 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-REC: Private & Communication-Efficient Federated Learning
Nov 09, 2021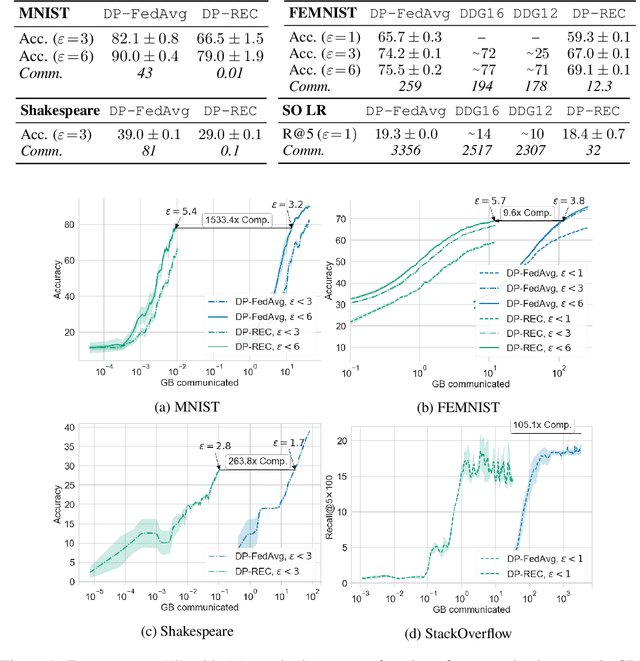


Privacy and communication efficiency are important challenges in federated training of neural networks, and combining them is still an open problem. In this work, we develop a method that unifies highly compressed communication and differential privacy (DP). We introduce a compression technique based on Relative Entropy Coding (REC) to the federated setting. With a minor modification to REC, we obtain a provably differentially private learning algorithm, DP-REC, and show how to compute its privacy guarantees. Our experiments demonstrate that DP-REC drastically reduces communication costs while providing privacy guarantees comparable to the state-of-the-art.
Unsupervised Information Obfuscation for Split Inference of Neural Networks
Apr 23, 2021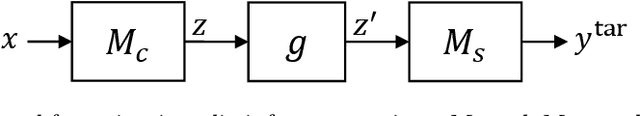

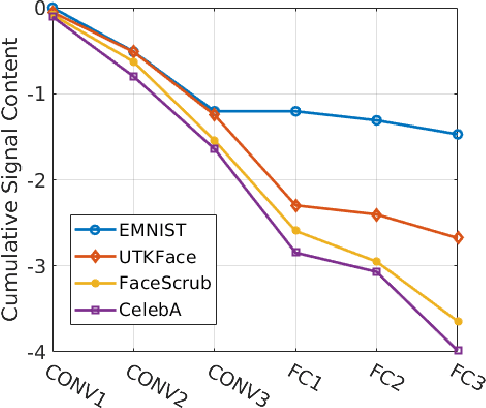
Splitting network computations between the edge device and a server enables low edge-compute inference of neural networks but might expose sensitive information about the test query to the server. To address this problem, existing techniques train the model to minimize information leakage for a given set of sensitive attributes. In practice, however, the test queries might contain attributes that are not foreseen during training. We propose instead an unsupervised obfuscation method to discard the information irrelevant to the main task. We formulate the problem via an information theoretical framework and derive an analytical solution for a given distortion to the model output. In our method, the edge device runs the model up to a split layer determined based on its computational capacity. It then obfuscates the obtained feature vector based on the first layer of the server model by removing the components in the null space as well as the low-energy components of the remaining signal. Our experimental results show that our method outperforms existing techniques in removing the information of the irrelevant attributes and maintaining the accuracy on the target label. We also show that our method reduces the communication cost and incurs only a small computational overhead.
Differential Privacy Meets Maximum-weight Matching
Nov 16, 2020
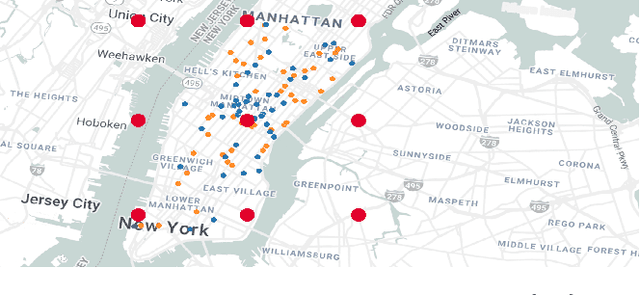
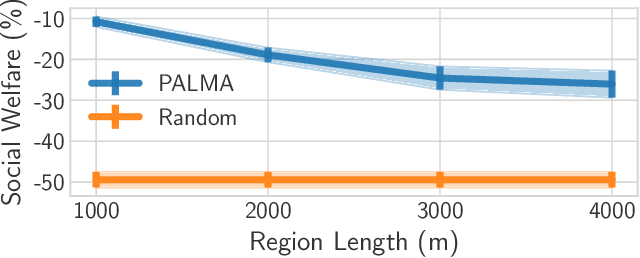
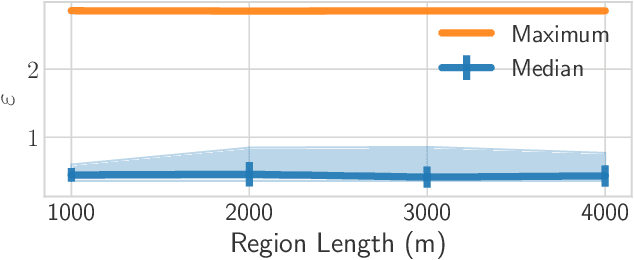
When it comes to large-scale multi-agent systems with a diverse set of agents, traditional differential privacy (DP) mechanisms are ill-matched because they consider a very broad class of adversaries, and they protect all users, independent of their characteristics, by the same guarantee. Achieving a meaningful privacy leads to pronounced reduction in solution quality. Such assumptions are unnecessary in many real-world applications for three key reasons: (i) users might be willing to disclose less sensitive information (e.g., city of residence, but not exact location), (ii) the attacker might posses auxiliary information (e.g., city of residence in a mobility-on-demand system, or reviewer expertise in a paper assignment problem), and (iii) domain characteristics might exclude a subset of solutions (an expert on auctions would not be assigned to review a robotics paper, thus there is no need for indistinguishably between reviewers on different fields). We introduce Piecewise Local Differential Privacy (PLDP), a privacy model designed to protect the utility function in applications where the attacker possesses additional information on the characteristics of the utility space. PLDP enables a high degree of privacy, while being applicable to real-world, unboundedly large settings. Moreover, we propose PALMA, a privacy-preserving heuristic for maximum-weight matching. We evaluate PALMA in a vehicle-passenger matching scenario using real data and demonstrate that it provides strong privacy, $\varepsilon \leq 3$ and a median of $\varepsilon = 0.44$, and high quality matchings ($10.8\%$ worse than the non-private optimal).
Generating Higher-Fidelity Synthetic Datasets with Privacy Guarantees
Mar 02, 2020


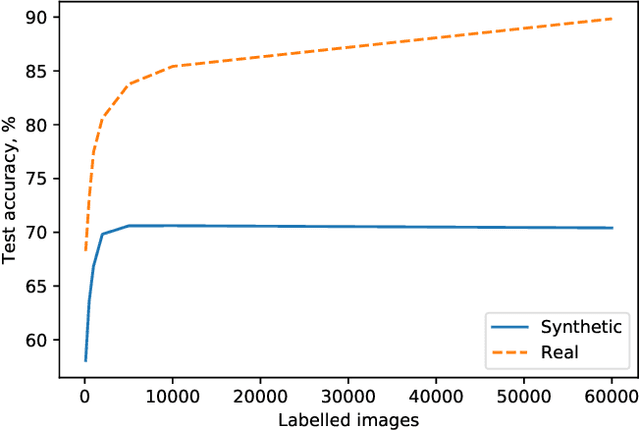
This paper considers the problem of enhancing user privacy in common machine learning development tasks, such as data annotation and inspection, by substituting the real data with samples form a generative adversarial network. We propose employing Bayesian differential privacy as the means to achieve a rigorous theoretical guarantee while providing a better privacy-utility trade-off. We demonstrate experimentally that our approach produces higher-fidelity samples, compared to prior work, allowing to (1) detect more subtle data errors and biases, and (2) reduce the need for real data labelling by achieving high accuracy when training directly on artificial samples.
Federated Learning with Bayesian Differential Privacy
Nov 22, 2019



We consider the problem of reinforcing federated learning with formal privacy guarantees. We propose to employ Bayesian differential privacy, a relaxation of differential privacy for similarly distributed data, to provide sharper privacy loss bounds. We adapt the Bayesian privacy accounting method to the federated setting and suggest multiple improvements for more efficient privacy budgeting at different levels. Our experiments show significant advantage over the state-of-the-art differential privacy bounds for federated learning on image classification tasks, including a medical application, bringing the privacy budget below 1 at the client level, and below 0.1 at the instance level. Lower amounts of noise also benefit the model accuracy and reduce the number of communication rounds.
Federated Generative Privacy
Oct 18, 2019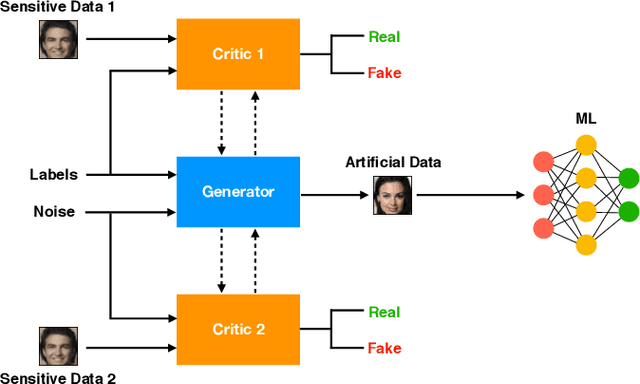



In this paper, we propose FedGP, a framework for privacy-preserving data release in the federated learning setting. We use generative adversarial networks, generator components of which are trained by FedAvg algorithm, to draw privacy-preserving artificial data samples and empirically assess the risk of information disclosure. Our experiments show that FedGP is able to generate labelled data of high quality to successfully train and validate supervised models. Finally, we demonstrate that our approach significantly reduces vulnerability of such models to model inversion attacks.
Improved Accounting for Differentially Private Learning
Jan 28, 2019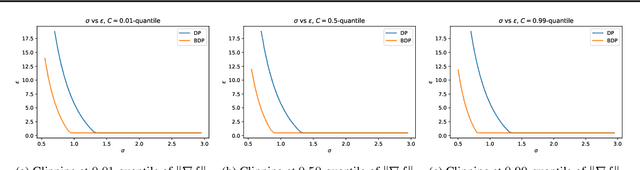
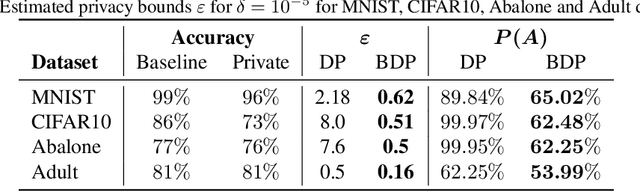
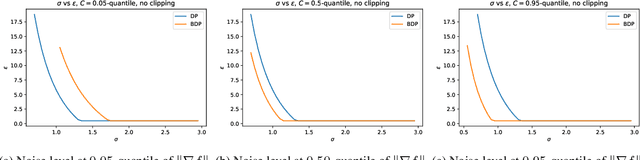
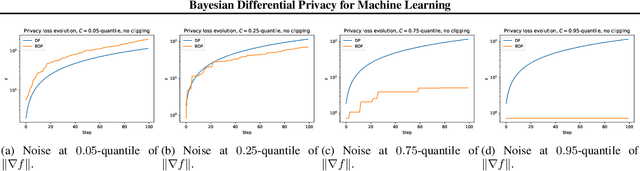
We consider the problem of differential privacy accounting, i.e. estimation of privacy loss bounds, in machine learning in a broad sense. We propose two versions of a generic privacy accountant suitable for a wide range of learning algorithms. Both versions are derived in a simple and principled way using well-known tools from probability theory, such as concentration inequalities. We demonstrate that our privacy accountant is able to achieve state-of-the-art estimates of DP guarantees and can be applied to new areas like variational inference. Moreover, we show that the latter enjoys differential privacy at minor cost.
Generating Artificial Data for Private Deep Learning
Jun 07, 2018

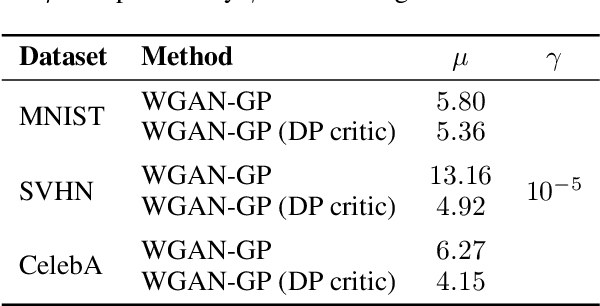

In this paper, we propose generating artificial data that retain statistical properties of real data as the means of providing privacy with respect to the original dataset. We use generative adversarial network to draw privacy-preserving artificial data samples and derive an empirical method to assess the risk of information disclosure in a differential-privacy-like way. Our experiments show that we are able to generate artificial data of high quality and successfully train and validate machine learning models on this data while limiting potential privacy loss.