 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCATSeg: A Tooth Center-Wise Attention Network for 3D Dental Model Semantic Segmentation
Mar 17, 2026Accurate semantic segmentation of 3D dental models is essential for digital dentistry applications such as orthodontics and dental implants. However, due to complex tooth arrangements and similarities in shape among adjacent teeth, existing methods struggle with accurate segmentation, because they often focus on local geometry while neglecting global contextual information. To address this, we propose TCATSeg, a novel framework that combines local geometric features with global semantic context. We introduce a set of sparse yet physically meaningful superpoints to capture global semantic relationships and enhance segmentation accuracy. Additionally, we present a new dataset of 400 dental models, including pre-orthodontic samples, to evaluate the generalization of our method. Extensive experiments demonstrate that TCATSeg outperforms state-of-the-art approaches.
Teeth-SEG: An Efficient Instance Segmentation Framework for Orthodontic Treatment based on Anthropic Prior Knowledge
Apr 01, 2024



Teeth localization, segmentation, and labeling in 2D images have great potential in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, general instance segmentation frameworks are incompetent due to 1) the subtle differences between some teeth' shapes (e.g., maxillary first premolar and second premolar), 2) the teeth's position and shape variation across subjects, and 3) the presence of abnormalities in the dentition (e.g., caries and edentulism). To address these problems, we propose a ViT-based framework named TeethSEG, which consists of stacked Multi-Scale Aggregation (MSA) blocks and an Anthropic Prior Knowledge (APK) layer. Specifically, to compose the two modules, we design 1) a unique permutation-based upscaler to ensure high efficiency while establishing clear segmentation boundaries with 2) multi-head self/cross-gating layers to emphasize particular semantics meanwhile maintaining the divergence between token embeddings. Besides, we collect 3) the first open-sourced intraoral image dataset IO150K, which comprises over 150k intraoral photos, and all photos are annotated by orthodontists using a human-machine hybrid algorithm. Experiments on IO150K demonstrate that our TeethSEG outperforms the state-of-the-art segmentation models on dental image segmentation.
Automatic Tooth Arrangement with Joint Features of Point and Mesh Representations via Diffusion Probabilistic Models
Dec 23, 2023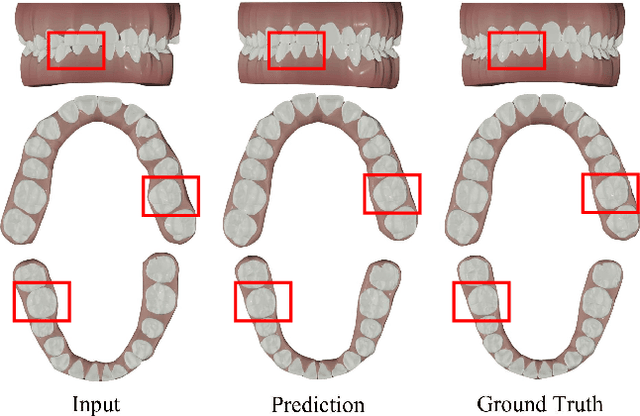
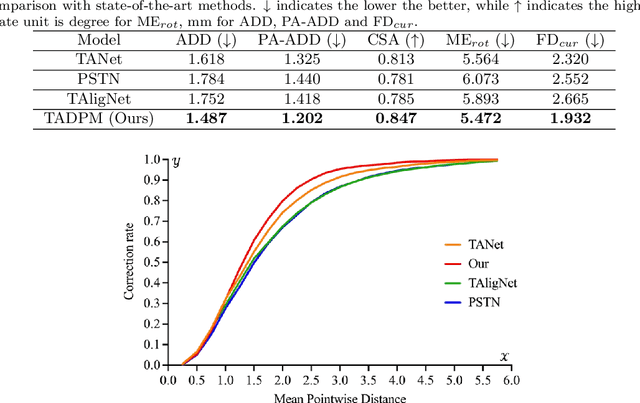

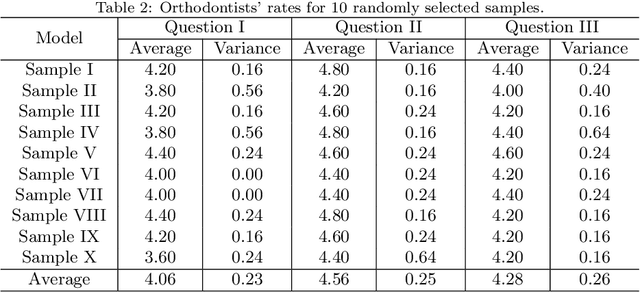
Tooth arrangement is a crucial step in orthodontics treatment, in which aligning teeth could improve overall well-being, enhance facial aesthetics, and boost self-confidence. To improve the efficiency of tooth arrangement and minimize errors associated with unreasonable designs by inexperienced practitioners, some deep learning-based tooth arrangement methods have been proposed. Currently, most existing approaches employ MLPs to model the nonlinear relationship between tooth features and transformation matrices to achieve tooth arrangement automatically. However, the limited datasets (which to our knowledge, have not been made public) collected from clinical practice constrain the applicability of existing methods, making them inadequate for addressing diverse malocclusion issues. To address this challenge, we propose a general tooth arrangement neural network based on the diffusion probabilistic model. Conditioned on the features extracted from the dental model, the diffusion probabilistic model can learn the distribution of teeth transformation matrices from malocclusion to normal occlusion by gradually denoising from a random variable, thus more adeptly managing real orthodontic data. To take full advantage of effective features, we exploit both mesh and point cloud representations by designing different encoding networks to extract the tooth (local) and jaw (global) features, respectively. In addition to traditional metrics ADD, PA-ADD, CSA, and ME_{rot}, we propose a new evaluation metric based on dental arch curves to judge whether the generated teeth meet the individual normal occlusion. Experimental results demonstrate that our proposed method achieves state-of-the-art tooth alignment results and satisfactory occlusal relationships between dental arches. We will publish the code and dataset.
Audience Expansion for Multi-show Release Based on an Edge-prompted Heterogeneous Graph Network
Apr 08, 2023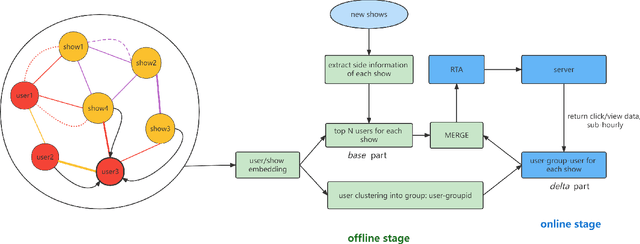

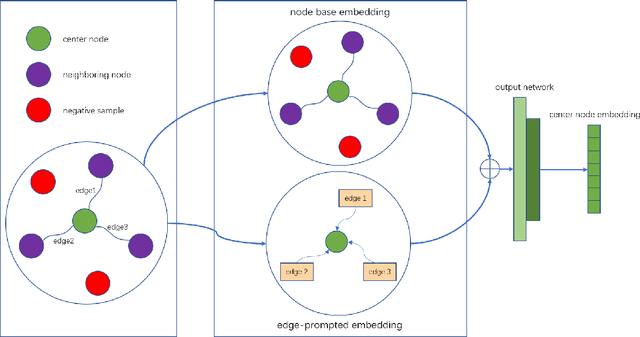
In the user targeting and expanding of new shows on a video platform, the key point is how their embeddings are generated. It's supposed to be personalized from the perspective of both users and shows. Furthermore, the pursue of both instant (click) and long-time (view time) rewards, and the cold-start problem for new shows bring additional challenges. Such a problem is suitable for processing by heterogeneous graph models, because of the natural graph structure of data. But real-world networks usually have billions of nodes and various types of edges. Few existing methods focus on handling large-scale data and exploiting different types of edges, especially the latter. In this paper, we propose a two-stage audience expansion scheme based on an edge-prompted heterogeneous graph network which can take different double-sided interactions and features into account. In the offline stage, to construct the graph, user IDs and specific side information combinations of the shows are chosen to be the nodes, and click/co-click relations and view time are used to build the edges. Embeddings and clustered user groups are then calculated. When new shows arrive, their embeddings and subsequent matching users can be produced within a consistent space. In the online stage, posterior data including click/view users are employed as seeds to look for similar users. The results on the public datasets and our billion-scale data demonstrate the accuracy and efficiency of our approach.