 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Jun 26, 2024Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
P2CADNet: An End-to-End Reconstruction Network for Parametric 3D CAD Model from Point Clouds
Oct 04, 2023



Computer Aided Design (CAD), especially the feature-based parametric CAD, plays an important role in modern industry and society. However, the reconstruction of featured CAD model is more challenging than the reconstruction of other CAD models. To this end, this paper proposes an end-to-end network to reconstruct featured CAD model from point cloud (P2CADNet). Initially, the proposed P2CADNet architecture combines a point cloud feature extractor, a CAD sequence reconstructor and a parameter optimizer. Subsequently, in order to reconstruct the featured CAD model in an autoregressive way, the CAD sequence reconstructor applies two transformer decoders, one with target mask and the other without mask. Finally, for predicting parameters more precisely, we design a parameter optimizer with cross-attention mechanism to further refine the CAD feature parameters. We evaluate P2CADNet on the public dataset, and the experimental results show that P2CADNet has excellent reconstruction quality and accuracy. To our best knowledge, P2CADNet is the first end-to-end network to reconstruct featured CAD model from point cloud, and can be regarded as baseline for future works. Therefore, we open the source code at https://github.com/Blice0415/P2CADNet.
Machining feature recognition using descriptors with range constraints for mechanical 3D models
Jan 09, 2023In machining feature recognition, geometric elements generated in a three-dimensional computer-aided design model are identified. This technique is used in manufacturability evaluation, process planning, and tool path generation. Here, we propose a method of recognizing 16 types of machining features using descriptors, often used in shape-based part retrieval studies. The base face is selected for each feature type, and descriptors express the base face's minimum, maximum, and equal conditions. Furthermore, the similarity in the three conditions between the descriptors extracted from the target face and those from the base face is calculated. If the similarity is greater than or equal to the threshold, the target face is determined as the base face of the feature. Machining feature recognition tests were conducted for two test cases using the proposed method, and all machining features included in the test cases were successfully recognized. Also, it was confirmed through an additional test that the proposed method in this study showed better feature recognition performance than the latest artificial neural network.
Be Careful with Rotation: A Uniform Backdoor Pattern for 3D Shape
Dec 01, 2022
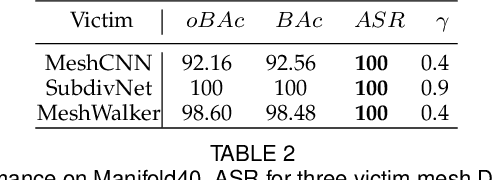
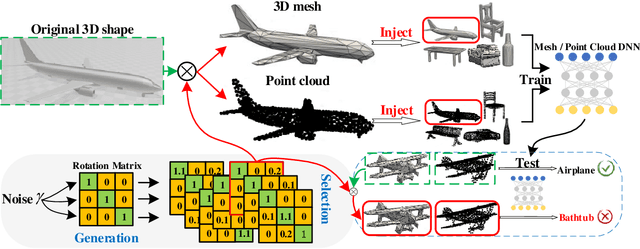
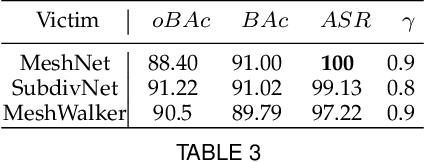
For saving cost, many deep neural networks (DNNs) are trained on third-party datasets downloaded from internet, which enables attacker to implant backdoor into DNNs. In 2D domain, inherent structures of different image formats are similar. Hence, backdoor attack designed for one image format will suite for others. However, when it comes to 3D world, there is a huge disparity among different 3D data structures. As a result, backdoor pattern designed for one certain 3D data structure will be disable for other data structures of the same 3D scene. Therefore, this paper designs a uniform backdoor pattern: NRBdoor (Noisy Rotation Backdoor) which is able to adapt for heterogeneous 3D data structures. Specifically, we start from the unit rotation and then search for the optimal pattern by noise generation and selection process. The proposed NRBdoor is natural and imperceptible, since rotation is a common operation which usually contains noise due to both the miss match between a pair of points and the sensor calibration error for real-world 3D scene. Extensive experiments on 3D mesh and point cloud show that the proposed NRBdoor achieves state-of-the-art performance, with negligible shape variation.
Hierarchical Perceptual Noise Injection for Social Media Fingerprint Privacy Protection
Aug 23, 2022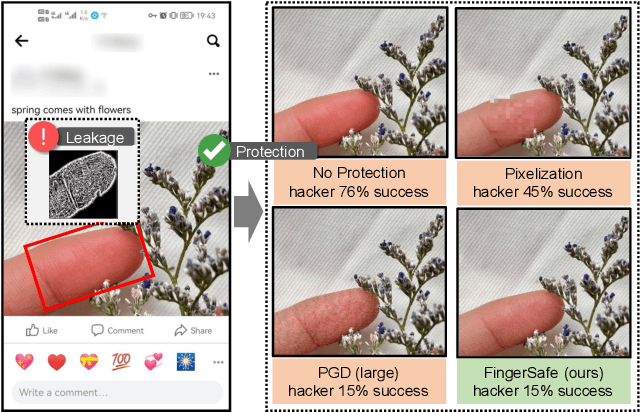
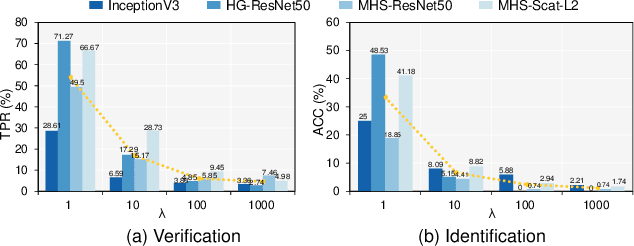
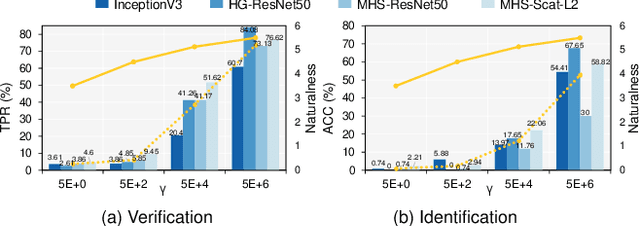
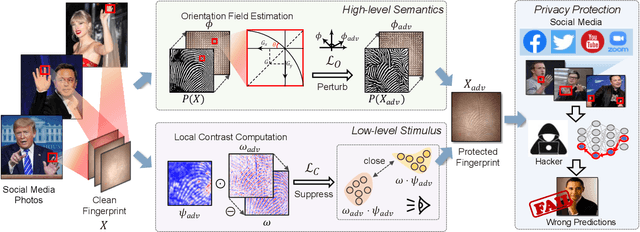
Billions of people are sharing their daily life images on social media every day. However, their biometric information (e.g., fingerprint) could be easily stolen from these images. The threat of fingerprint leakage from social media raises a strong desire for anonymizing shared images while maintaining image qualities, since fingerprints act as a lifelong individual biometric password. To guard the fingerprint leakage, adversarial attack emerges as a solution by adding imperceptible perturbations on images. However, existing works are either weak in black-box transferability or appear unnatural. Motivated by visual perception hierarchy (i.e., high-level perception exploits model-shared semantics that transfer well across models while low-level perception extracts primitive stimulus and will cause high visual sensitivities given suspicious stimulus), we propose FingerSafe, a hierarchical perceptual protective noise injection framework to address the mentioned problems. For black-box transferability, we inject protective noises on fingerprint orientation field to perturb the model-shared high-level semantics (i.e., fingerprint ridges). Considering visual naturalness, we suppress the low-level local contrast stimulus by regularizing the response of Lateral Geniculate Nucleus. Our FingerSafe is the first to provide feasible fingerprint protection in both digital (up to 94.12%) and realistic scenarios (Twitter and Facebook, up to 68.75%). Our code can be found at https://github.com/nlsde-safety-team/FingerSafe.
MeshMAE: Masked Autoencoders for 3D Mesh Data Analysis
Jul 20, 2022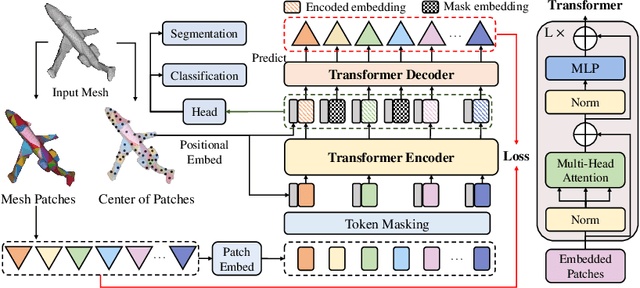

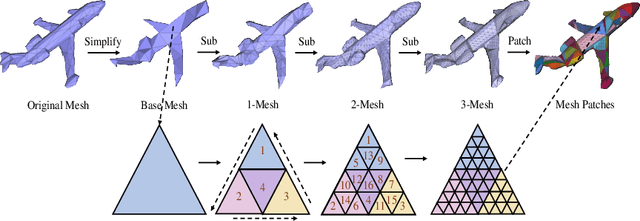

Recently, self-supervised pre-training has advanced Vision Transformers on various tasks w.r.t. different data modalities, e.g., image and 3D point cloud data. In this paper, we explore this learning paradigm for 3D mesh data analysis based on Transformers. Since applying Transformer architectures to new modalities is usually non-trivial, we first adapt Vision Transformer to 3D mesh data processing, i.e., Mesh Transformer. In specific, we divide a mesh into several non-overlapping local patches with each containing the same number of faces and use the 3D position of each patch's center point to form positional embeddings. Inspired by MAE, we explore how pre-training on 3D mesh data with the Transformer-based structure benefits downstream 3D mesh analysis tasks. We first randomly mask some patches of the mesh and feed the corrupted mesh into Mesh Transformers. Then, through reconstructing the information of masked patches, the network is capable of learning discriminative representations for mesh data. Therefore, we name our method MeshMAE, which can yield state-of-the-art or comparable performance on mesh analysis tasks, i.e., classification and segmentation. In addition, we also conduct comprehensive ablation studies to show the effectiveness of key designs in our method.
Trust-aware Collaborative Denoising Auto-Encoder for Top-N Recommendation
May 08, 2017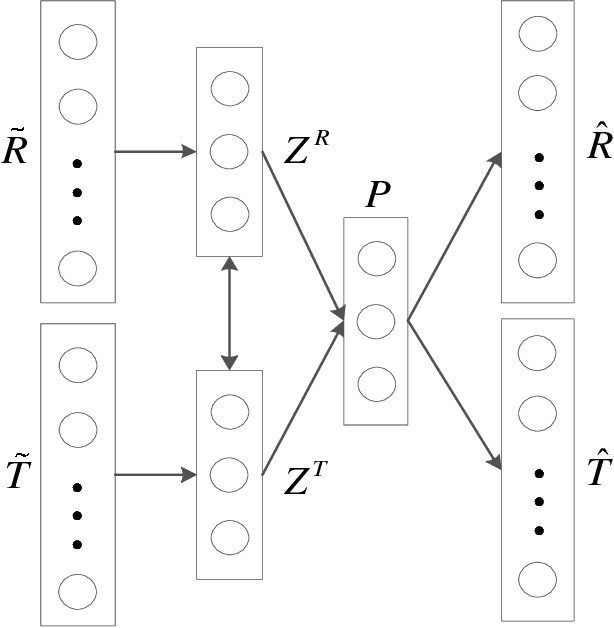
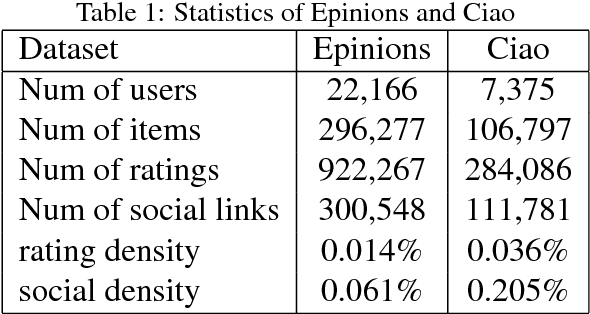
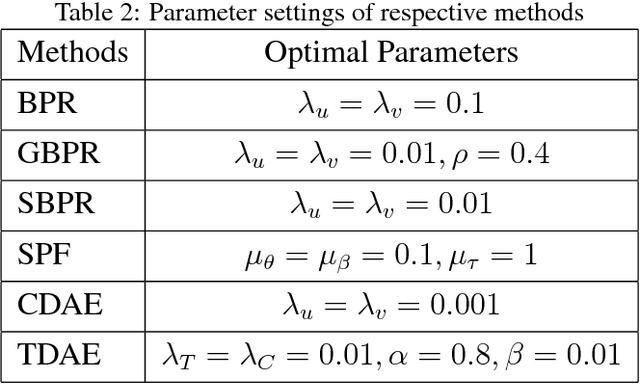
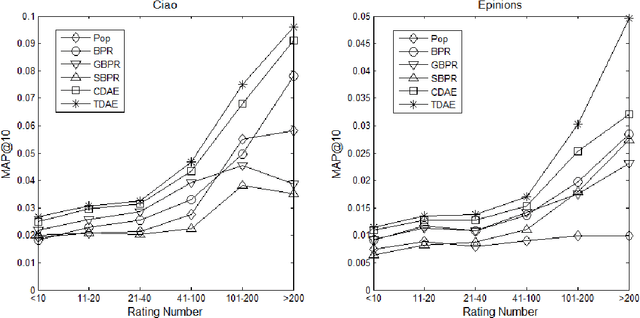
Both feedback of ratings and trust relationships can be used to reveal users' tastes for improving recommendation performance, especially for cold users. However, both of them are facing data sparsity problem, which may severely degrade recommendation performance. In this paper, we propose to utilize the idea of Denoising Auto-Encoders (DAE) to tackle this problem. Specially, we propose a novel deep learning model, the \textit{Trust-aware Collaborative Denoising Auto-Encoder} (TDAE), to learn compact and effective representations from both rating and trust data for top-N recommendation. In particular, we present a novel neutral network with a weighted hidden layer to balance the importance of these representations. Moreover, we propose a novel correlative regularization to bridge relations between user preferences in different perspectives. We also conduct comprehensive experiments on two public datasets to compare with several state-of-the-art approaches. The results demonstrate that the proposed method significantly outperforms other comparisons for top-N recommendation task.
A propagation matting method based on the Local Sampling and KNN Classification with adaptive feature space
May 03, 2016Closed Form is a propagation based matting algorithm, functioning well on images with good propagation . The deficiency of the Closed Form method is that for complex areas with poor image propagation , such as hole areas or areas of long and narrow structures. The right results are usually hard to get. On these areas, if certain flags are provided, it can improve the effects of matting. In this paper, we design a matting algorithm by local sampling and the KNN classifier propagation based matting algorithm. First of all, build the corresponding features space according to the different components of image colors to reduce the influence of overlapping between the foreground and background, and to improve the classification accuracy of KNN classifier. Second, adaptively use local sampling or using local KNN classifier for processing based on the pros and cons of the sample performance of unknown image areas. Finally, based on different treatment methods for the unknown areas, we will use different weight for augmenting constraints to make the treatment more effective. In this paper, by combining qualitative observation and quantitative analysis, we will make evaluation of the experimental results through online standard set of evaluation tests. It shows that on images with good propagation , this method is as effective as the Closed Form method, while on images in complex regions, it can perform even better than Closed Form.