 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCATSeg: A Tooth Center-Wise Attention Network for 3D Dental Model Semantic Segmentation
Mar 17, 2026Accurate semantic segmentation of 3D dental models is essential for digital dentistry applications such as orthodontics and dental implants. However, due to complex tooth arrangements and similarities in shape among adjacent teeth, existing methods struggle with accurate segmentation, because they often focus on local geometry while neglecting global contextual information. To address this, we propose TCATSeg, a novel framework that combines local geometric features with global semantic context. We introduce a set of sparse yet physically meaningful superpoints to capture global semantic relationships and enhance segmentation accuracy. Additionally, we present a new dataset of 400 dental models, including pre-orthodontic samples, to evaluate the generalization of our method. Extensive experiments demonstrate that TCATSeg outperforms state-of-the-art approaches.
Automatic Tooth Arrangement with Joint Features of Point and Mesh Representations via Diffusion Probabilistic Models
Dec 23, 2023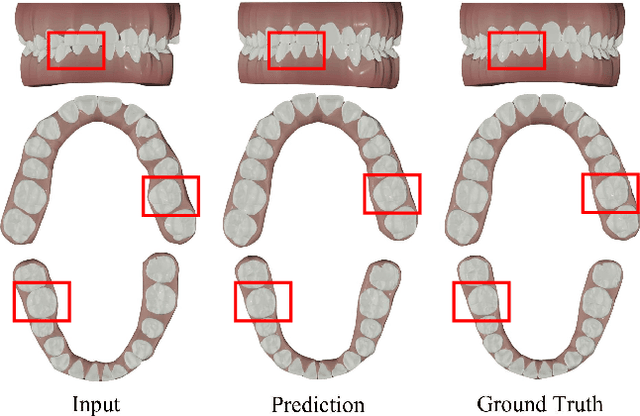
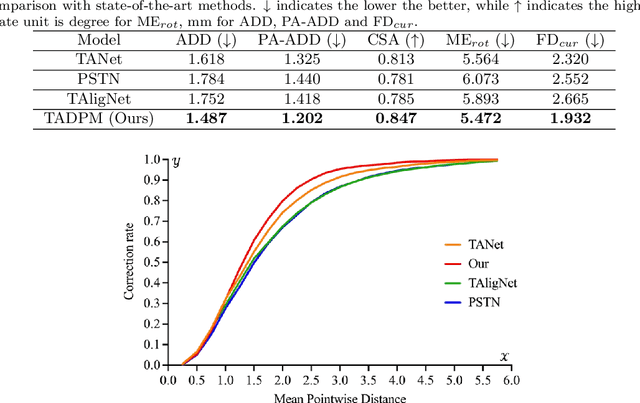

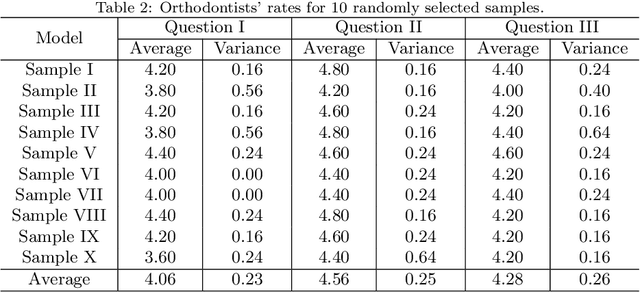
Tooth arrangement is a crucial step in orthodontics treatment, in which aligning teeth could improve overall well-being, enhance facial aesthetics, and boost self-confidence. To improve the efficiency of tooth arrangement and minimize errors associated with unreasonable designs by inexperienced practitioners, some deep learning-based tooth arrangement methods have been proposed. Currently, most existing approaches employ MLPs to model the nonlinear relationship between tooth features and transformation matrices to achieve tooth arrangement automatically. However, the limited datasets (which to our knowledge, have not been made public) collected from clinical practice constrain the applicability of existing methods, making them inadequate for addressing diverse malocclusion issues. To address this challenge, we propose a general tooth arrangement neural network based on the diffusion probabilistic model. Conditioned on the features extracted from the dental model, the diffusion probabilistic model can learn the distribution of teeth transformation matrices from malocclusion to normal occlusion by gradually denoising from a random variable, thus more adeptly managing real orthodontic data. To take full advantage of effective features, we exploit both mesh and point cloud representations by designing different encoding networks to extract the tooth (local) and jaw (global) features, respectively. In addition to traditional metrics ADD, PA-ADD, CSA, and ME_{rot}, we propose a new evaluation metric based on dental arch curves to judge whether the generated teeth meet the individual normal occlusion. Experimental results demonstrate that our proposed method achieves state-of-the-art tooth alignment results and satisfactory occlusal relationships between dental arches. We will publish the code and dataset.
MeshMAE: Masked Autoencoders for 3D Mesh Data Analysis
Jul 20, 2022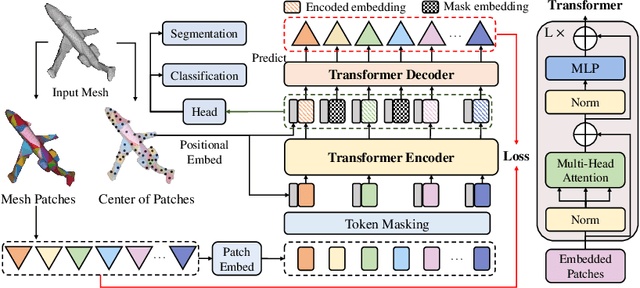

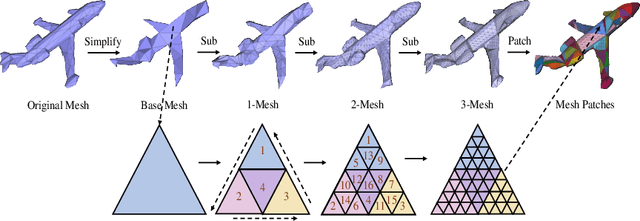

Recently, self-supervised pre-training has advanced Vision Transformers on various tasks w.r.t. different data modalities, e.g., image and 3D point cloud data. In this paper, we explore this learning paradigm for 3D mesh data analysis based on Transformers. Since applying Transformer architectures to new modalities is usually non-trivial, we first adapt Vision Transformer to 3D mesh data processing, i.e., Mesh Transformer. In specific, we divide a mesh into several non-overlapping local patches with each containing the same number of faces and use the 3D position of each patch's center point to form positional embeddings. Inspired by MAE, we explore how pre-training on 3D mesh data with the Transformer-based structure benefits downstream 3D mesh analysis tasks. We first randomly mask some patches of the mesh and feed the corrupted mesh into Mesh Transformers. Then, through reconstructing the information of masked patches, the network is capable of learning discriminative representations for mesh data. Therefore, we name our method MeshMAE, which can yield state-of-the-art or comparable performance on mesh analysis tasks, i.e., classification and segmentation. In addition, we also conduct comprehensive ablation studies to show the effectiveness of key designs in our method.