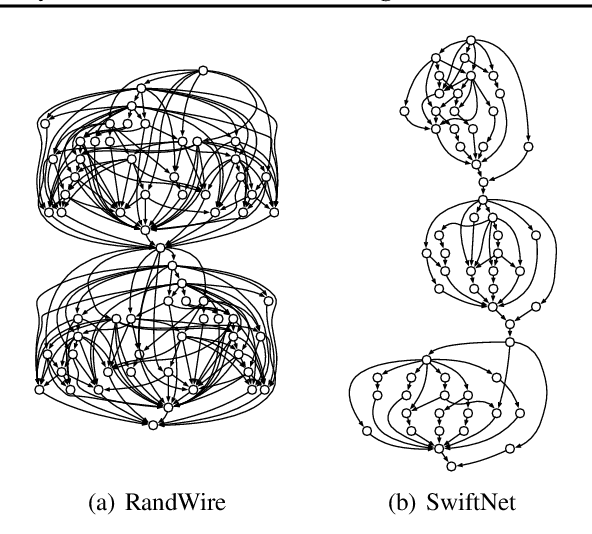
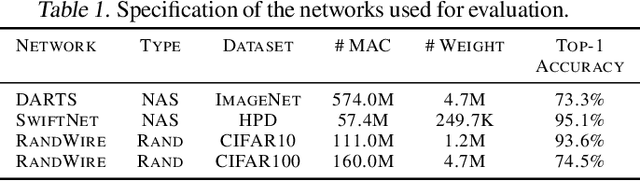
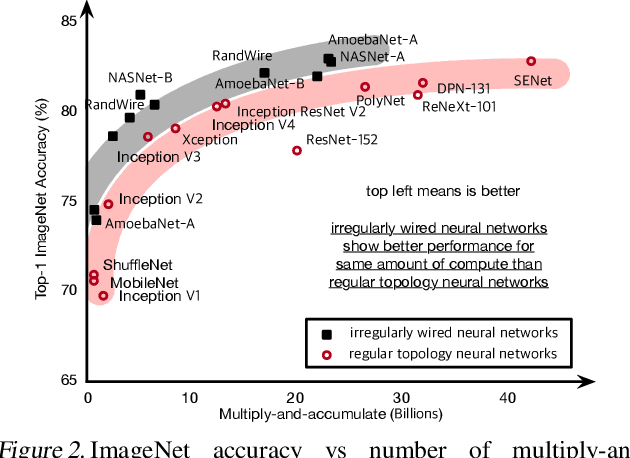
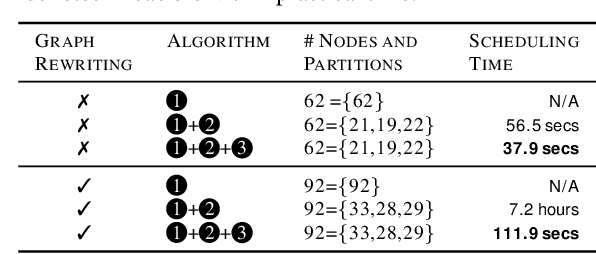
Recent advances demonstrate that irregularly wired neural networks from Neural Architecture Search (NAS) and Random Wiring can not only automate the design of deep neural networks but also emit models that outperform previous manual designs. These designs are especially effective while designing neural architectures under hard resource constraints (memory, MACs, . . . ) which highlights the importance of this class of designing neural networks. However, such a move creates complication in the previously streamlined pattern of execution. In fact one of the main challenges is that the order of such nodes in the neural network significantly effects the memory footprint of the intermediate activations. Current compilers do not schedule with regard to activation memory footprint that it significantly increases its peak compared to the optimum, rendering it not applicable for edge devices. To address this standing issue, we present a memory-aware compiler, dubbed SERENITY, that utilizes dynamic programming to find a sequence that finds a schedule with optimal memory footprint. Our solution also comprises of graph rewriting technique that allows further reduction beyond the optimum. As such, SERENITY achieves optimal peak memory, and the graph rewriting technique further improves this resulting in 1.68x improvement with dynamic programming-based scheduler and 1.86x with graph rewriting, against TensorFlow Lite with less than one minute overhead.
Learned Threshold Pruning
Feb 28, 2020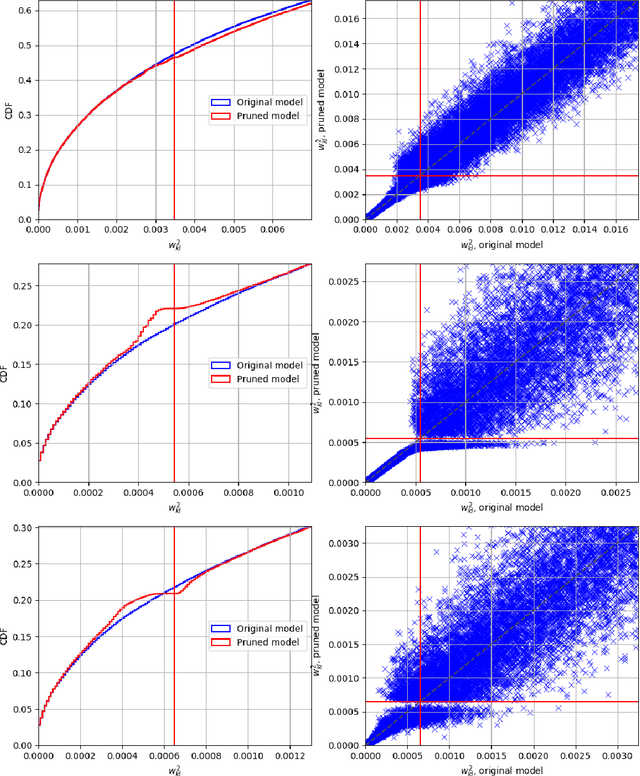
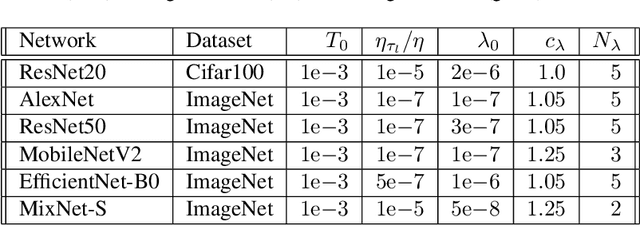
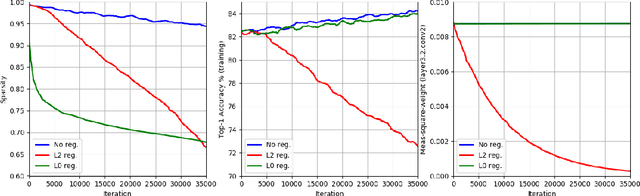
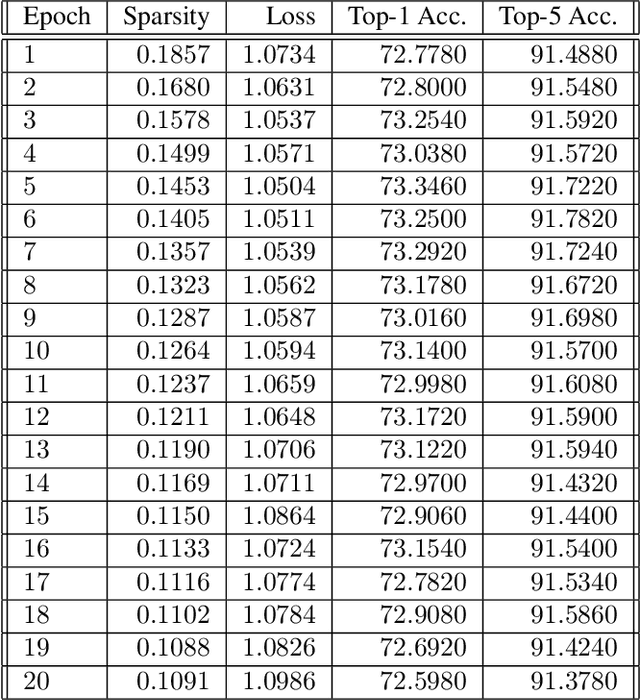
This paper presents a novel differentiable method for unstructured weight pruning of deep neural networks. Our learned-threshold pruning (LTP) method enjoys a number of important advantages. First, it learns per-layer thresholds via gradient descent, unlike conventional methods where they are set as input. Making thresholds trainable also makes LTP computationally efficient, hence scalable to deeper networks. For example, it takes less than $30$ epochs for LTP to prune most networks on ImageNet. This is in contrast to other methods that search for per-layer thresholds via a computationally intensive iterative pruning and fine-tuning process. Additionally, with a novel differentiable $L_0$ regularization, LTP is able to operate effectively on architectures with batch-normalization. This is important since $L_1$ and $L_2$ penalties lose their regularizing effect in networks with batch-normalization. Finally, LTP generates a trail of progressively sparser networks from which the desired pruned network can be picked based on sparsity and performance requirements. These features allow LTP to achieve state-of-the-art compression rates on ImageNet networks such as AlexNet ($26.4\times$ compression with $79.1\%$ Top-5 accuracy) and ResNet50 ($9.1\times$ compression with $92.0\%$ Top-5 accuracy). We also show that LTP effectively prunes newer architectures, such as EfficientNet, MobileNetV2 and MixNet.
QKD: Quantization-aware Knowledge Distillation
Nov 28, 2019

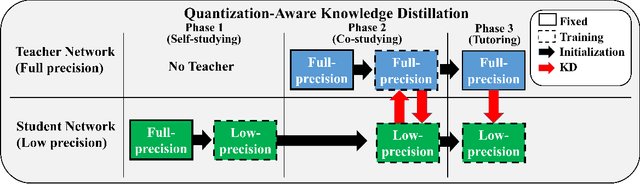
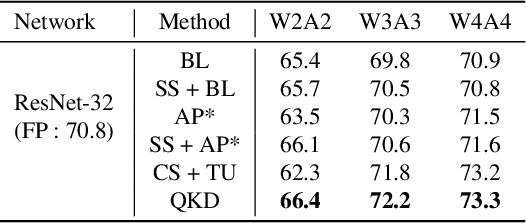
Quantization and Knowledge distillation (KD) methods are widely used to reduce memory and power consumption of deep neural networks (DNNs), especially for resource-constrained edge devices. Although their combination is quite promising to meet these requirements, it may not work as desired. It is mainly because the regularization effect of KD further diminishes the already reduced representation power of a quantized model. To address this short-coming, we propose Quantization-aware Knowledge Distillation (QKD) wherein quantization and KD are care-fully coordinated in three phases. First, Self-studying (SS) phase fine-tunes a quantized low-precision student network without KD to obtain a good initialization. Second, Co-studying (CS) phase tries to train a teacher to make it more quantizaion-friendly and powerful than a fixed teacher. Finally, Tutoring (TU) phase transfers knowledge from the trained teacher to the student. We extensively evaluate our method on ImageNet and CIFAR-10/100 datasets and show an ablation study on networks with both standard and depthwise-separable convolutions. The proposed QKD outperformed existing state-of-the-art methods (e.g., 1.3% improvement on ResNet-18 with W4A4, 2.6% on MobileNetV2 with W4A4). Additionally, QKD could recover the full-precision accuracy at as low as W3A3 quantization on ResNet and W6A6 quantization on MobilenetV2.
Automatic Grammar Augmentation for Robust Voice Command Recognition
Nov 14, 2018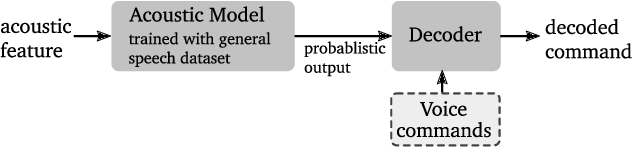


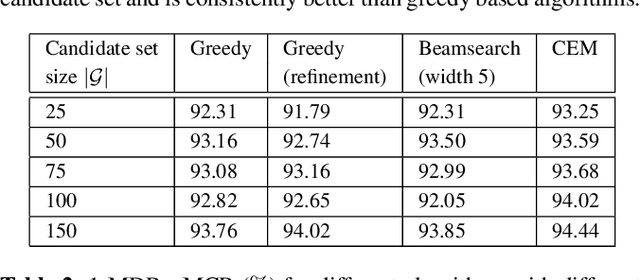
This paper proposes a novel pipeline for automatic grammar augmentation that provides a significant improvement in the voice command recognition accuracy for systems with small footprint acoustic model (AM). The improvement is achieved by augmenting the user-defined voice command set, also called grammar set, with alternate grammar expressions. For a given grammar set, a set of potential grammar expressions (candidate set) for augmentation is constructed from an AM-specific statistical pronunciation dictionary that captures the consistent patterns and errors in the decoding of AM induced by variations in pronunciation, pitch, tempo, accent, ambiguous spellings, and noise conditions. Using this candidate set, greedy optimization based and cross-entropy-method (CEM) based algorithms are considered to search for an augmented grammar set with improved recognition accuracy utilizing a command-specific dataset. Our experiments show that the proposed pipeline along with algorithms considered in this paper significantly reduce the mis-detection and mis-classification rate without increasing the false-alarm rate. Experiments also demonstrate the consistent superior performance of CEM method over greedy-based algorithms.