 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOutlier-robust Autocovariance Least Square Estimation via Iteratively Reweighted Least Square
Mar 09, 2026The autocovariance least squares (ALS) method is a computationally efficient approach for estimating noise covariances in Kalman filters without requiring specific noise models. However, conventional ALS and its variants rely on the classic least mean squares (LMS) criterion, making them highly sensitive to measurement outliers and prone to severe performance degradation. To overcome this limitation, this paper proposes a novel outlier-robust ALS algorithm, termed ALS-IRLS, based on the iteratively reweighted least squares (IRLS) framework. Specifically, the proposed approach introduces a two-tier robustification strategy. First, an innovation-level adaptive thresholding mechanism is employed to filter out heavily contaminated data. Second, the outlier-contaminated autocovariance is formulated using an $ε$-contamination model, where the standard LMS criterion is replaced by the Huber cost function. The IRLS method is then utilized to iteratively adjust data weights based on estimation deviations, effectively mitigating the influence of residual outliers. Comparative simulations demonstrate that ALS-IRLS reduces the root-mean-square error (RMSE) of noise covariance estimates by over two orders of magnitude compared to standard ALS. Furthermore, it significantly enhances downstream state estimation accuracy, outperforming existing outlier-robust Kalman filters and achieving performance nearly equivalent to the ideal Oracle lower bound in the presence of noisy and anomalous data.
Towards Comprehensive Semantic Speech Embeddings for Chinese Dialects
Jan 12, 2026Despite having hundreds of millions of speakers, Chinese dialects lag behind Mandarin in speech and language technologies. Most varieties are primarily spoken, making dialect-to-Mandarin speech-LLMs (large language models) more practical than dialect LLMs. Building dialect-to-Mandarin speech-LLMs requires speech representations with cross-dialect semantic alignment between Chinese dialects and Mandarin. In this paper, we achieve such a cross-dialect semantic alignment by training a speech encoder with ASR (automatic speech recognition)-only data, as demonstrated by speech-to-speech retrieval on a new benchmark of spoken Chinese varieties that we contribute. Our speech encoder further demonstrates state-of-the-art ASR performance on Chinese dialects. Together, our Chinese dialect benchmark, semantically aligned speech representations, and speech-to-speech retrieval evaluation lay the groundwork for future Chinese dialect speech-LLMs. We release the benchmark at https://github.com/kalvinchang/yubao.
TTA: Transcribe, Translate and Alignment for Cross-lingual Speech Representation
Nov 18, 2025Speech-LLM models have demonstrated great performance in multi-modal and multi-task speech understanding. A typical speech-LLM paradigm is integrating speech modality with a large language model (LLM). While the Whisper encoder was frequently adopted in previous studies for speech input, it shows limitations regarding input format, model scale, and semantic performance. To this end, we propose a lightweight TTA model specialized in speech semantics for more effective LLM integration. With large-scale training of 358k hours of speech data on multilingual speech recognition (ASR), speech translation (ST) and speech-text alignment tasks, TTA is capable of producing robust cross-lingual speech representations. Extensive evaluations across diverse benchmarks, including ASR/ST, speech retrieval, and ASR-LLM performance assessments, demonstrate TTA's superiority over Whisper. Furthermore, we rigorously validate the interplay between cross-lingual capabilities and ASR/ST performance. The model weights and training recipes of TTA will be released as part of an audio understanding toolkit Auden.
Treatment Effect Estimation for Exponential Family Outcomes using Neural Networks with Targeted Regularization
Feb 11, 2025Neural Networks (NNs) have became a natural choice for treatment effect estimation due to their strong approximation capabilities. Nevertheless, how to design NN-based estimators with desirable properties, such as low bias and doubly robustness, still remains a significant challenge. A common approach to address this is targeted regularization, which modifies the objective function of NNs. However, existing works on targeted regularization are limited to Gaussian-distributed outcomes, significantly restricting their applicability in real-world scenarios. In this work, we aim to bridge this blank by extending this framework to the boarder exponential family outcomes. Specifically, we first derive the von-Mises expansion of the Average Dose function of Canonical Functions (ADCF), which inspires us how to construct a doubly robust estimator with good properties. Based on this, we develop a NN-based estimator for ADCF by generalizing functional targeted regularization to exponential families, and provide the corresponding theoretical convergence rate. Extensive experimental results demonstrate the effectiveness of our proposed model.
FlowText: Synthesizing Realistic Scene Text Video with Optical Flow Estimation
May 05, 2023Current video text spotting methods can achieve preferable performance, powered with sufficient labeled training data. However, labeling data manually is time-consuming and labor-intensive. To overcome this, using low-cost synthetic data is a promising alternative. This paper introduces a novel video text synthesis technique called FlowText, which utilizes optical flow estimation to synthesize a large amount of text video data at a low cost for training robust video text spotters. Unlike existing methods that focus on image-level synthesis, FlowText concentrates on synthesizing temporal information of text instances across consecutive frames using optical flow. This temporal information is crucial for accurately tracking and spotting text in video sequences, including text movement, distortion, appearance, disappearance, shelter, and blur. Experiments show that combining general detectors like TransDETR with the proposed FlowText produces remarkable results on various datasets, such as ICDAR2015video and ICDAR2013video. Code is available at https://github.com/callsys/FlowText.
A Large Cross-Modal Video Retrieval Dataset with Reading Comprehension
May 05, 2023Most existing cross-modal language-to-video retrieval (VR) research focuses on single-modal input from video, i.e., visual representation, while the text is omnipresent in human environments and frequently critical to understand video. To study how to retrieve video with both modal inputs, i.e., visual and text semantic representations, we first introduce a large-scale and cross-modal Video Retrieval dataset with text reading comprehension, TextVR, which contains 42.2k sentence queries for 10.5k videos of 8 scenario domains, i.e., Street View (indoor), Street View (outdoor), Games, Sports, Driving, Activity, TV Show, and Cooking. The proposed TextVR requires one unified cross-modal model to recognize and comprehend texts, relate them to the visual context, and decide what text semantic information is vital for the video retrieval task. Besides, we present a detailed analysis of TextVR compared to the existing datasets and design a novel multimodal video retrieval baseline for the text-based video retrieval task. The dataset analysis and extensive experiments show that our TextVR benchmark provides many new technical challenges and insights from previous datasets for the video-and-language community. The project website and GitHub repo can be found at https://sites.google.com/view/loveucvpr23/guest-track and https://github.com/callsys/TextVR, respectively.
ICDAR 2023 Video Text Reading Competition for Dense and Small Text
Apr 10, 2023



Recently, video text detection, tracking, and recognition in natural scenes are becoming very popular in the computer vision community. However, most existing algorithms and benchmarks focus on common text cases (e.g., normal size, density) and single scenarios, while ignoring extreme video text challenges, i.e., dense and small text in various scenarios. In this competition report, we establish a video text reading benchmark, DSText, which focuses on dense and small text reading challenges in the video with various scenarios. Compared with the previous datasets, the proposed dataset mainly include three new challenges: 1) Dense video texts, a new challenge for video text spotter. 2) High-proportioned small texts. 3) Various new scenarios, e.g., Game, sports, etc. The proposed DSText includes 100 video clips from 12 open scenarios, supporting two tasks (i.e., video text tracking (Task 1) and end-to-end video text spotting (Task 2)). During the competition period (opened on 15th February 2023 and closed on 20th March 2023), a total of 24 teams participated in the three proposed tasks with around 30 valid submissions, respectively. In this article, we describe detailed statistical information of the dataset, tasks, evaluation protocols and the results summaries of the ICDAR 2023 on DSText competition. Moreover, we hope the benchmark will promise video text research in the community.
Audience Expansion for Multi-show Release Based on an Edge-prompted Heterogeneous Graph Network
Apr 08, 2023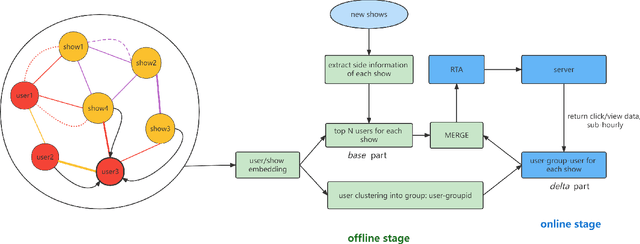

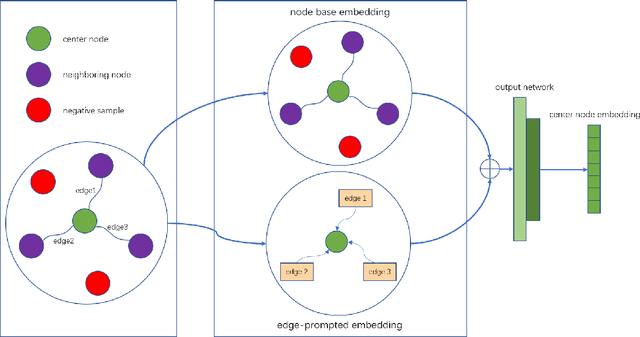
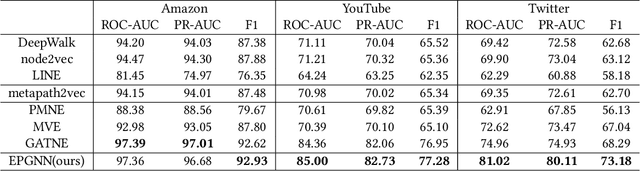
In the user targeting and expanding of new shows on a video platform, the key point is how their embeddings are generated. It's supposed to be personalized from the perspective of both users and shows. Furthermore, the pursue of both instant (click) and long-time (view time) rewards, and the cold-start problem for new shows bring additional challenges. Such a problem is suitable for processing by heterogeneous graph models, because of the natural graph structure of data. But real-world networks usually have billions of nodes and various types of edges. Few existing methods focus on handling large-scale data and exploiting different types of edges, especially the latter. In this paper, we propose a two-stage audience expansion scheme based on an edge-prompted heterogeneous graph network which can take different double-sided interactions and features into account. In the offline stage, to construct the graph, user IDs and specific side information combinations of the shows are chosen to be the nodes, and click/co-click relations and view time are used to build the edges. Embeddings and clustered user groups are then calculated. When new shows arrive, their embeddings and subsequent matching users can be produced within a consistent space. In the online stage, posterior data including click/view users are employed as seeds to look for similar users. The results on the public datasets and our billion-scale data demonstrate the accuracy and efficiency of our approach.
Real-time End-to-End Video Text Spotter with Contrastive Representation Learning
Jul 18, 2022



Video text spotting(VTS) is the task that requires simultaneously detecting, tracking and recognizing text in the video. Existing video text spotting methods typically develop sophisticated pipelines and multiple models, which is not friend for real-time applications. Here we propose a real-time end-to-end video text spotter with Contrastive Representation learning (CoText). Our contributions are three-fold: 1) CoText simultaneously address the three tasks (e.g., text detection, tracking, recognition) in a real-time end-to-end trainable framework. 2) With contrastive learning, CoText models long-range dependencies and learning temporal information across multiple frames. 3) A simple, lightweight architecture is designed for effective and accurate performance, including GPU-parallel detection post-processing, CTC-based recognition head with Masked RoI. Extensive experiments show the superiority of our method. Especially, CoText achieves an video text spotting IDF1 of 72.0% at 41.0 FPS on ICDAR2015video, with 10.5% and 32.0 FPS improvement the previous best method. The code can be found at github.com/weijiawu/CoText.
Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing
Mar 18, 2022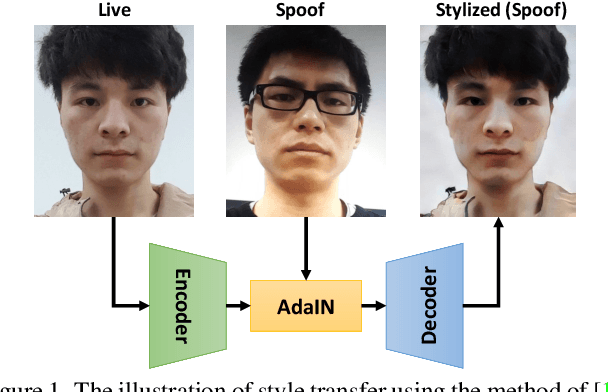
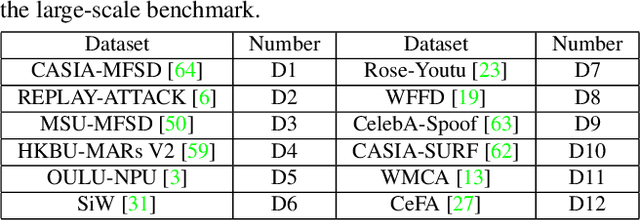
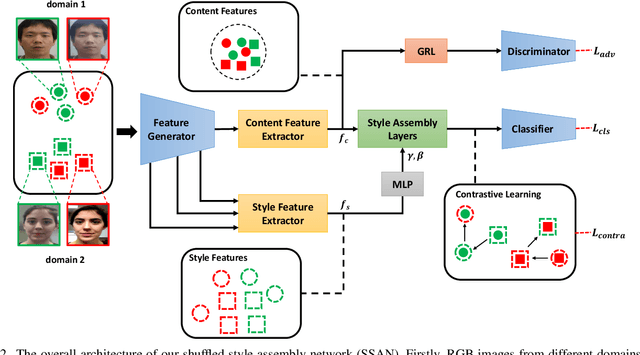
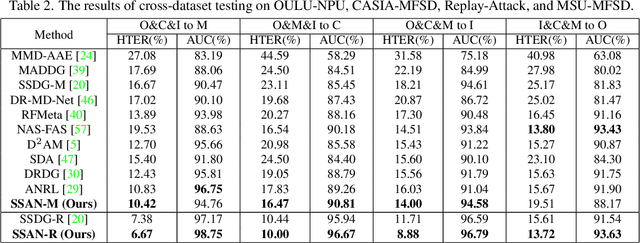
With diverse presentation attacks emerging continually, generalizable face anti-spoofing (FAS) has drawn growing attention. Most existing methods implement domain generalization (DG) on the complete representations. However, different image statistics may have unique properties for the FAS tasks. In this work, we separate the complete representation into content and style ones. A novel Shuffled Style Assembly Network (SSAN) is proposed to extract and reassemble different content and style features for a stylized feature space. Then, to obtain a generalized representation, a contrastive learning strategy is developed to emphasize liveness-related style information while suppress the domain-specific one. Finally, the representations of the correct assemblies are used to distinguish between living and spoofing during the inferring. On the other hand, despite the decent performance, there still exists a gap between academia and industry, due to the difference in data quantity and distribution. Thus, a new large-scale benchmark for FAS is built up to further evaluate the performance of algorithms in reality. Both qualitative and quantitative results on existing and proposed benchmarks demonstrate the effectiveness of our methods. The codes will be available at https://github.com/wangzhuo2019/SSAN.