 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFP8 versus INT8 for efficient deep learning inference
Mar 31, 2023Recently, the idea of using FP8 as a number format for neural network training has been floating around the deep learning world. Given that most training is currently conducted with entire networks in FP32, or sometimes FP16 with mixed-precision, the step to having some parts of a network run in FP8 with 8-bit weights is an appealing potential speed-up for the generally costly and time-intensive training procedures in deep learning. A natural question arises regarding what this development means for efficient inference on edge devices. In the efficient inference device world, workloads are frequently executed in INT8. Sometimes going even as low as INT4 when efficiency calls for it. In this whitepaper, we compare the performance for both the FP8 and INT formats for efficient on-device inference. We theoretically show the difference between the INT and FP formats for neural networks and present a plethora of post-training quantization and quantization-aware-training results to show how this theory translates to practice. We also provide a hardware analysis showing that the FP formats are somewhere between 50-180% less efficient in terms of compute in dedicated hardware than the INT format. Based on our research and a read of the research field, we conclude that although the proposed FP8 format could be good for training, the results for inference do not warrant a dedicated implementation of FP8 in favor of INT8 for efficient inference. We show that our results are mostly consistent with previous findings but that important comparisons between the formats have thus far been lacking. Finally, we discuss what happens when FP8-trained networks are converted to INT8 and conclude with a brief discussion on the most efficient way for on-device deployment and an extensive suite of INT8 results for many models.
An Expectation-Maximization Perspective on Federated Learning
Nov 19, 2021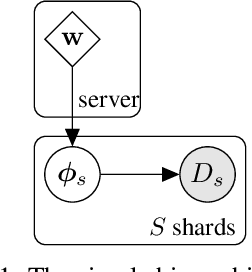
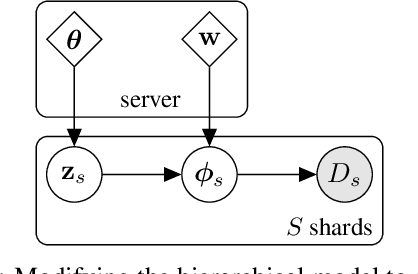

Federated learning describes the distributed training of models across multiple clients while keeping the data private on-device. In this work, we view the server-orchestrated federated learning process as a hierarchical latent variable model where the server provides the parameters of a prior distribution over the client-specific model parameters. We show that with simple Gaussian priors and a hard version of the well known Expectation-Maximization (EM) algorithm, learning in such a model corresponds to FedAvg, the most popular algorithm for the federated learning setting. This perspective on FedAvg unifies several recent works in the field and opens up the possibility for extensions through different choices for the hierarchical model. Based on this view, we further propose a variant of the hierarchical model that employs prior distributions to promote sparsity. By similarly using the hard-EM algorithm for learning, we obtain FedSparse, a procedure that can learn sparse neural networks in the federated learning setting. FedSparse reduces communication costs from client to server and vice-versa, as well as the computational costs for inference with the sparsified network - both of which are of great practical importance in federated learning.
Unsupervised Information Obfuscation for Split Inference of Neural Networks
Apr 23, 2021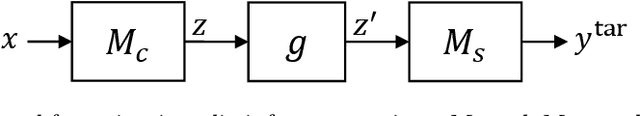
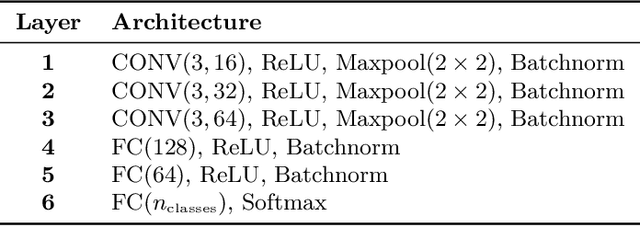

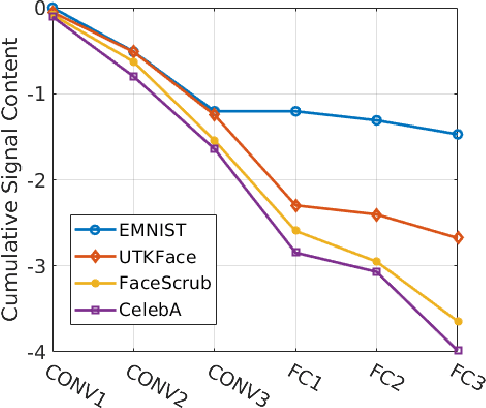
Splitting network computations between the edge device and a server enables low edge-compute inference of neural networks but might expose sensitive information about the test query to the server. To address this problem, existing techniques train the model to minimize information leakage for a given set of sensitive attributes. In practice, however, the test queries might contain attributes that are not foreseen during training. We propose instead an unsupervised obfuscation method to discard the information irrelevant to the main task. We formulate the problem via an information theoretical framework and derive an analytical solution for a given distortion to the model output. In our method, the edge device runs the model up to a split layer determined based on its computational capacity. It then obfuscates the obtained feature vector based on the first layer of the server model by removing the components in the null space as well as the low-energy components of the remaining signal. Our experimental results show that our method outperforms existing techniques in removing the information of the irrelevant attributes and maintaining the accuracy on the target label. We also show that our method reduces the communication cost and incurs only a small computational overhead.
Federated Learning of User Verification Models Without Sharing Embeddings
Apr 18, 2021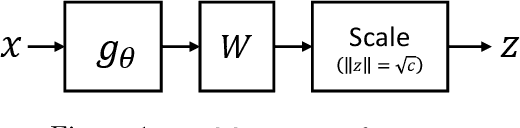
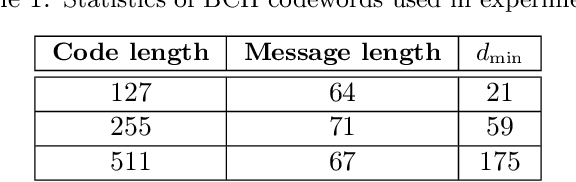
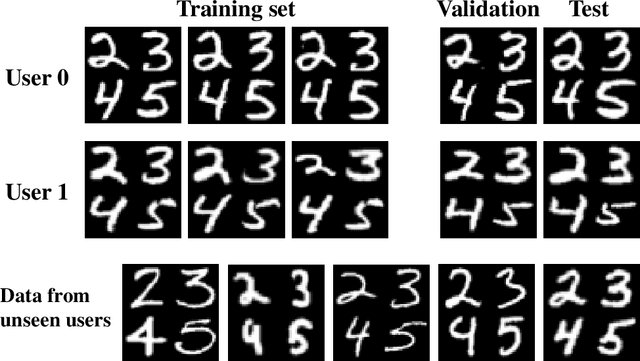
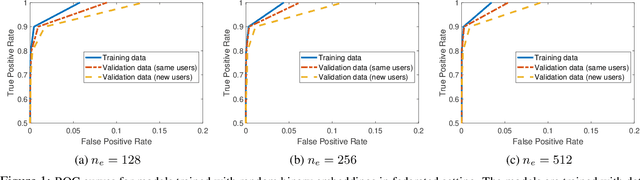
We consider the problem of training User Verification (UV) models in federated setting, where each user has access to the data of only one class and user embeddings cannot be shared with the server or other users. To address this problem, we propose Federated User Verification (FedUV), a framework in which users jointly learn a set of vectors and maximize the correlation of their instance embeddings with a secret linear combination of those vectors. We show that choosing the linear combinations from the codewords of an error-correcting code allows users to collaboratively train the model without revealing their embedding vectors. We present the experimental results for user verification with voice, face, and handwriting data and show that FedUV is on par with existing approaches, while not sharing the embeddings with other users or the server.
Federated Learning of User Authentication Models
Jul 09, 2020
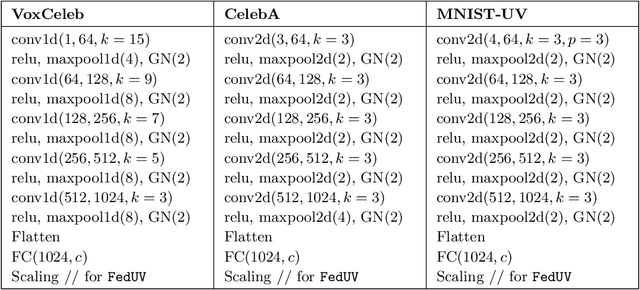
Machine learning-based User Authentication (UA) models have been widely deployed in smart devices. UA models are trained to map input data of different users to highly separable embedding vectors, which are then used to accept or reject new inputs at test time. Training UA models requires having direct access to the raw inputs and embedding vectors of users, both of which are privacy-sensitive information. In this paper, we propose Federated User Authentication (FedUA), a framework for privacy-preserving training of UA models. FedUA adopts federated learning framework to enable a group of users to jointly train a model without sharing the raw inputs. It also allows users to generate their embeddings as random binary vectors, so that, unlike the existing approach of constructing the spread out embeddings by the server, the embedding vectors are kept private as well. We show our method is privacy-preserving, scalable with number of users, and allows new users to be added to training without changing the output layer. Our experimental results on the VoxCeleb dataset for speaker verification shows our method reliably rejects data of unseen users at very high true positive rates.