 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudience Expansion for Multi-show Release Based on an Edge-prompted Heterogeneous Graph Network
Apr 08, 2023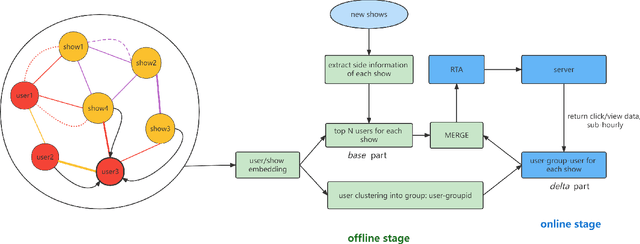

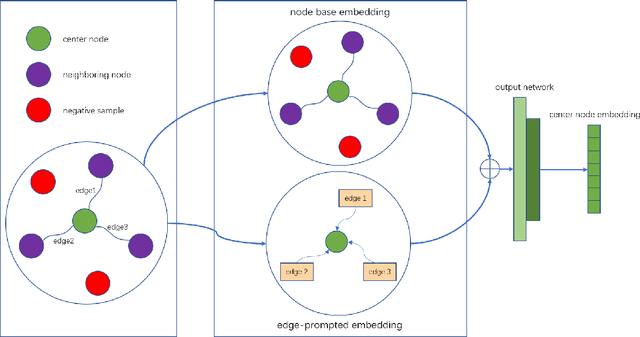
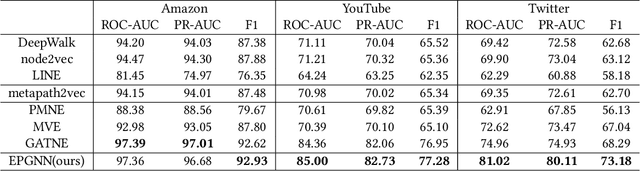
In the user targeting and expanding of new shows on a video platform, the key point is how their embeddings are generated. It's supposed to be personalized from the perspective of both users and shows. Furthermore, the pursue of both instant (click) and long-time (view time) rewards, and the cold-start problem for new shows bring additional challenges. Such a problem is suitable for processing by heterogeneous graph models, because of the natural graph structure of data. But real-world networks usually have billions of nodes and various types of edges. Few existing methods focus on handling large-scale data and exploiting different types of edges, especially the latter. In this paper, we propose a two-stage audience expansion scheme based on an edge-prompted heterogeneous graph network which can take different double-sided interactions and features into account. In the offline stage, to construct the graph, user IDs and specific side information combinations of the shows are chosen to be the nodes, and click/co-click relations and view time are used to build the edges. Embeddings and clustered user groups are then calculated. When new shows arrive, their embeddings and subsequent matching users can be produced within a consistent space. In the online stage, posterior data including click/view users are employed as seeds to look for similar users. The results on the public datasets and our billion-scale data demonstrate the accuracy and efficiency of our approach.
Acoustic-to-articulatory Inversion based on Speech Decomposition and Auxiliary Feature
Apr 02, 2022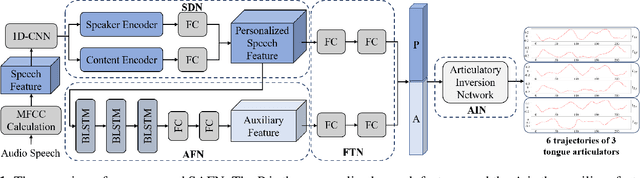
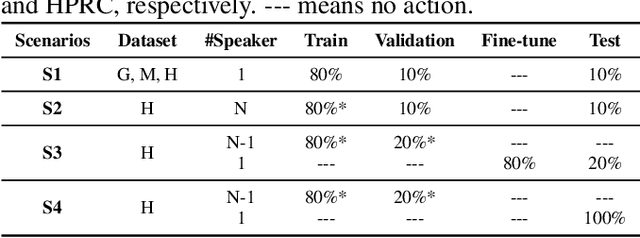
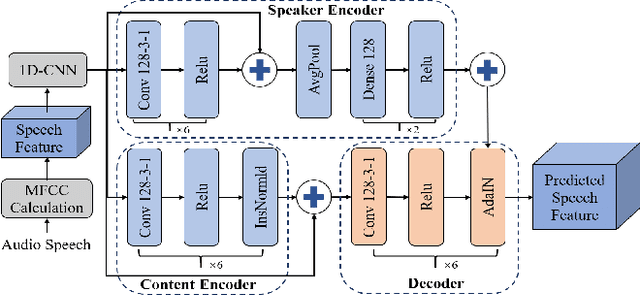
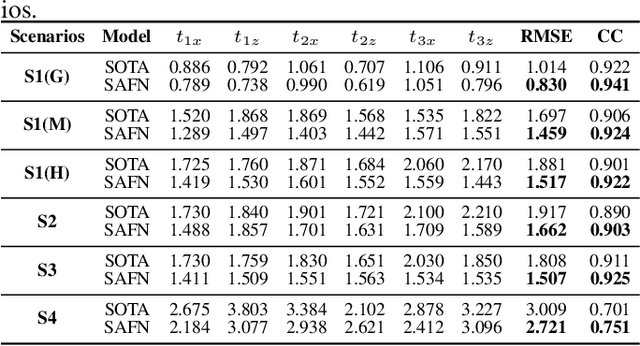
Acoustic-to-articulatory inversion (AAI) is to obtain the movement of articulators from speech signals. Until now, achieving a speaker-independent AAI remains a challenge given the limited data. Besides, most current works only use audio speech as input, causing an inevitable performance bottleneck. To solve these problems, firstly, we pre-train a speech decomposition network to decompose audio speech into speaker embedding and content embedding as the new personalized speech features to adapt to the speaker-independent case. Secondly, to further improve the AAI, we propose a novel auxiliary feature network to estimate the lip auxiliary features from the above personalized speech features. Experimental results on three public datasets show that, compared with the state-of-the-art only using the audio speech feature, the proposed method reduces the average RMSE by 0.25 and increases the average correlation coefficient by 2.0% in the speaker-dependent case. More importantly, the average RMSE decreases by 0.29 and the average correlation coefficient increases by 5.0% in the speaker-independent case.
Three-Dimensional Lip Motion Network for Text-Independent Speaker Recognition
Oct 13, 2020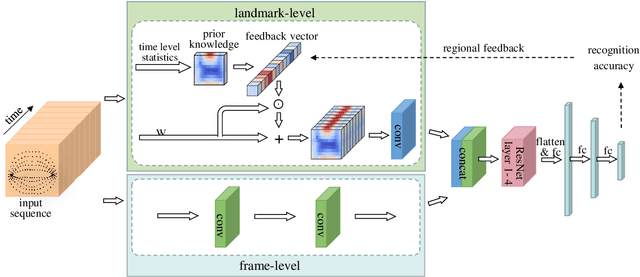
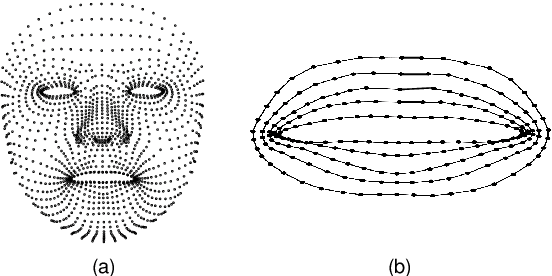

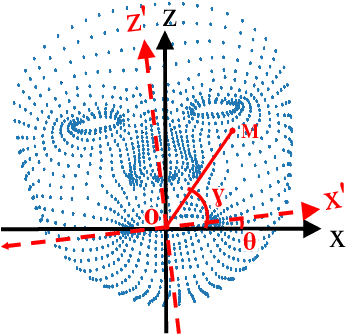
Lip motion reflects behavior characteristics of speakers, and thus can be used as a new kind of biometrics in speaker recognition. In the literature, lots of works used two-dimensional (2D) lip images to recognize speaker in a textdependent context. However, 2D lip easily suffers from various face orientations. To this end, in this work, we present a novel end-to-end 3D lip motion Network (3LMNet) by utilizing the sentence-level 3D lip motion (S3DLM) to recognize speakers in both the text-independent and text-dependent contexts. A new regional feedback module (RFM) is proposed to obtain attentions in different lip regions. Besides, prior knowledge of lip motion is investigated to complement RFM, where landmark-level and frame-level features are merged to form a better feature representation. Moreover, we present two methods, i.e., coordinate transformation and face posture correction to pre-process the LSD-AV dataset, which contains 68 speakers and 146 sentences per speaker. The evaluation results on this dataset demonstrate that our proposed 3LMNet is superior to the baseline models, i.e., LSTM, VGG-16 and ResNet-34, and outperforms the state-of-the-art using 2D lip image as well as the 3D face. The code of this work is released at https://github.com/wutong18/Three-Dimensional-Lip- Motion-Network-for-Text-Independent-Speaker-Recognition.