 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransAdapt: A Transformative Framework for Online Test Time Adaptive Semantic Segmentation
Feb 24, 2023Test-time adaptive (TTA) semantic segmentation adapts a source pre-trained image semantic segmentation model to unlabeled batches of target domain test images, different from real-world, where samples arrive one-by-one in an online fashion. To tackle online settings, we propose TransAdapt, a framework that uses transformer and input transformations to improve segmentation performance. Specifically, we pre-train a transformer-based module on a segmentation network that transforms unsupervised segmentation output to a more reliable supervised output, without requiring test-time online training. To also facilitate test-time adaptation, we propose an unsupervised loss based on the transformed input that enforces the model to be invariant and equivariant to photometric and geometric perturbations, respectively. Overall, our framework produces higher quality segmentation masks with up to 17.6% and 2.8% mIOU improvement over no-adaptation and competitive baselines, respectively.
Test-time Adaptation vs. Training-time Generalization: A Case Study in Human Instance Segmentation using Keypoints Estimation
Dec 12, 2022



We consider the problem of improving the human instance segmentation mask quality for a given test image using keypoints estimation. We compare two alternative approaches. The first approach is a test-time adaptation (TTA) method, where we allow test-time modification of the segmentation network's weights using a single unlabeled test image. In this approach, we do not assume test-time access to the labeled source dataset. More specifically, our TTA method consists of using the keypoints estimates as pseudo labels and backpropagating them to adjust the backbone weights. The second approach is a training-time generalization (TTG) method, where we permit offline access to the labeled source dataset but not the test-time modification of weights. Furthermore, we do not assume the availability of any images from or knowledge about the target domain. Our TTG method consists of augmenting the backbone features with those generated by the keypoints head and feeding the aggregate vector to the mask head. Through a comprehensive set of ablations, we evaluate both approaches and identify several factors limiting the TTA gains. In particular, we show that in the absence of a significant domain shift, TTA may hurt and TTG show only a small gain in performance, whereas for a large domain shift, TTA gains are smaller and dependent on the heuristics used, while TTG gains are larger and robust to architectural choices.
Unsupervised Information Obfuscation for Split Inference of Neural Networks
Apr 23, 2021
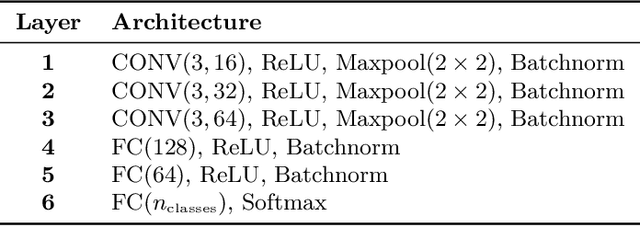

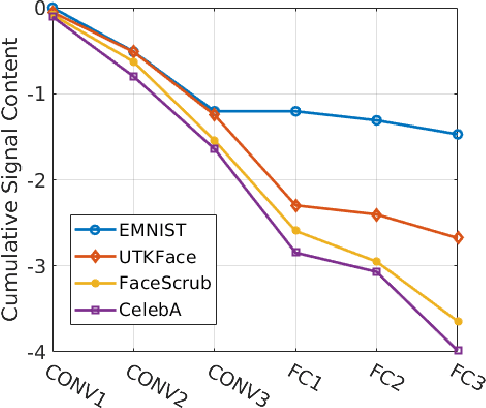
Splitting network computations between the edge device and a server enables low edge-compute inference of neural networks but might expose sensitive information about the test query to the server. To address this problem, existing techniques train the model to minimize information leakage for a given set of sensitive attributes. In practice, however, the test queries might contain attributes that are not foreseen during training. We propose instead an unsupervised obfuscation method to discard the information irrelevant to the main task. We formulate the problem via an information theoretical framework and derive an analytical solution for a given distortion to the model output. In our method, the edge device runs the model up to a split layer determined based on its computational capacity. It then obfuscates the obtained feature vector based on the first layer of the server model by removing the components in the null space as well as the low-energy components of the remaining signal. Our experimental results show that our method outperforms existing techniques in removing the information of the irrelevant attributes and maintaining the accuracy on the target label. We also show that our method reduces the communication cost and incurs only a small computational overhead.
Cascade Weight Shedding in Deep Neural Networks: Benefits and Pitfalls for Network Pruning
Mar 19, 2021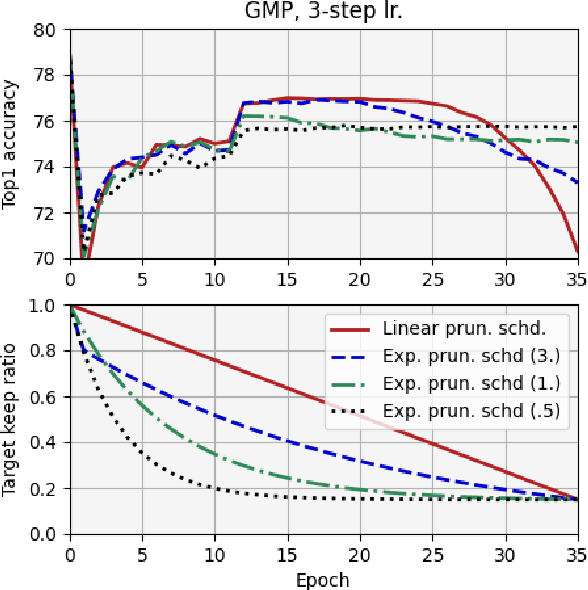
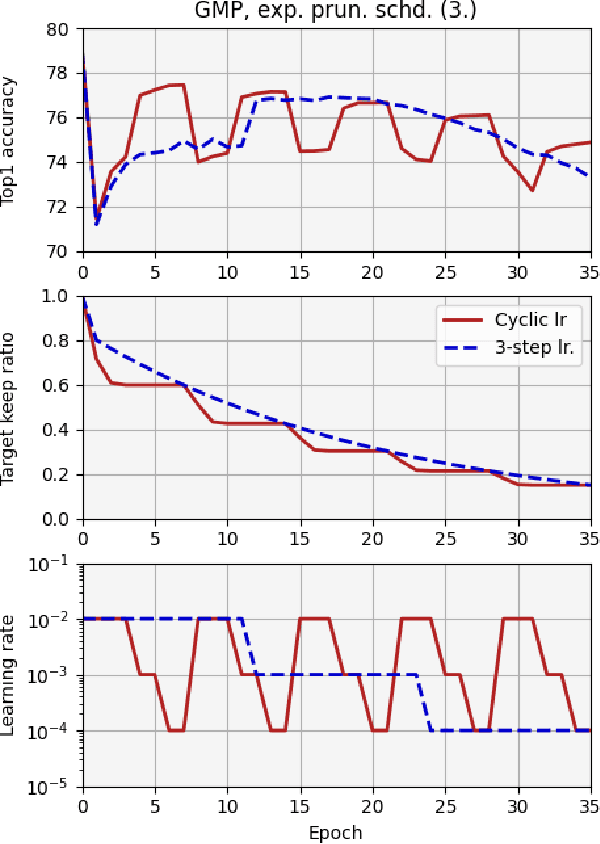
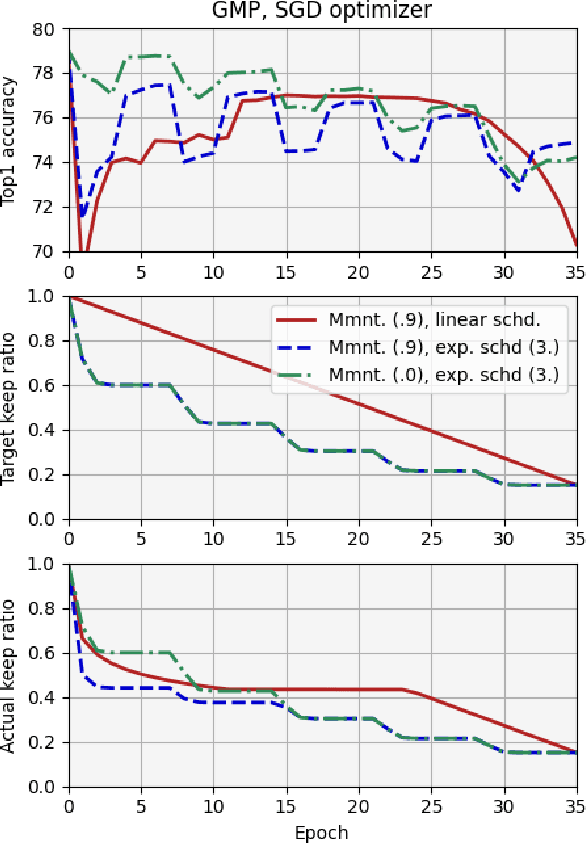
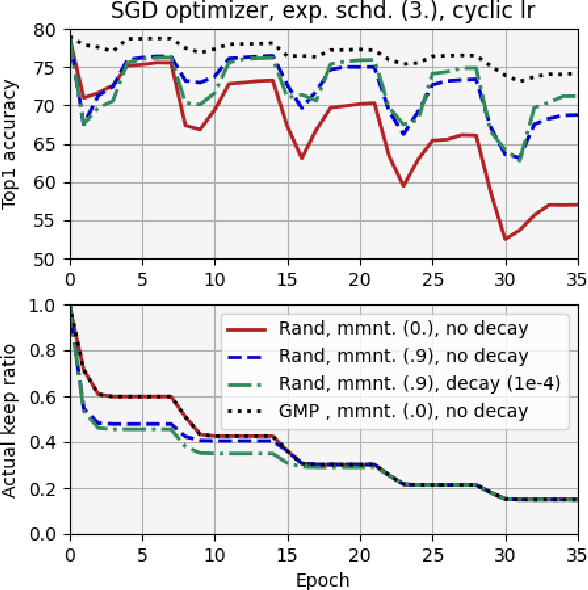
We report, for the first time, on the cascade weight shedding phenomenon in deep neural networks where in response to pruning a small percentage of a network's weights, a large percentage of the remaining is shed over a few epochs during the ensuing fine-tuning phase. We show that cascade weight shedding, when present, can significantly improve the performance of an otherwise sub-optimal scheme such as random pruning. This explains why some pruning methods may perform well under certain circumstances, but poorly under others, e.g., ResNet50 vs. MobileNetV3. We provide insight into why the global magnitude-based pruning, i.e., GMP, despite its simplicity, provides a competitive performance for a wide range of scenarios. We also demonstrate cascade weight shedding's potential for improving GMP's accuracy, and reduce its computational complexity. In doing so, we highlight the importance of pruning and learning-rate schedules. We shed light on weight and learning-rate rewinding methods of re-training, showing their possible connections to the cascade weight shedding and reason for their advantage over fine-tuning. We also investigate cascade weight shedding's effect on the set of kept weights, and its implications for semi-structured pruning. Finally, we give directions for future research.
Learned Threshold Pruning
Feb 28, 2020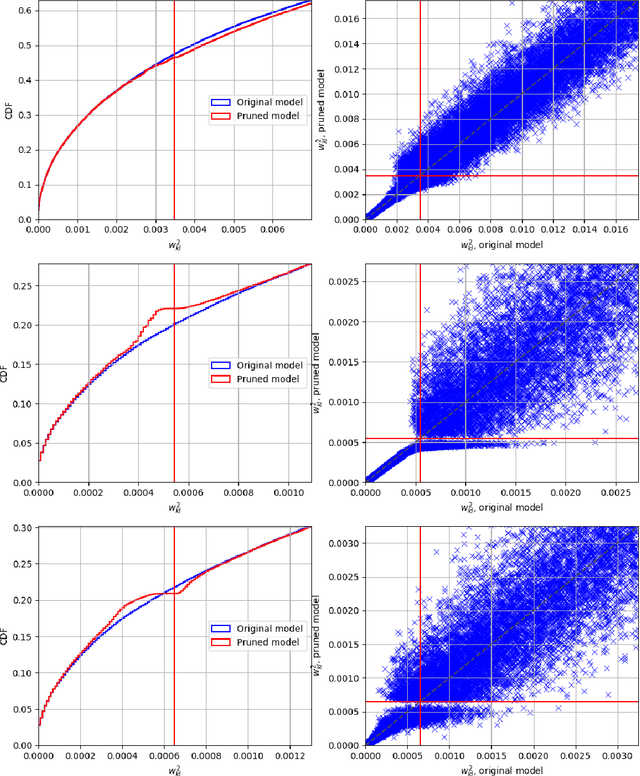
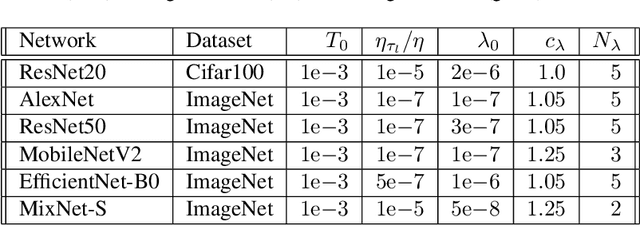
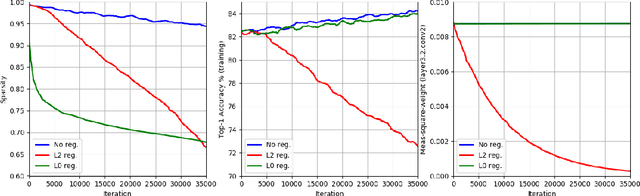
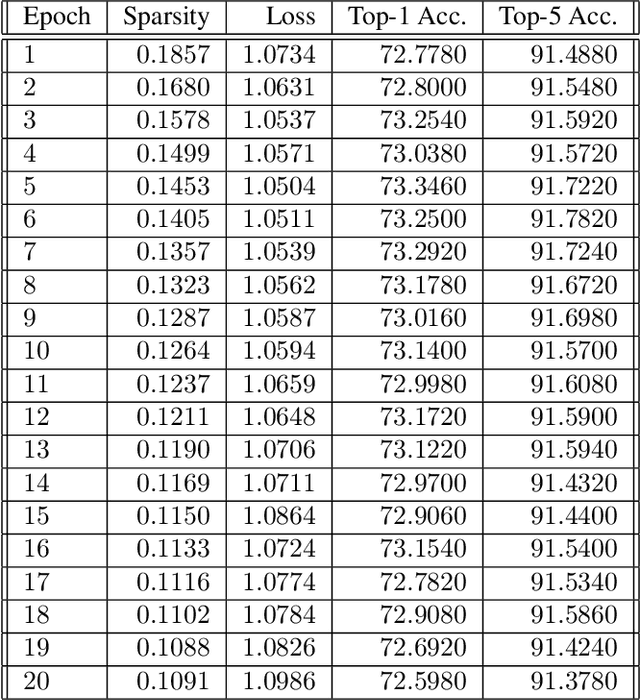
This paper presents a novel differentiable method for unstructured weight pruning of deep neural networks. Our learned-threshold pruning (LTP) method enjoys a number of important advantages. First, it learns per-layer thresholds via gradient descent, unlike conventional methods where they are set as input. Making thresholds trainable also makes LTP computationally efficient, hence scalable to deeper networks. For example, it takes less than $30$ epochs for LTP to prune most networks on ImageNet. This is in contrast to other methods that search for per-layer thresholds via a computationally intensive iterative pruning and fine-tuning process. Additionally, with a novel differentiable $L_0$ regularization, LTP is able to operate effectively on architectures with batch-normalization. This is important since $L_1$ and $L_2$ penalties lose their regularizing effect in networks with batch-normalization. Finally, LTP generates a trail of progressively sparser networks from which the desired pruned network can be picked based on sparsity and performance requirements. These features allow LTP to achieve state-of-the-art compression rates on ImageNet networks such as AlexNet ($26.4\times$ compression with $79.1\%$ Top-5 accuracy) and ResNet50 ($9.1\times$ compression with $92.0\%$ Top-5 accuracy). We also show that LTP effectively prunes newer architectures, such as EfficientNet, MobileNetV2 and MixNet.