 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Weight Shedding in Deep Neural Networks: Benefits and Pitfalls for Network Pruning
Paper and Code
Mar 19, 2021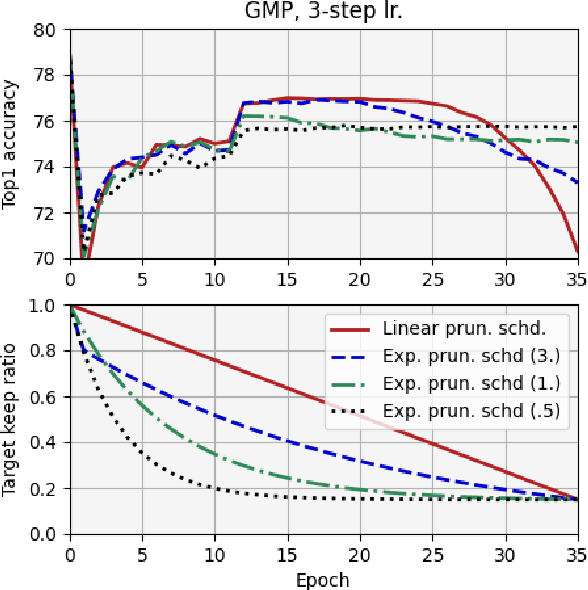
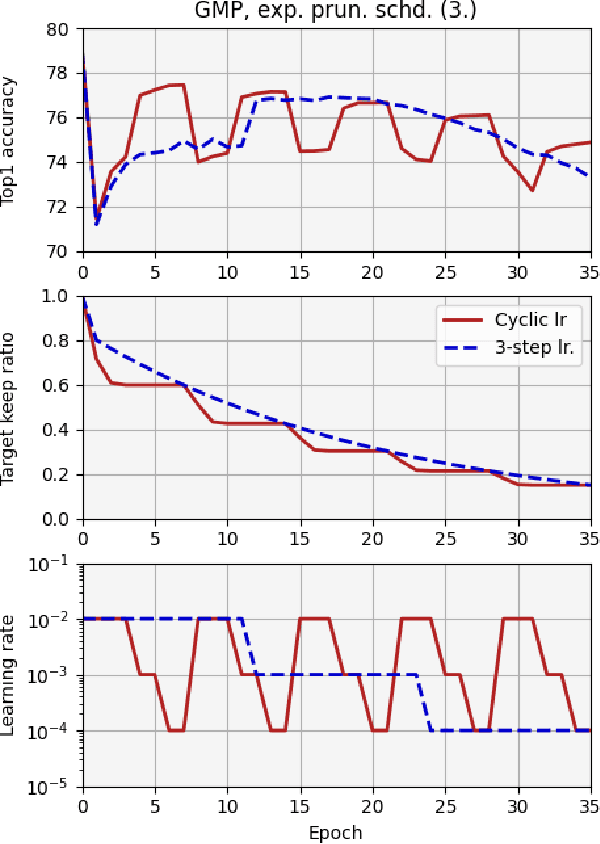
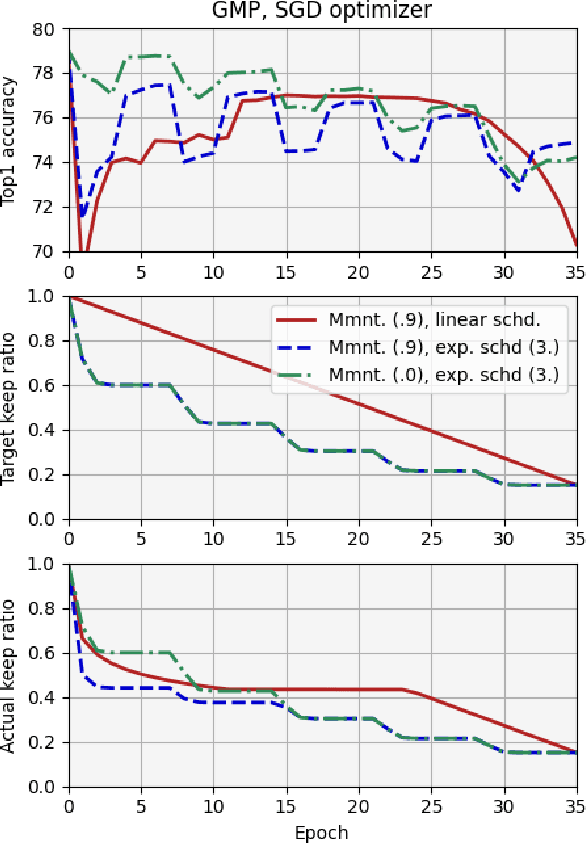
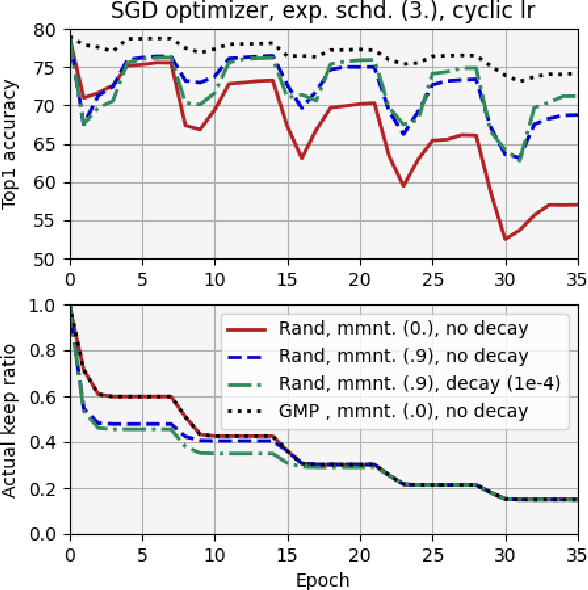
We report, for the first time, on the cascade weight shedding phenomenon in deep neural networks where in response to pruning a small percentage of a network's weights, a large percentage of the remaining is shed over a few epochs during the ensuing fine-tuning phase. We show that cascade weight shedding, when present, can significantly improve the performance of an otherwise sub-optimal scheme such as random pruning. This explains why some pruning methods may perform well under certain circumstances, but poorly under others, e.g., ResNet50 vs. MobileNetV3. We provide insight into why the global magnitude-based pruning, i.e., GMP, despite its simplicity, provides a competitive performance for a wide range of scenarios. We also demonstrate cascade weight shedding's potential for improving GMP's accuracy, and reduce its computational complexity. In doing so, we highlight the importance of pruning and learning-rate schedules. We shed light on weight and learning-rate rewinding methods of re-training, showing their possible connections to the cascade weight shedding and reason for their advantage over fine-tuning. We also investigate cascade weight shedding's effect on the set of kept weights, and its implications for semi-structured pruning. Finally, we give directions for future research.