 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker Diaphragm Excursion Prediction: deep attention and online adaptation
May 11, 2023Speaker protection algorithm is to leverage the playback signal properties to prevent over excursion while maintaining maximum loudness, especially for the mobile phone with tiny loudspeakers. This paper proposes efficient DL solutions to accurately model and predict the nonlinear excursion, which is challenging for conventional solutions. Firstly, we build the experiment and pre-processing pipeline, where the feedback current and voltage are sampled as input, and laser is employed to measure the excursion as ground truth. Secondly, one FFTNet model is proposed to explore the dominant low-frequency and other unknown harmonics, and compares to a baseline ConvNet model. In addition, BN re-estimation is designed to explore the online adaptation; and INT8 quantization based on AI Model efficiency toolkit (AIMET\footnote{AIMET is a product of Qualcomm Innovation Center, Inc.}) is applied to further reduce the complexity. The proposed algorithm is verified in two speakers and 3 typical deployment scenarios, and $>$99\% residual DC is less than 0.1 mm, much better than traditional solutions.
FP8 versus INT8 for efficient deep learning inference
Mar 31, 2023



Recently, the idea of using FP8 as a number format for neural network training has been floating around the deep learning world. Given that most training is currently conducted with entire networks in FP32, or sometimes FP16 with mixed-precision, the step to having some parts of a network run in FP8 with 8-bit weights is an appealing potential speed-up for the generally costly and time-intensive training procedures in deep learning. A natural question arises regarding what this development means for efficient inference on edge devices. In the efficient inference device world, workloads are frequently executed in INT8. Sometimes going even as low as INT4 when efficiency calls for it. In this whitepaper, we compare the performance for both the FP8 and INT formats for efficient on-device inference. We theoretically show the difference between the INT and FP formats for neural networks and present a plethora of post-training quantization and quantization-aware-training results to show how this theory translates to practice. We also provide a hardware analysis showing that the FP formats are somewhere between 50-180% less efficient in terms of compute in dedicated hardware than the INT format. Based on our research and a read of the research field, we conclude that although the proposed FP8 format could be good for training, the results for inference do not warrant a dedicated implementation of FP8 in favor of INT8 for efficient inference. We show that our results are mostly consistent with previous findings but that important comparisons between the formats have thus far been lacking. Finally, we discuss what happens when FP8-trained networks are converted to INT8 and conclude with a brief discussion on the most efficient way for on-device deployment and an extensive suite of INT8 results for many models.
Hand gesture recognition using 802.11ad mmWave sensor in the mobile device
Nov 14, 2022



We explore the feasibility of AI assisted hand-gesture recognition using 802.11ad 60GHz (mmWave) technology in smartphones. Range-Doppler information (RDI) is obtained by using pulse Doppler radar for gesture recognition. We built a prototype system, where radar sensing and WLAN communication waveform can coexist by time-division duplex (TDD), to demonstrate the real-time hand-gesture inference. It can gather sensing data and predict gestures within 100 milliseconds. First, we build the pipeline for the real-time feature processing, which is robust to occasional frame drops in the data stream. RDI sequence restoration is implemented to handle the frame dropping in the continuous data stream, and also applied to data augmentation. Second, different gestures RDI are analyzed, where finger and hand motions can clearly show distinctive features. Third, five typical gestures (swipe, palm-holding, pull-push, finger-sliding and noise) are experimented with, and a classification framework is explored to segment the different gestures in the continuous gesture sequence with arbitrary inputs. We evaluate our architecture on a large multi-person dataset and report > 95% accuracy with one CNN + LSTM model. Further, a pure CNN model is developed to fit to on-device implementation, which minimizes the inference latency, power consumption and computation cost. And the accuracy of this CNN model is more than 93% with only 2.29K parameters.
* 6 pages, 12 figures
FP8 Quantization: The Power of the Exponent
Aug 19, 2022
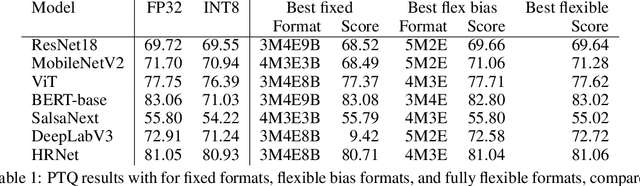
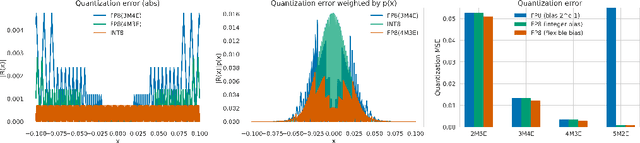
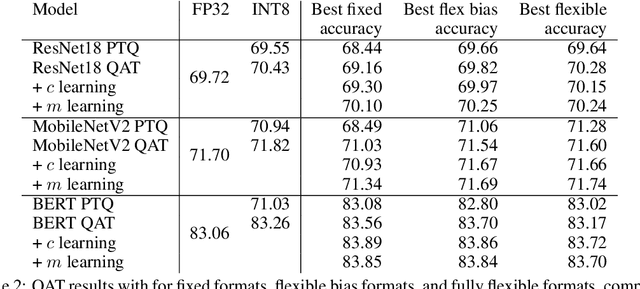
When quantizing neural networks for efficient inference, low-bit integers are the go-to format for efficiency. However, low-bit floating point numbers have an extra degree of freedom, assigning some bits to work on an exponential scale instead. This paper in-depth investigates this benefit of the floating point format for neural network inference. We detail the choices that can be made for the FP8 format, including the important choice of the number of bits for the mantissa and exponent, and show analytically in which settings these choices give better performance. Then we show how these findings translate to real networks, provide an efficient implementation for FP8 simulation, and a new algorithm that enables the learning of both the scale parameters and the number of exponent bits in the FP8 format. Our chief conclusion is that when doing post-training quantization for a wide range of networks, the FP8 format is better than INT8 in terms of accuracy, and the choice of the number of exponent bits is driven by the severity of outliers in the network. We also conduct experiments with quantization-aware training where the difference in formats disappears as the network is trained to reduce the effect of outliers.