 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Detection to Mitigation: Addressing Gender Bias in Chinese Texts via Efficient Tuning and Voting-Based Rebalancing
Sep 09, 2025This paper presents our team's solution to Shared Task 7 of NLPCC-2025, which focuses on sentence-level gender bias detection and mitigation in Chinese. The task aims to promote fairness and controllability in natural language generation by automatically detecting, classifying, and mitigating gender bias. To address this challenge, we adopt a fine-tuning approach based on large language models (LLMs), efficiently adapt to the bias detection task via Low-Rank Adaptation (LoRA). In terms of data processing, we construct a more balanced training set to alleviate class imbalance and introduce heterogeneous samples from multiple sources to enhance model generalization. For the detection and classification sub-tasks, we employ a majority voting strategy that integrates outputs from multiple expert models to boost performance. Additionally, to improve bias generation detection and mitigation, we design a multi-temperature sampling mechanism to capture potential variations in bias expression styles. Experimental results demonstrate the effectiveness of our approach in bias detection, classification, and mitigation. Our method ultimately achieves an average score of 47.90%, ranking fourth in the shared task.
Multimodal Emotion Recognition in Conversations: A Survey of Methods, Trends, Challenges and Prospects
May 26, 2025While text-based emotion recognition methods have achieved notable success, real-world dialogue systems often demand a more nuanced emotional understanding than any single modality can offer. Multimodal Emotion Recognition in Conversations (MERC) has thus emerged as a crucial direction for enhancing the naturalness and emotional understanding of human-computer interaction. Its goal is to accurately recognize emotions by integrating information from various modalities such as text, speech, and visual signals. This survey offers a systematic overview of MERC, including its motivations, core tasks, representative methods, and evaluation strategies. We further examine recent trends, highlight key challenges, and outline future directions. As interest in emotionally intelligent systems grows, this survey provides timely guidance for advancing MERC research.
Multi-Scale and Multi-Objective Optimization for Cross-Lingual Aspect-Based Sentiment Analysis
Feb 19, 2025Aspect-based sentiment analysis (ABSA) is a sequence labeling task that has garnered growing research interest in multilingual contexts. However, recent studies lack more robust feature alignment and finer aspect-level alignment. In this paper, we propose a novel framework, Multi-Scale and Multi-Objective optimization (MSMO) for cross-lingual ABSA. During multi-scale alignment, we achieve cross-lingual sentence-level and aspect-level alignment, aligning features of aspect terms in different contextual environments. Specifically, we introduce code-switched bilingual sentences into the language discriminator and consistency training modules to enhance the model's robustness. During multi-objective optimization, we design two optimization objectives: supervised training and consistency training, aiming to enhance cross-lingual semantic alignment. To further improve model performance, we incorporate distilled knowledge of the target language into the model. Results show that MSMO significantly enhances cross-lingual ABSA by achieving state-of-the-art performance across multiple languages and models.
M-ABSA: A Multilingual Dataset for Aspect-Based Sentiment Analysis
Feb 17, 2025
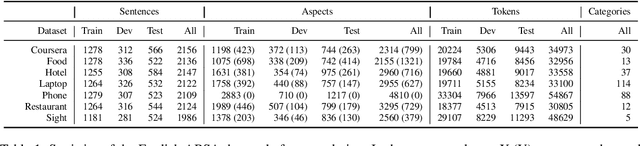
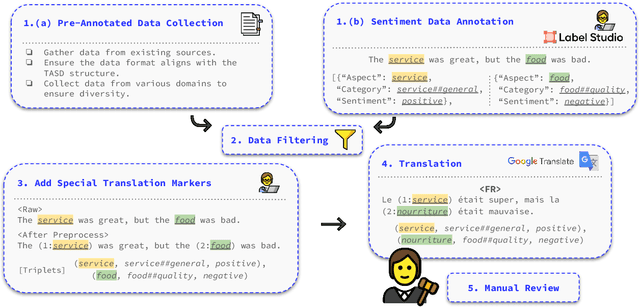
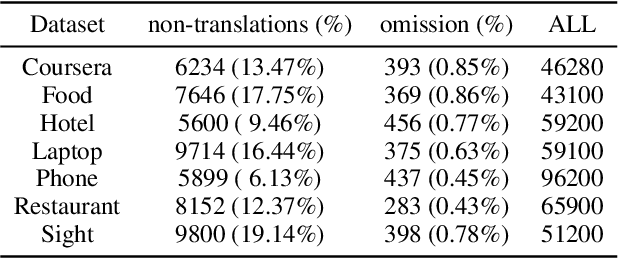
Aspect-based sentiment analysis (ABSA) is a crucial task in information extraction and sentiment analysis, aiming to identify aspects with associated sentiment elements in text. However, existing ABSA datasets are predominantly English-centric, limiting the scope for multilingual evaluation and research. To bridge this gap, we present M-ABSA, a comprehensive dataset spanning 7 domains and 21 languages, making it the most extensive multilingual parallel dataset for ABSA to date. Our primary focus is on triplet extraction, which involves identifying aspect terms, aspect categories, and sentiment polarities. The dataset is constructed through an automatic translation process with human review to ensure quality. We perform extensive experiments using various baselines to assess performance and compatibility on M-ABSA. Our empirical findings highlight that the dataset enables diverse evaluation tasks, such as multilingual and multi-domain transfer learning, and large language model evaluation, underscoring its inclusivity and its potential to drive advancements in multilingual ABSA research.
Evaluating Zero-Shot Multilingual Aspect-Based Sentiment Analysis with Large Language Models
Dec 17, 2024



Aspect-based sentiment analysis (ABSA), a sequence labeling task, has attracted increasing attention in multilingual contexts. While previous research has focused largely on fine-tuning or training models specifically for ABSA, we evaluate large language models (LLMs) under zero-shot conditions to explore their potential to tackle this challenge with minimal task-specific adaptation. We conduct a comprehensive empirical evaluation of a series of LLMs on multilingual ABSA tasks, investigating various prompting strategies, including vanilla zero-shot, chain-of-thought (CoT), self-improvement, self-debate, and self-consistency, across nine different models. Results indicate that while LLMs show promise in handling multilingual ABSA, they generally fall short of fine-tuned, task-specific models. Notably, simpler zero-shot prompts often outperform more complex strategies, especially in high-resource languages like English. These findings underscore the need for further refinement of LLM-based approaches to effectively address ABSA task across diverse languages.
Prompt-enhanced Network for Hateful Meme Classification
Nov 12, 2024



The dynamic expansion of social media has led to an inundation of hateful memes on media platforms, accentuating the growing need for efficient identification and removal. Acknowledging the constraints of conventional multimodal hateful meme classification, which heavily depends on external knowledge and poses the risk of including irrelevant or redundant content, we developed Pen -- a prompt-enhanced network framework based on the prompt learning approach. Specifically, after constructing the sequence through the prompt method and encoding it with a language model, we performed region information global extraction on the encoded sequence for multi-view perception. By capturing global information about inference instances and demonstrations, Pen facilitates category selection by fully leveraging sequence information. This approach significantly improves model classification accuracy. Additionally, to bolster the model's reasoning capabilities in the feature space, we introduced prompt-aware contrastive learning into the framework to improve the quality of sample feature distributions. Through extensive ablation experiments on two public datasets, we evaluate the effectiveness of the Pen framework, concurrently comparing it with state-of-the-art model baselines. Our research findings highlight that Pen surpasses manual prompt methods, showcasing superior generalization and classification accuracy in hateful meme classification tasks. Our code is available at https://github.com/juszzi/Pen.
A Fusion Model: Towards a Virtual, Physical and Cognitive Integration and its Principles
May 17, 2023



Virtual Reality (VR), Augmented Reality (AR), Mixed Reality (MR), digital twin, Metaverse and other related digital technologies have attracted much attention in recent years. These new emerging technologies are changing the world significantly. This research introduces a fusion model, i.e. Fusion Universe (FU), where the virtual, physical, and cognitive worlds are merged together. Therefore, it is crucial to establish a set of principles for the fusion model that is compatible with our physical universe laws and principles. This paper investigates several aspects that could affect immersive and interactive experience; and proposes the fundamental principles for Fusion Universe that can integrate physical and virtual world seamlessly.
Targeted aspect based multimodal sentiment analysis:an attention capsule extraction and multi-head fusion network
Mar 13, 2021
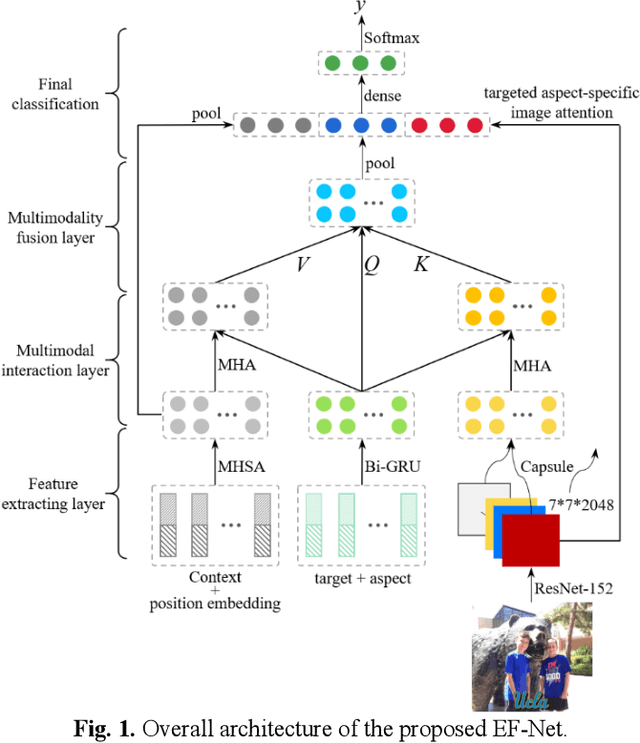
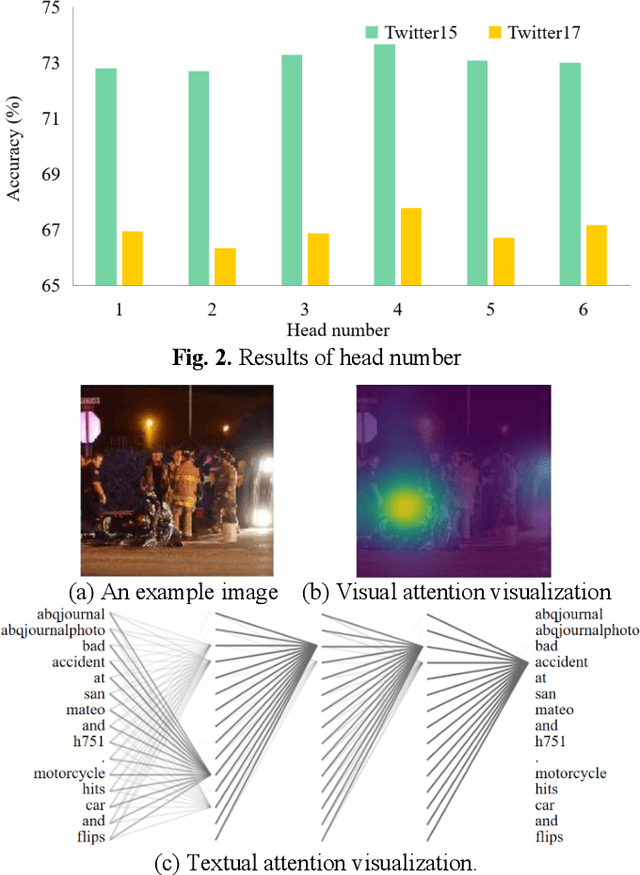
Multimodal sentiment analysis has currently identified its significance in a variety of domains. For the purpose of sentiment analysis, different aspects of distinguishing modalities, which correspond to one target, are processed and analyzed. In this work, we propose the targeted aspect-based multimodal sentiment analysis (TABMSA) for the first time. Furthermore, an attention capsule extraction and multi-head fusion network (EF-Net) on the task of TABMSA is devised. The multi-head attention (MHA) based network and the ResNet-152 are employed to deal with texts and images, respectively. The integration of MHA and capsule network aims to capture the interaction among the multimodal inputs. In addition to the targeted aspect, the information from the context and the image is also incorporated for sentiment delivered. We evaluate the proposed model on two manually annotated datasets. the experimental results demonstrate the effectiveness of our proposed model for this new task.