 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScribbleVS: Scribble-Supervised Medical Image Segmentation via Dynamic Competitive Pseudo Label Selection
Nov 15, 2024



In clinical medicine, precise image segmentation can provide substantial support to clinicians. However, achieving such precision often requires a large amount of finely annotated data, which can be costly. Scribble annotation presents a more efficient alternative, boosting labeling efficiency. However, utilizing such minimal supervision for medical image segmentation training, especially with scribble annotations, poses significant challenges. To address these challenges, we introduce ScribbleVS, a novel framework that leverages scribble annotations. We introduce a Regional Pseudo Labels Diffusion Module to expand the scope of supervision and reduce the impact of noise present in pseudo labels. Additionally, we propose a Dynamic Competitive Selection module for enhanced refinement in selecting pseudo labels. Experiments conducted on the ACDC and MSCMRseg datasets have demonstrated promising results, achieving performance levels that even exceed those of fully supervised methodologies. The codes of this study are available at https://github.com/ortonwang/ScribbleVS.
Synergy-Guided Regional Supervision of Pseudo Labels for Semi-Supervised Medical Image Segmentation
Nov 07, 2024



Semi-supervised learning has received considerable attention for its potential to leverage abundant unlabeled data to enhance model robustness. Pseudo labeling is a widely used strategy in semi supervised learning. However, existing methods often suffer from noise contamination, which can undermine model performance. To tackle this challenge, we introduce a novel Synergy-Guided Regional Supervision of Pseudo Labels (SGRS-Net) framework. Built upon the mean teacher network, we employ a Mix Augmentation module to enhance the unlabeled data. By evaluating the synergy before and after augmentation, we strategically partition the pseudo labels into distinct regions. Additionally, we introduce a Region Loss Evaluation module to assess the loss across each delineated area. Extensive experiments conducted on the LA dataset have demonstrated superior performance over state-of-the-art techniques, underscoring the efficiency and practicality of our framework.
Innovative Quantitative Analysis for Disease Progression Assessment in Familial Cerebral Cavernous Malformations
Mar 23, 2024Familial cerebral cavernous malformation (FCCM) is a hereditary disorder characterized by abnormal vascular structures within the central nervous system. The FCCM lesions are often numerous and intricate, making quantitative analysis of the lesions a labor-intensive task. Consequently, clinicians face challenges in quantitatively assessing the severity of lesions and determining whether lesions have progressed. To alleviate this problem, we propose a quantitative statistical framework for FCCM, comprising an efficient annotation module, an FCCM lesion segmentation module, and an FCCM lesion quantitative statistics module. Our framework demonstrates precise segmentation of the FCCM lesion based on efficient data annotation, achieving a Dice coefficient of 93.22\%. More importantly, we focus on quantitative statistics of lesions, which is combined with image registration to realize the quantitative comparison of lesions between different examinations of patients, and a visualization framework has been established for doctors to comprehensively compare and analyze lesions. The experimental results have demonstrated that our proposed framework not only obtains objective, accurate, and comprehensive quantitative statistical information, which provides a quantitative assessment method for disease progression and drug efficacy study, but also considerably reduces the manual measurement and statistical workload of lesions, assisting clinical decision-making for FCCM and accelerating progress in FCCM clinical research. This highlights the potential of practical application of the framework in FCCM clinical research and clinical decision-making. The codes are available at https://github.com/6zrg/Quantitative-Statistics-of-FCCM.
Dual-Decoder Consistency via Pseudo-Labels Guided Data Augmentation for Semi-Supervised Medical Image Segmentation
Aug 31, 2023Medical image segmentation methods often rely on fully supervised approaches to achieve excellent performance, which is contingent upon having an extensive set of labeled images for training. However, annotating medical images is both expensive and time-consuming. Semi-supervised learning offers a solution by leveraging numerous unlabeled images alongside a limited set of annotated ones. In this paper, we introduce a semi-supervised medical image segmentation method based on the mean-teacher model, referred to as Dual-Decoder Consistency via Pseudo-Labels Guided Data Augmentation (DCPA). This method combines consistency regularization, pseudo-labels, and data augmentation to enhance the efficacy of semi-supervised segmentation. Firstly, the proposed model comprises both student and teacher models with a shared encoder and two distinct decoders employing different up-sampling strategies. Minimizing the output discrepancy between decoders enforces the generation of consistent representations, serving as regularization during student model training. Secondly, we introduce mixup operations to blend unlabeled data with labeled data, creating mixed data and thereby achieving data augmentation. Lastly, pseudo-labels are generated by the teacher model and utilized as labels for mixed data to compute unsupervised loss. We compare the segmentation results of the DCPA model with six state-of-the-art semi-supervised methods on three publicly available medical datasets. Beyond classical 10\% and 20\% semi-supervised settings, we investigate performance with less supervision (5\% labeled data). Experimental outcomes demonstrate that our approach consistently outperforms existing semi-supervised medical image segmentation methods across the three semi-supervised settings.
Acoustic-to-articulatory Inversion based on Speech Decomposition and Auxiliary Feature
Apr 02, 2022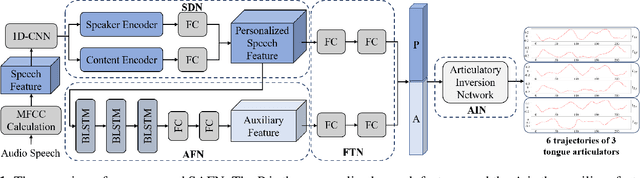
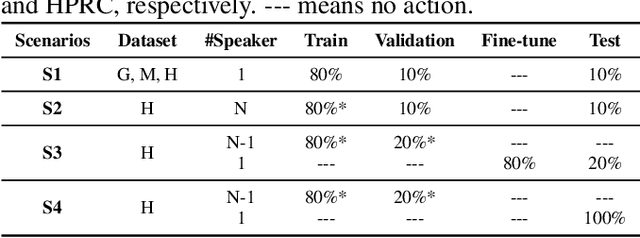
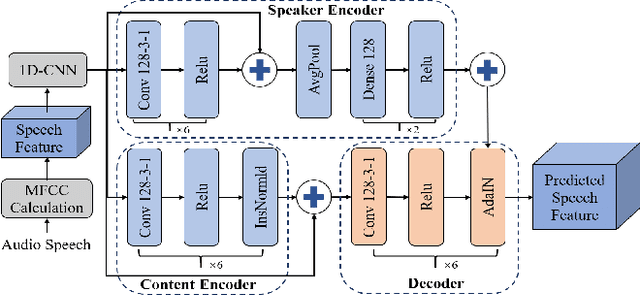
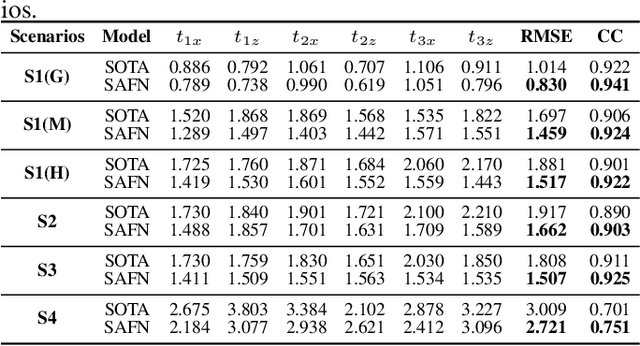
Acoustic-to-articulatory inversion (AAI) is to obtain the movement of articulators from speech signals. Until now, achieving a speaker-independent AAI remains a challenge given the limited data. Besides, most current works only use audio speech as input, causing an inevitable performance bottleneck. To solve these problems, firstly, we pre-train a speech decomposition network to decompose audio speech into speaker embedding and content embedding as the new personalized speech features to adapt to the speaker-independent case. Secondly, to further improve the AAI, we propose a novel auxiliary feature network to estimate the lip auxiliary features from the above personalized speech features. Experimental results on three public datasets show that, compared with the state-of-the-art only using the audio speech feature, the proposed method reduces the average RMSE by 0.25 and increases the average correlation coefficient by 2.0% in the speaker-dependent case. More importantly, the average RMSE decreases by 0.29 and the average correlation coefficient increases by 5.0% in the speaker-independent case.