 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Expectation-Maximization Perspective on Federated Learning
Paper and Code
Nov 19, 2021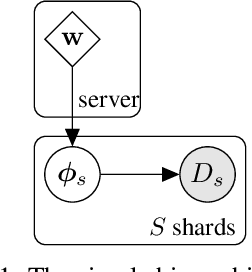
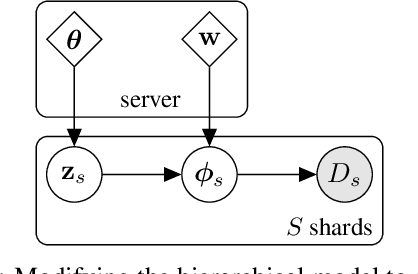

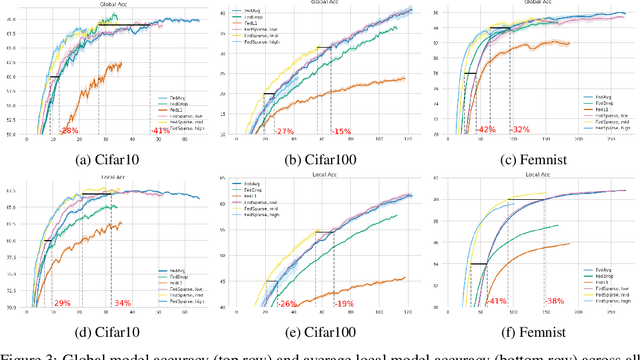
Federated learning describes the distributed training of models across multiple clients while keeping the data private on-device. In this work, we view the server-orchestrated federated learning process as a hierarchical latent variable model where the server provides the parameters of a prior distribution over the client-specific model parameters. We show that with simple Gaussian priors and a hard version of the well known Expectation-Maximization (EM) algorithm, learning in such a model corresponds to FedAvg, the most popular algorithm for the federated learning setting. This perspective on FedAvg unifies several recent works in the field and opens up the possibility for extensions through different choices for the hierarchical model. Based on this view, we further propose a variant of the hierarchical model that employs prior distributions to promote sparsity. By similarly using the hard-EM algorithm for learning, we obtain FedSparse, a procedure that can learn sparse neural networks in the federated learning setting. FedSparse reduces communication costs from client to server and vice-versa, as well as the computational costs for inference with the sparsified network - both of which are of great practical importance in federated learning.