 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo is Better than One: Efficient Ensemble Defense for Robust and Compact Models
Apr 07, 2025Deep learning-based computer vision systems adopt complex and large architectures to improve performance, yet they face challenges in deployment on resource-constrained mobile and edge devices. To address this issue, model compression techniques such as pruning, quantization, and matrix factorization have been proposed; however, these compressed models are often highly vulnerable to adversarial attacks. We introduce the \textbf{Efficient Ensemble Defense (EED)} technique, which diversifies the compression of a single base model based on different pruning importance scores and enhances ensemble diversity to achieve high adversarial robustness and resource efficiency. EED dynamically determines the number of necessary sub-models during the inference stage, minimizing unnecessary computations while maintaining high robustness. On the CIFAR-10 and SVHN datasets, EED demonstrated state-of-the-art robustness performance compared to existing adversarial pruning techniques, along with an inference speed improvement of up to 1.86 times. This proves that EED is a powerful defense solution in resource-constrained environments.
Task-Adaptive Pseudo Labeling for Transductive Meta-Learning
Apr 21, 2023



Meta-learning performs adaptation through a limited amount of support set, which may cause a sample bias problem. To solve this problem, transductive meta-learning is getting more and more attention, going beyond the conventional inductive learning perspective. This paper proposes so-called task-adaptive pseudo labeling for transductive meta-learning. Specifically, pseudo labels for unlabeled query sets are generated from labeled support sets through label propagation. Pseudo labels enable to adopt the supervised setting as it is and also use the unlabeled query set in the adaptation process. As a result, the proposed method is able to deal with more examples in the adaptation process than inductive ones, which can result in better classification performance of the model. Note that the proposed method is the first approach of applying task adaptation to pseudo labeling. Experiments show that the proposed method outperforms the state-of-the-art (SOTA) technique in 5-way 1-shot few-shot classification.
Optimal Transport-based Identity Matching for Identity-invariant Facial Expression Recognition
Sep 25, 2022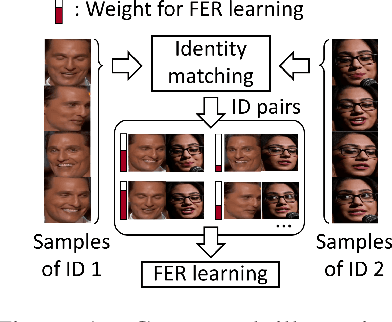
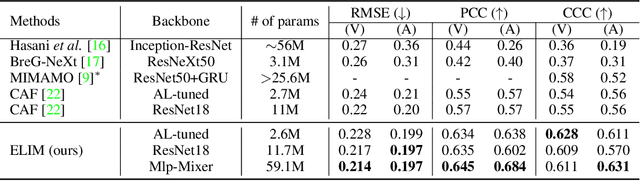
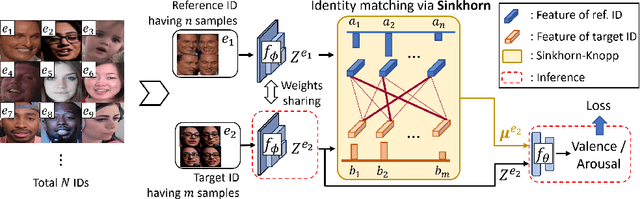
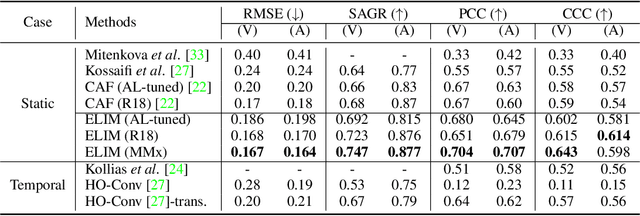
Identity-invariant facial expression recognition (FER) has been one of the challenging computer vision tasks. Since conventional FER schemes do not explicitly address the inter-identity variation of facial expressions, their neural network models still operate depending on facial identity. This paper proposes to quantify the inter-identity variation by utilizing pairs of similar expressions explored through a specific matching process. We formulate the identity matching process as an Optimal Transport (OT) problem. Specifically, to find pairs of similar expressions from different identities, we define the inter-feature similarity as a transportation cost. Then, optimal identity matching to find the optimal flow with minimum transportation cost is performed by Sinkhorn-Knopp iteration. The proposed matching method is not only easy to plug in to other models, but also requires only acceptable computational overhead. Extensive simulations prove that the proposed FER method improves the PCC/CCC performance by up to 10\% or more compared to the runner-up on wild datasets. The source code and software demo are available at https://github.com/kdhht2334/ELIM_FER.
CFA: Coupled-hypersphere-based Feature Adaptation for Target-Oriented Anomaly Localization
Jun 09, 2022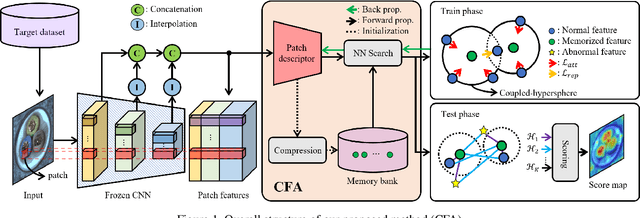
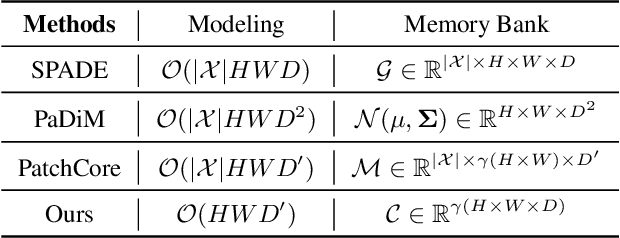
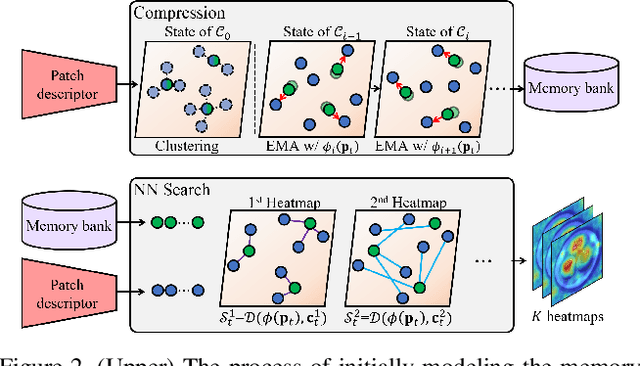
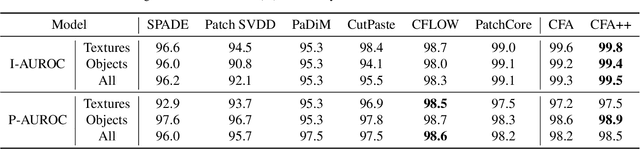
For a long time, anomaly localization has been widely used in industries. Previous studies focused on approximating the distribution of normal features without adaptation to a target dataset. However, since anomaly localization should precisely discriminate normal and abnormal features, the absence of adaptation may make the normality of abnormal features overestimated. Thus, we propose Coupled-hypersphere-based Feature Adaptation (CFA) which accomplishes sophisticated anomaly localization using features adapted to the target dataset. CFA consists of (1) a learnable patch descriptor that learns and embeds target-oriented features and (2) scalable memory bank independent of the size of the target dataset. And, CFA adopts transfer learning to increase the normal feature density so that abnormal features can be clearly distinguished by applying patch descriptor and memory bank to a pre-trained CNN. The proposed method outperforms the previous methods quantitatively and qualitatively. For example, it provides an AUROC score of 99.5% in anomaly detection and 98.5% in anomaly localization of MVTec AD benchmark. In addition, this paper points out the negative effects of biased features of pre-trained CNNs and emphasizes the importance of the adaptation to the target dataset. The code is publicly available at https://github.com/sungwool/CFA_for_anomaly_localization.
Ensemble Knowledge Guided Sub-network Search and Fine-tuning for Filter Pruning
Mar 25, 2022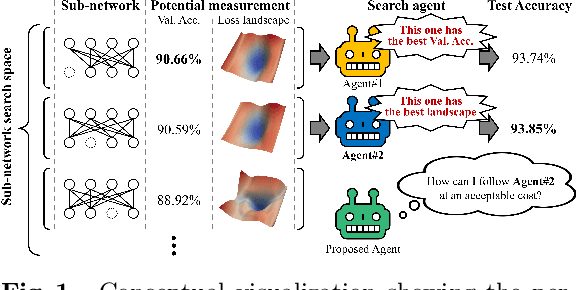
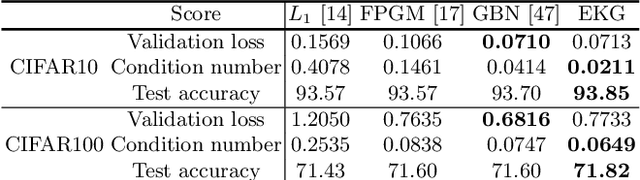
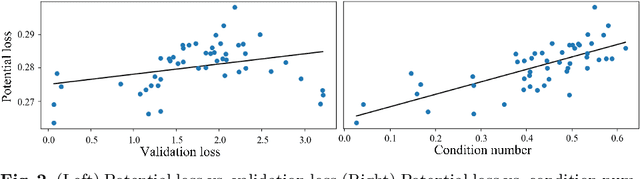
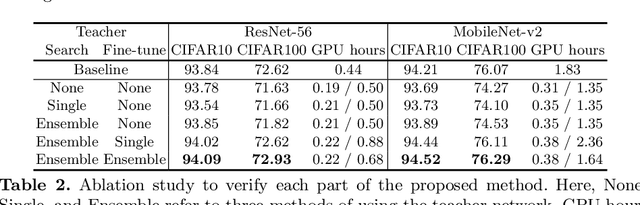
Conventional NAS-based pruning algorithms aim to find the sub-network with the best validation performance. However, validation performance does not successfully represent test performance, i.e., potential performance. Also, although fine-tuning the pruned network to restore the performance drop is an inevitable process, few studies have handled this issue. This paper proposes a novel sub-network search and fine-tuning method that is named Ensemble Knowledge Guidance (EKG). First, we experimentally prove that the fluctuation of the loss landscape is an effective metric to evaluate the potential performance. In order to search a sub-network with the smoothest loss landscape at a low cost, we propose a pseudo-supernet built by an ensemble sub-network knowledge distillation. Next, we propose a novel fine-tuning that re-uses the information of the search phase. We store the interim sub-networks, that is, the by-products of the search phase, and transfer their knowledge into the pruned network. Note that EKG is easy to be plugged-in and computationally efficient. For example, in the case of ResNet-50, about 45% of FLOPS is removed without any performance drop in only 315 GPU hours. The implemented code is available at https://github.com/sseung0703/EKG.
Vision Transformer for Small-Size Datasets
Dec 27, 2021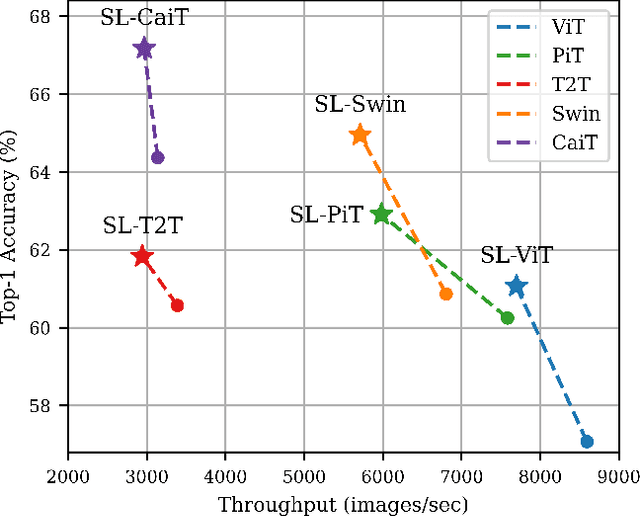
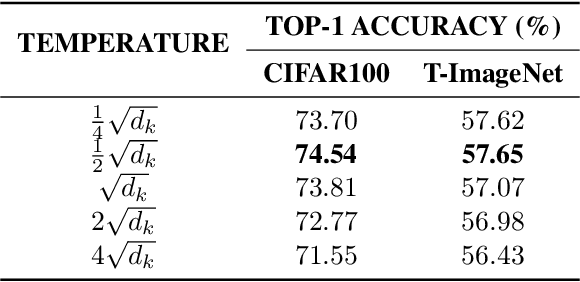

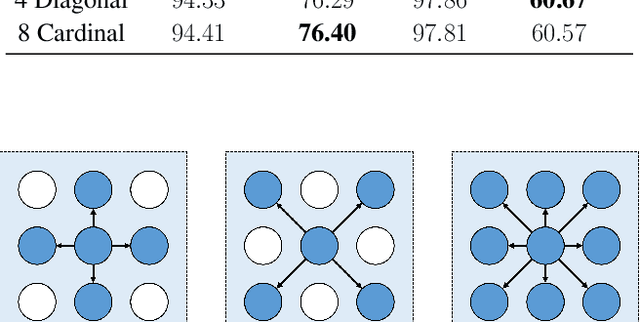
Recently, the Vision Transformer (ViT), which applied the transformer structure to the image classification task, has outperformed convolutional neural networks. However, the high performance of the ViT results from pre-training using a large-size dataset such as JFT-300M, and its dependence on a large dataset is interpreted as due to low locality inductive bias. This paper proposes Shifted Patch Tokenization (SPT) and Locality Self-Attention (LSA), which effectively solve the lack of locality inductive bias and enable it to learn from scratch even on small-size datasets. Moreover, SPT and LSA are generic and effective add-on modules that are easily applicable to various ViTs. Experimental results show that when both SPT and LSA were applied to the ViTs, the performance improved by an average of 2.96% in Tiny-ImageNet, which is a representative small-size dataset. Especially, Swin Transformer achieved an overwhelming performance improvement of 4.08% thanks to the proposed SPT and LSA.
Contextual Gradient Scaling for Few-Shot Learning
Oct 20, 2021



Model-agnostic meta-learning (MAML) is a well-known optimization-based meta-learning algorithm that works well in various computer vision tasks, e.g., few-shot classification. MAML is to learn an initialization so that a model can adapt to a new task in a few steps. However, since the gradient norm of a classifier (head) is much bigger than those of backbone layers, the model focuses on learning the decision boundary of the classifier with similar representations. Furthermore, gradient norms of high-level layers are small than those of the other layers. So, the backbone of MAML usually learns task-generic features, which results in deteriorated adaptation performance in the inner-loop. To resolve or mitigate this problem, we propose contextual gradient scaling (CxGrad), which scales gradient norms of the backbone to facilitate learning task-specific knowledge in the inner-loop. Since the scaling factors are generated from task-conditioned parameters, gradient norms of the backbone can be scaled in a task-wise fashion. Experimental results show that CxGrad effectively encourages the backbone to learn task-specific knowledge in the inner-loop and improves the performance of MAML up to a significant margin in both same- and cross-domain few-shot classification.
Interpretable Embedding Procedure Knowledge Transfer via Stacked Principal Component Analysis and Graph Neural Network
Apr 28, 2021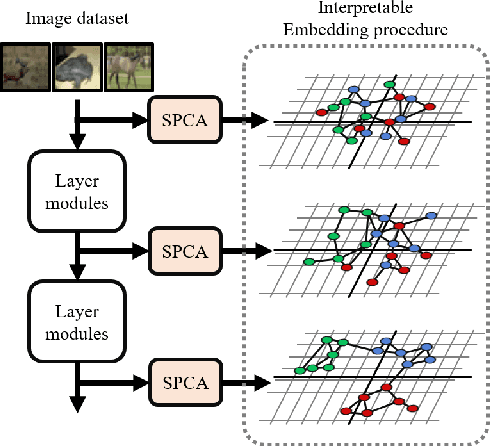

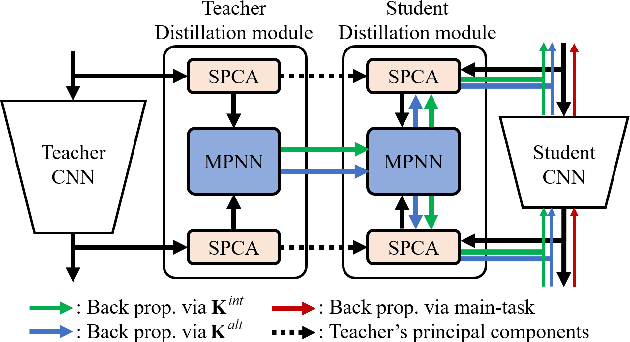
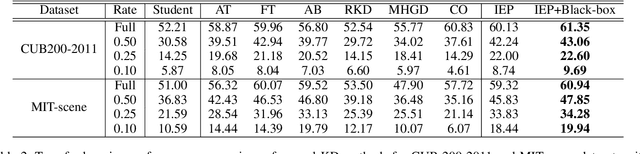
Knowledge distillation (KD) is one of the most useful techniques for light-weight neural networks. Although neural networks have a clear purpose of embedding datasets into the low-dimensional space, the existing knowledge was quite far from this purpose and provided only limited information. We argue that good knowledge should be able to interpret the embedding procedure. This paper proposes a method of generating interpretable embedding procedure (IEP) knowledge based on principal component analysis, and distilling it based on a message passing neural network. Experimental results show that the student network trained by the proposed KD method improves 2.28% in the CIFAR100 dataset, which is higher performance than the state-of-the-art (SOTA) method. We also demonstrate that the embedding procedure knowledge is interpretable via visualization of the proposed KD process. The implemented code is available at https://github.com/sseung0703/IEPKT.
Metric-based Regularization and Temporal Ensemble for Multi-task Learning using Heterogeneous Unsupervised Tasks
Aug 29, 2019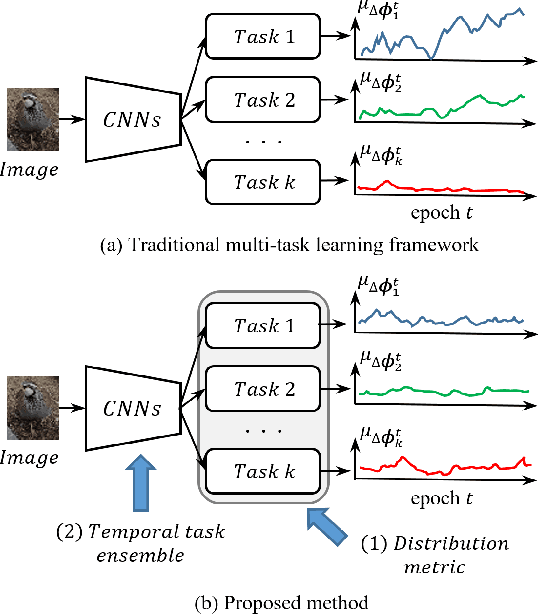

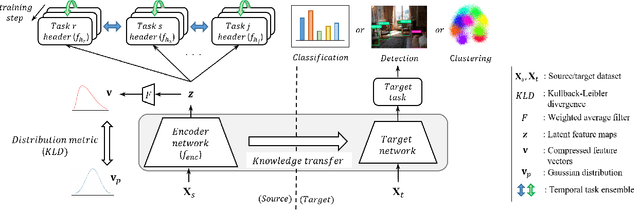
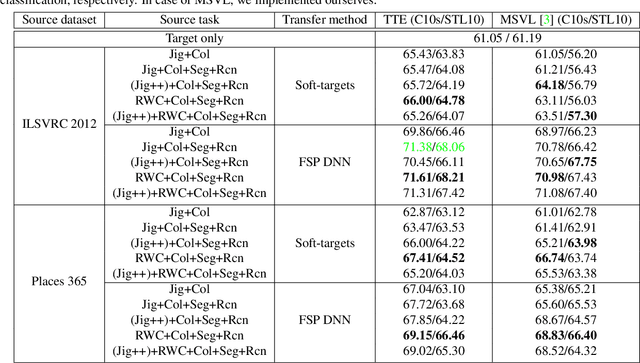
One of the ways to improve the performance of a target task is to learn the transfer of abundant knowledge of a pre-trained network. However, learning of the pre-trained network requires high computation capability and large-scale labeled dataset. To mitigate the burden of large-scale labeling, learning in un/self-supervised manner can be a solution. In addition, using unsupervised multi-task learning, a generalized feature representation can be learned. However, unsupervised multi-task learning can be biased to a specific task. To overcome this problem, we propose the metric-based regularization term and temporal task ensemble (TTE) for multi-task learning. Since these two techniques prevent the entire network from learning in a state deviated to a specific task, it is possible to learn a generalized feature representation that appropriately reflects the characteristics of each task without biasing. Experimental results for three target tasks such as classification, object detection and embedding clustering prove that the TTE-based multi-task framework is more effective than the state-of-the-art (SOTA) method in improving the performance of a target task.
Graph-based Knowledge Distillation by Multi-head Attention Network
Jul 09, 2019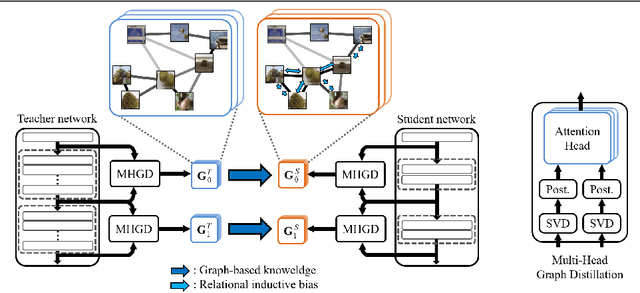
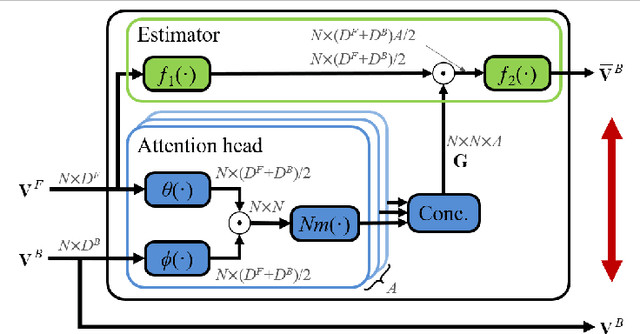

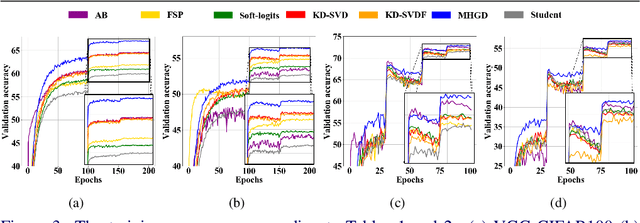
Knowledge distillation (KD) is a technique to derive optimal performance from a small student network (SN) by distilling knowledge of a large teacher network (TN) and transferring the distilled knowledge to the small SN. Since a role of convolutional neural network (CNN) in KD is to embed a dataset so as to perform a given task well, it is very important to acquire knowledge that considers intra-data relations. Conventional KD methods have concentrated on distilling knowledge in data units. To our knowledge, any KD methods for distilling information in dataset units have not yet been proposed. Therefore, this paper proposes a novel method that enables distillation of dataset-based knowledge from the TN using an attention network. The knowledge of the embedding procedure of the TN is distilled to graph by multi-head attention (MHA), and multi-task learning is performed to give relational inductive bias to the SN. The MHA can provide clear information about the source dataset, which can greatly improves the performance of the SN. Experimental results show that the proposed method is 7.05% higher than the SN alone for CIFAR100, which is 2.46% higher than the state-of-the-art.