 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Specialized Large Language Model for Clinical Reasoning and Diagnosis in Rare Diseases
Nov 18, 2025Rare diseases affect hundreds of millions worldwide, yet diagnosis often spans years. Convectional pipelines decouple noisy evidence extraction from downstream inferential diagnosis, and general/medical large language models (LLMs) face scarce real world electronic health records (EHRs), stale domain knowledge, and hallucinations. We assemble a large, domain specialized clinical corpus and a clinician validated reasoning set, and develop RareSeek R1 via staged instruction tuning, chain of thought learning, and graph grounded retrieval. Across multicenter EHR narratives and public benchmarks, RareSeek R1 attains state of the art accuracy, robust generalization, and stability under noisy or overlapping phenotypes. Augmented retrieval yields the largest gains when narratives pair with prioritized variants by resolving ambiguity and aligning candidates to mechanisms. Human studies show performance on par with experienced physicians and consistent gains in assistive use. Notably, transparent reasoning highlights decisive non phenotypic evidence (median 23.1%, such as imaging, interventions, functional tests) underpinning many correct diagnoses. This work advances a narrative first, knowledge integrated reasoning paradigm that shortens the diagnostic odyssey and enables auditable, clinically translatable decision support.
Grounded by Experience: Generative Healthcare Prediction Augmented with Hierarchical Agentic Retrieval
Nov 17, 2025Accurate healthcare prediction is critical for improving patient outcomes and reducing operational costs. Bolstered by growing reasoning capabilities, large language models (LLMs) offer a promising path to enhance healthcare predictions by drawing on their rich parametric knowledge. However, LLMs are prone to factual inaccuracies due to limitations in the reliability and coverage of their embedded knowledge. While retrieval-augmented generation (RAG) frameworks, such as GraphRAG and its variants, have been proposed to mitigate these issues by incorporating external knowledge, they face two key challenges in the healthcare scenario: (1) identifying the clinical necessity to activate the retrieval mechanism, and (2) achieving synergy between the retriever and the generator to craft contextually appropriate retrievals. To address these challenges, we propose GHAR, a \underline{g}enerative \underline{h}ierarchical \underline{a}gentic \underline{R}AG framework that simultaneously resolves when to retrieve and how to optimize the collaboration between submodules in healthcare. Specifically, for the first challenge, we design a dual-agent architecture comprising Agent-Top and Agent-Low. Agent-Top acts as the primary physician, iteratively deciding whether to rely on parametric knowledge or to initiate retrieval, while Agent-Low acts as the consulting service, summarising all task-relevant knowledge once retrieval was triggered. To tackle the second challenge, we innovatively unify the optimization of both agents within a formal Markov Decision Process, designing diverse rewards to align their shared goal of accurate prediction while preserving their distinct roles. Extensive experiments on three benchmark datasets across three popular tasks demonstrate our superiority over state-of-the-art baselines, highlighting the potential of hierarchical agentic RAG in advancing healthcare systems.
Diffmv: A Unified Diffusion Framework for Healthcare Predictions with Random Missing Views and View Laziness
May 17, 2025Advanced healthcare predictions offer significant improvements in patient outcomes by leveraging predictive analytics. Existing works primarily utilize various views of Electronic Health Record (EHR) data, such as diagnoses, lab tests, or clinical notes, for model training. These methods typically assume the availability of complete EHR views and that the designed model could fully leverage the potential of each view. However, in practice, random missing views and view laziness present two significant challenges that hinder further improvements in multi-view utilization. To address these challenges, we introduce Diffmv, an innovative diffusion-based generative framework designed to advance the exploitation of multiple views of EHR data. Specifically, to address random missing views, we integrate various views of EHR data into a unified diffusion-denoising framework, enriched with diverse contextual conditions to facilitate progressive alignment and view transformation. To mitigate view laziness, we propose a novel reweighting strategy that assesses the relative advantages of each view, promoting a balanced utilization of various data views within the model. Our proposed strategy achieves superior performance across multiple health prediction tasks derived from three popular datasets, including multi-view and multi-modality scenarios.
Leveraging Segment Anything Model for Source-Free Domain Adaptation via Dual Feature Guided Auto-Prompting
May 14, 2025Source-free domain adaptation (SFDA) for segmentation aims at adapting a model trained in the source domain to perform well in the target domain with only the source model and unlabeled target data.Inspired by the recent success of Segment Anything Model (SAM) which exhibits the generality of segmenting images of various modalities and in different domains given human-annotated prompts like bounding boxes or points, we for the first time explore the potentials of Segment Anything Model for SFDA via automatedly finding an accurate bounding box prompt. We find that the bounding boxes directly generated with existing SFDA approaches are defective due to the domain gap.To tackle this issue, we propose a novel Dual Feature Guided (DFG) auto-prompting approach to search for the box prompt. Specifically, the source model is first trained in a feature aggregation phase, which not only preliminarily adapts the source model to the target domain but also builds a feature distribution well-prepared for box prompt search. In the second phase, based on two feature distribution observations, we gradually expand the box prompt with the guidance of the target model feature and the SAM feature to handle the class-wise clustered target features and the class-wise dispersed target features, respectively. To remove the potentially enlarged false positive regions caused by the over-confident prediction of the target model, the refined pseudo-labels produced by SAM are further postprocessed based on connectivity analysis. Experiments on 3D and 2D datasets indicate that our approach yields superior performance compared to conventional methods. Code is available at https://github.com/xmed-lab/DFG.
Concept-Based Unsupervised Domain Adaptation
May 08, 2025Concept Bottleneck Models (CBMs) enhance interpretability by explaining predictions through human-understandable concepts but typically assume that training and test data share the same distribution. This assumption often fails under domain shifts, leading to degraded performance and poor generalization. To address these limitations and improve the robustness of CBMs, we propose the Concept-based Unsupervised Domain Adaptation (CUDA) framework. CUDA is designed to: (1) align concept representations across domains using adversarial training, (2) introduce a relaxation threshold to allow minor domain-specific differences in concept distributions, thereby preventing performance drop due to over-constraints of these distributions, (3) infer concepts directly in the target domain without requiring labeled concept data, enabling CBMs to adapt to diverse domains, and (4) integrate concept learning into conventional domain adaptation (DA) with theoretical guarantees, improving interpretability and establishing new benchmarks for DA. Experiments demonstrate that our approach significantly outperforms the state-of-the-art CBM and DA methods on real-world datasets.
DDaTR: Dynamic Difference-aware Temporal Residual Network for Longitudinal Radiology Report Generation
May 06, 2025Radiology Report Generation (RRG) automates the creation of radiology reports from medical imaging, enhancing the efficiency of the reporting process. Longitudinal Radiology Report Generation (LRRG) extends RRG by incorporating the ability to compare current and prior exams, facilitating the tracking of temporal changes in clinical findings. Existing LRRG approaches only extract features from prior and current images using a visual pre-trained encoder, which are then concatenated to generate the final report. However, these methods struggle to effectively capture both spatial and temporal correlations during the feature extraction process. Consequently, the extracted features inadequately capture the information of difference across exams and thus underrepresent the expected progressions, leading to sub-optimal performance in LRRG. To address this, we develop a novel dynamic difference-aware temporal residual network (DDaTR). In DDaTR, we introduce two modules at each stage of the visual encoder to capture multi-level spatial correlations. The Dynamic Feature Alignment Module (DFAM) is designed to align prior features across modalities for the integrity of prior clinical information. Prompted by the enriched prior features, the dynamic difference-aware module (DDAM) captures favorable difference information by identifying relationships across exams. Furthermore, our DDaTR employs the dynamic residual network to unidirectionally transmit longitudinal information, effectively modelling temporal correlations. Extensive experiments demonstrated superior performance over existing methods on three benchmarks, proving its efficacy in both RRG and LRRG tasks.
Efficient Masked Image Compression with Position-Indexed Self-Attention
Apr 17, 2025In recent years, image compression for high-level vision tasks has attracted considerable attention from researchers. Given that object information in images plays a far more crucial role in downstream tasks than background information, some studies have proposed semantically structuring the bitstream to selectively transmit and reconstruct only the information required by these tasks. However, such methods structure the bitstream after encoding, meaning that the coding process still relies on the entire image, even though much of the encoded information will not be transmitted. This leads to redundant computations. Traditional image compression methods require a two-dimensional image as input, and even if the unimportant regions of the image are set to zero by applying a semantic mask, these regions still participate in subsequent computations as part of the image. To address such limitations, we propose an image compression method based on a position-indexed self-attention mechanism that encodes and decodes only the visible parts of the masked image. Compared to existing semantic-structured compression methods, our approach can significantly reduce computational costs.
Adaptive Extensive Cancellation Algorithm and Harmonic Enhanced Heart Rate Estimation based on MMWave Radar
Mar 10, 2025Heart rate (HR) monitoring is crucial for assessing physical fitness, cardiovascular health, and stress management. Millimeter-wave radar offers a promising noncontact solution for long-term monitoring. However, accurate HR estimation remains challenging in low signal-tonoise ratio (SNR) conditions. To deal with both respiration harmonics and intermodulation interference, this paper proposes a cancellation-before-estimation strategy. Firstly, we present the adaptive extensive cancellation algorithm (ECA) to suppress respiratory and its low-order harmonics. Then, we propose an adaptive harmonic enhanced trace (AHET) method to avoid intermodulation interference by refining the HR search region. Various experimental results validate the effectiveness of the proposed methods, demonstrating improvements in accuracy, robustness, and computational efficiency compared to conventional approaches based on the FMCW (Frequency Modulated Continuous Wave) system
Respiratory Subtraction for Pulmonary Microwave Ablation Evaluation
Aug 08, 2024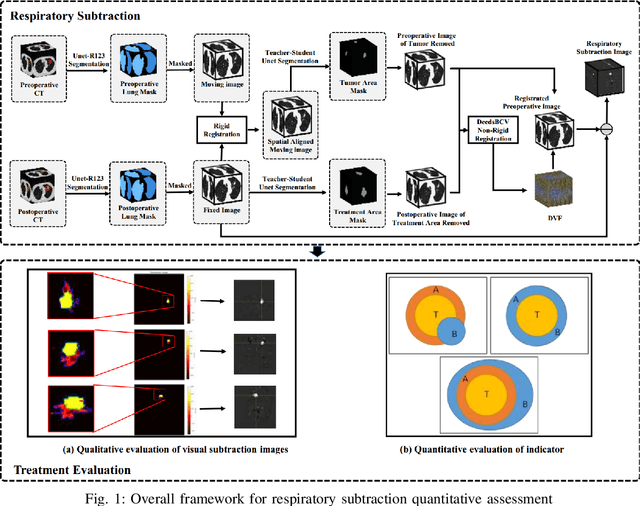
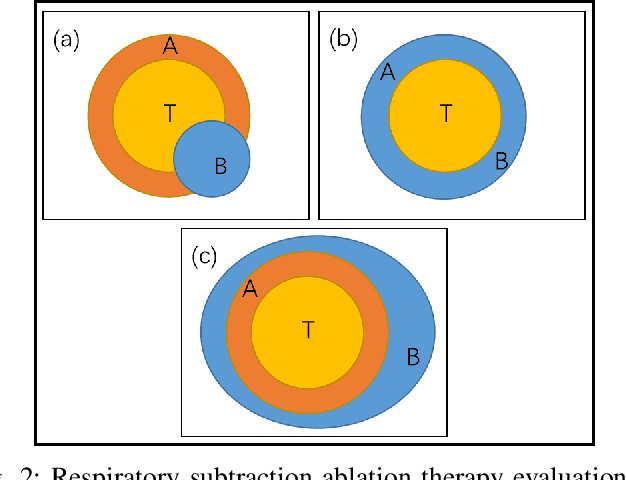
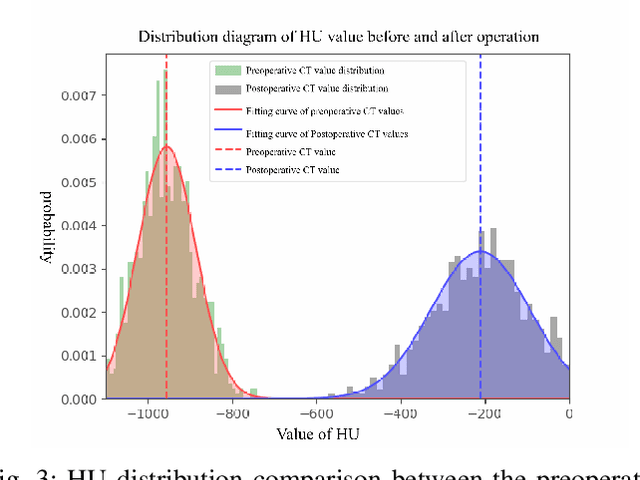
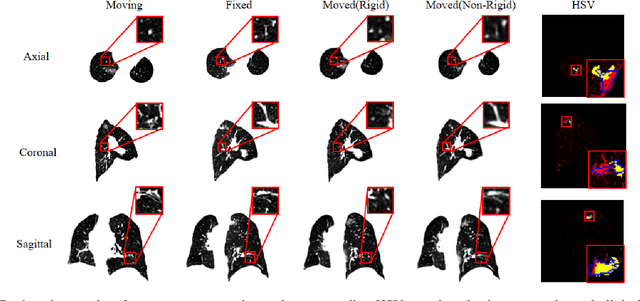
Currently, lung cancer is a leading cause of global cancer mortality, often necessitating minimally invasive interventions. Microwave ablation (MWA) is extensively utilized for both primary and secondary lung tumors. Although numerous clinical guidelines and standards for MWA have been established, the clinical evaluation of ablation surgery remains challenging and requires long-term patient follow-up for confirmation. In this paper, we propose a method termed respiratory subtraction to evaluate lung tumor ablation therapy performance based on pre- and post-operative image guidance. Initially, preoperative images undergo coarse rigid registration to their corresponding postoperative positions, followed by further non-rigid registration. Subsequently, subtraction images are generated by subtracting the registered preoperative images from the postoperative ones. Furthermore, to enhance the clinical assessment of MWA treatment performance, we devise a quantitative analysis metric to evaluate ablation efficacy by comparing differences between tumor areas and treatment areas. To the best of our knowledge, this is the pioneering work in the field to facilitate the assessment of MWA surgery performance on pulmonary tumors. Extensive experiments involving 35 clinical cases further validate the efficacy of the respiratory subtraction method. The experimental results confirm the effectiveness of the respiratory subtraction method and the proposed quantitative evaluation metric in assessing lung tumor treatment.
FITA: Fine-grained Image-Text Aligner for Radiology Report Generation
May 02, 2024Radiology report generation aims to automatically generate detailed and coherent descriptive reports alongside radiology images. Previous work mainly focused on refining fine-grained image features or leveraging external knowledge. However, the precise alignment of fine-grained image features with corresponding text descriptions has not been considered. This paper presents a novel method called Fine-grained Image-Text Aligner (FITA) to construct fine-grained alignment for image and text features. It has three novel designs: Image Feature Refiner (IFR), Text Feature Refiner (TFR) and Contrastive Aligner (CA). IFR and TFR aim to learn fine-grained image and text features, respectively. We achieve this by leveraging saliency maps to effectively fuse symptoms with corresponding abnormal visual regions, and by utilizing a meticulously constructed triplet set for training. Finally, CA module aligns fine-grained image and text features using contrastive loss for precise alignment. Results show that our method surpasses existing methods on the widely used benchmark