Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Higher-Fidelity Synthetic Datasets with Privacy Guarantees
Paper and Code
Mar 02, 2020


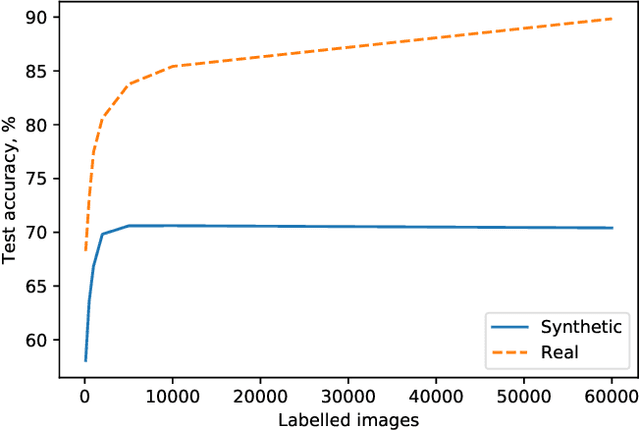
This paper considers the problem of enhancing user privacy in common machine learning development tasks, such as data annotation and inspection, by substituting the real data with samples form a generative adversarial network. We propose employing Bayesian differential privacy as the means to achieve a rigorous theoretical guarantee while providing a better privacy-utility trade-off. We demonstrate experimentally that our approach produces higher-fidelity samples, compared to prior work, allowing to (1) detect more subtle data errors and biases, and (2) reduce the need for real data labelling by achieving high accuracy when training directly on artificial samples.
* 7 pages, 4 figures, 1 table
View paper on