 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fusion Model: Towards a Virtual, Physical and Cognitive Integration and its Principles
May 17, 2023



Virtual Reality (VR), Augmented Reality (AR), Mixed Reality (MR), digital twin, Metaverse and other related digital technologies have attracted much attention in recent years. These new emerging technologies are changing the world significantly. This research introduces a fusion model, i.e. Fusion Universe (FU), where the virtual, physical, and cognitive worlds are merged together. Therefore, it is crucial to establish a set of principles for the fusion model that is compatible with our physical universe laws and principles. This paper investigates several aspects that could affect immersive and interactive experience; and proposes the fundamental principles for Fusion Universe that can integrate physical and virtual world seamlessly.
Task-Adaptive Pseudo Labeling for Transductive Meta-Learning
Apr 21, 2023



Meta-learning performs adaptation through a limited amount of support set, which may cause a sample bias problem. To solve this problem, transductive meta-learning is getting more and more attention, going beyond the conventional inductive learning perspective. This paper proposes so-called task-adaptive pseudo labeling for transductive meta-learning. Specifically, pseudo labels for unlabeled query sets are generated from labeled support sets through label propagation. Pseudo labels enable to adopt the supervised setting as it is and also use the unlabeled query set in the adaptation process. As a result, the proposed method is able to deal with more examples in the adaptation process than inductive ones, which can result in better classification performance of the model. Note that the proposed method is the first approach of applying task adaptation to pseudo labeling. Experiments show that the proposed method outperforms the state-of-the-art (SOTA) technique in 5-way 1-shot few-shot classification.
FP8 versus INT8 for efficient deep learning inference
Mar 31, 2023



Recently, the idea of using FP8 as a number format for neural network training has been floating around the deep learning world. Given that most training is currently conducted with entire networks in FP32, or sometimes FP16 with mixed-precision, the step to having some parts of a network run in FP8 with 8-bit weights is an appealing potential speed-up for the generally costly and time-intensive training procedures in deep learning. A natural question arises regarding what this development means for efficient inference on edge devices. In the efficient inference device world, workloads are frequently executed in INT8. Sometimes going even as low as INT4 when efficiency calls for it. In this whitepaper, we compare the performance for both the FP8 and INT formats for efficient on-device inference. We theoretically show the difference between the INT and FP formats for neural networks and present a plethora of post-training quantization and quantization-aware-training results to show how this theory translates to practice. We also provide a hardware analysis showing that the FP formats are somewhere between 50-180% less efficient in terms of compute in dedicated hardware than the INT format. Based on our research and a read of the research field, we conclude that although the proposed FP8 format could be good for training, the results for inference do not warrant a dedicated implementation of FP8 in favor of INT8 for efficient inference. We show that our results are mostly consistent with previous findings but that important comparisons between the formats have thus far been lacking. Finally, we discuss what happens when FP8-trained networks are converted to INT8 and conclude with a brief discussion on the most efficient way for on-device deployment and an extensive suite of INT8 results for many models.
Contextual Gradient Scaling for Few-Shot Learning
Oct 20, 2021



Model-agnostic meta-learning (MAML) is a well-known optimization-based meta-learning algorithm that works well in various computer vision tasks, e.g., few-shot classification. MAML is to learn an initialization so that a model can adapt to a new task in a few steps. However, since the gradient norm of a classifier (head) is much bigger than those of backbone layers, the model focuses on learning the decision boundary of the classifier with similar representations. Furthermore, gradient norms of high-level layers are small than those of the other layers. So, the backbone of MAML usually learns task-generic features, which results in deteriorated adaptation performance in the inner-loop. To resolve or mitigate this problem, we propose contextual gradient scaling (CxGrad), which scales gradient norms of the backbone to facilitate learning task-specific knowledge in the inner-loop. Since the scaling factors are generated from task-conditioned parameters, gradient norms of the backbone can be scaled in a task-wise fashion. Experimental results show that CxGrad effectively encourages the backbone to learn task-specific knowledge in the inner-loop and improves the performance of MAML up to a significant margin in both same- and cross-domain few-shot classification.
Hierarchical Auxiliary Learning
Jun 03, 2019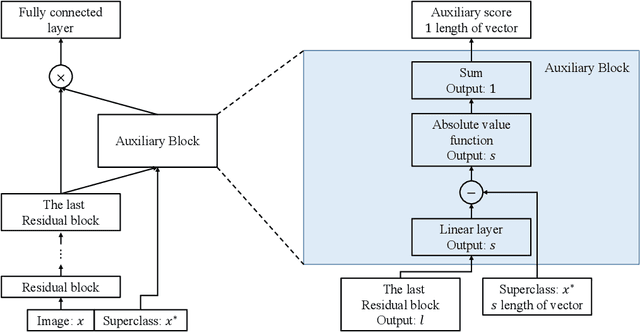
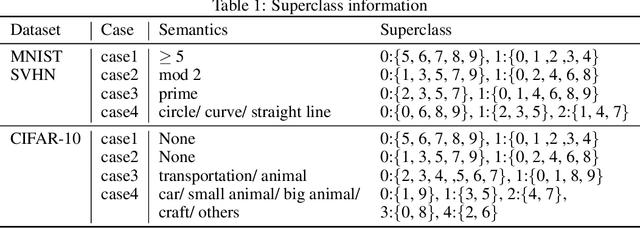

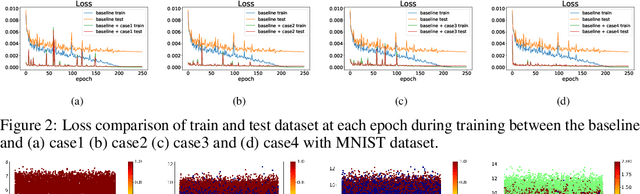
Conventional application of convolutional neural networks (CNNs) for image classification and recognition is based on the assumption that all target classes are equal(i.e., no hierarchy) and exclusive of one another (i.e., no overlap). CNN-based image classifiers built on this assumption, therefore, cannot take into account an innate hierarchy among target classes (e.g., cats and dogs in animal image classification) or additional information that can be easily derived from the data (e.g.,numbers larger than five in the recognition of handwritten digits), thereby resulting in scalability issues when the number of target classes is large. Combining two related but slightly different ideas of hierarchical classification and logical learning by auxiliary inputs, we propose a new learning framework called hierarchical auxiliary learning, which not only address the scalability issues with a large number of classes but also could further reduce the classification/recognition errors with a reasonable number of classes. In the hierarchical auxiliary learning, target classes are semantically or non-semantically grouped into superclasses, which turns the original problem of mapping between an image and its target class into a new problem of mapping between a pair of an image and its superclass and the target class. To take the advantage of superclasses, we introduce an auxiliary block into a neural network, which generates auxiliary scores used as additional information for final classification/recognition; in this paper, we add the auxiliary block between the last residual block and the fully-connected output layer of the ResNet. Experimental results demonstrate that the proposed hierarchical auxiliary learning can reduce classification errors up to 0.56, 1.6 and 3.56 percent with MNIST, SVHN and CIFAR-10 datasets, respectively.
On the Transformation of Latent Space in Autoencoders
Jan 24, 2019

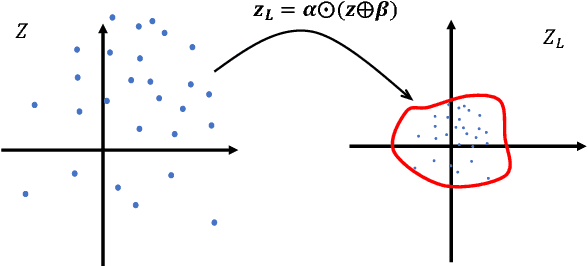

Noting the importance of the latent variables in inference and learning, we propose a novel framework for autoencoders based on the homeomorphic transformation of latent variables --- which could reduce the distance between vectors in the transformed space, while preserving the topological properties of the original space --- and investigate the effect of the transformation in both learning generative models and denoising corrupted data. The results of our experiments show that the proposed model can work as both a generative model and a denoising model with improved performance due to the transformation compared to conventional variational and denoising autoencoders.
XJTLUIndoorLoc: A New Fingerprinting Database for Indoor Localization and Trajectory Estimation Based on Wi-Fi RSS and Geomagnetic Field
Oct 17, 2018
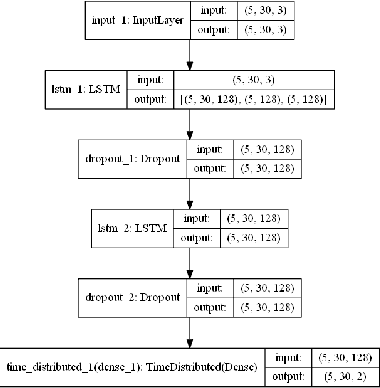
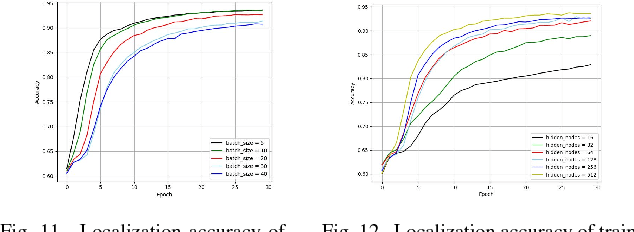
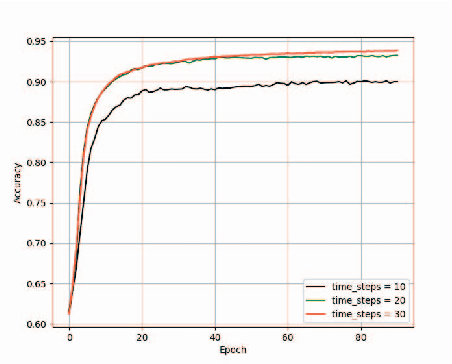
In this paper, we present a new location fingerprinting database comprised of Wi-Fi received signal strength (RSS) and geomagnetic field intensity measured with multiple devices at a multi-floor building in Xi'an Jiatong-Liverpool University, Suzhou, China. We also provide preliminary results of localization and trajectory estimation based on convolutional neural network (CNN) and long short-term memory (LSTM) network with this database. For localization, we map RSS data for a reference point to an image-like, two-dimensional array and then apply CNN which is popular in image and video analysis and recognition. For trajectory estimation, we use a modified random way point model to efficiently generate continuous step traces imitating human walking and train a stacked two-layer LSTM network with the generated data to remember the changing pattern of geomagnetic field intensity against (x,y) coordinates. Experimental results demonstrate the usefulness of our new database and the feasibility of the CNN and LSTM-based localization and trajectory estimation with the database.
A Scalable Deep Neural Network Architecture for Multi-Building and Multi-Floor Indoor Localization Based on Wi-Fi Fingerprinting
Dec 06, 2017



One of the key technologies for future large-scale location-aware services covering a complex of multi-story buildings --- e.g., a big shopping mall and a university campus --- is a scalable indoor localization technique. In this paper, we report the current status of our investigation on the use of deep neural networks (DNNs) for scalable building/floor classification and floor-level position estimation based on Wi-Fi fingerprinting. Exploiting the hierarchical nature of the building/floor estimation and floor-level coordinates estimation of a location, we propose a new DNN architecture consisting of a stacked autoencoder for the reduction of feature space dimension and a feed-forward classifier for multi-label classification of building/floor/location, on which the multi-building and multi-floor indoor localization system based on Wi-Fi fingerprinting is built. Experimental results for the performance of building/floor estimation and floor-level coordinates estimation of a given location demonstrate the feasibility of the proposed DNN-based indoor localization system, which can provide near state-of-the-art performance using a single DNN, for the implementation with lower complexity and energy consumption at mobile devices.
* 9 pages, 6 figures