 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconstruction-based Multi-Normal Prototypes Learning for Weakly Supervised Anomaly Detection
Aug 23, 2024
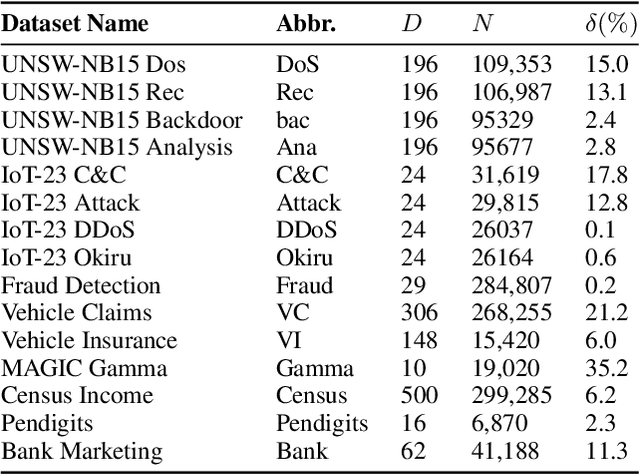

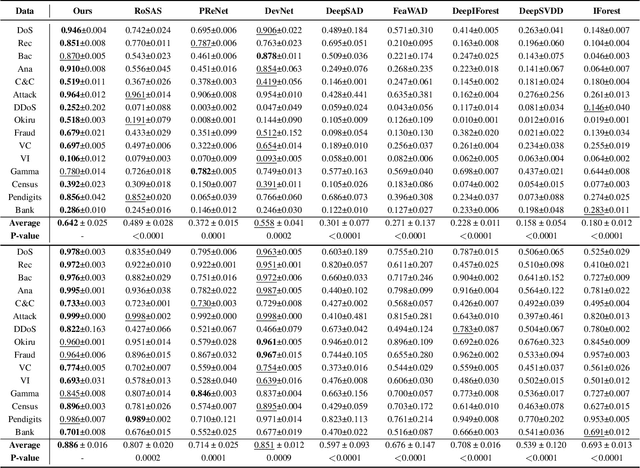
Anomaly detection is a crucial task in various domains. Most of the existing methods assume the normal sample data clusters around a single central prototype while the real data may consist of multiple categories or subgroups. In addition, existing methods always assume all unlabeled data are normal while they inevitably contain some anomalous samples. To address these issues, we propose a reconstruction-based multi-normal prototypes learning framework that leverages limited labeled anomalies in conjunction with abundant unlabeled data for anomaly detection. Specifically, we assume the normal sample data may satisfy multi-modal distribution, and utilize deep embedding clustering and contrastive learning to learn multiple normal prototypes to represent it. Additionally, we estimate the likelihood of each unlabeled sample being normal based on the multi-normal prototypes, guiding the training process to mitigate the impact of contaminated anomalies in the unlabeled data. Extensive experiments on various datasets demonstrate the superior performance of our method compared to state-of-the-art techniques.
A multi-stage semi-supervised learning for ankle fracture classification on CT images
Mar 29, 2024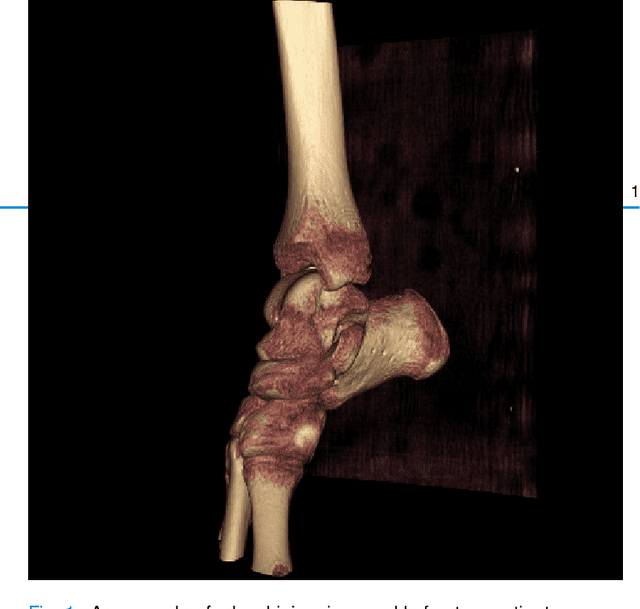
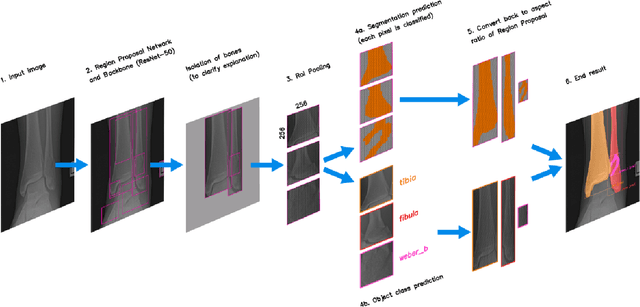
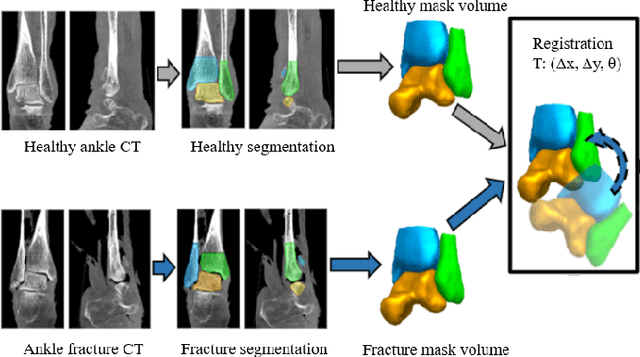
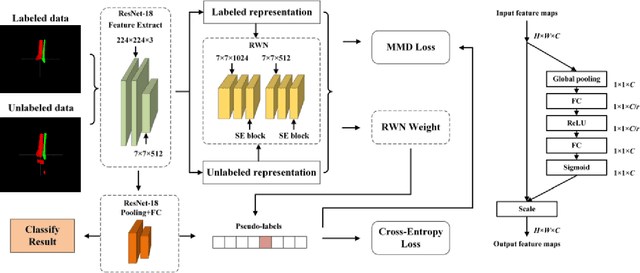
Because of the complicated mechanism of ankle injury, it is very difficult to diagnose ankle fracture in clinic. In order to simplify the process of fracture diagnosis, an automatic diagnosis model of ankle fracture was proposed. Firstly, a tibia-fibula segmentation network is proposed for the joint tibiofibular region of the ankle joint, and the corresponding segmentation dataset is established on the basis of fracture data. Secondly, the image registration method is used to register the bone segmentation mask with the normal bone mask. Finally, a semi-supervised classifier is constructed to make full use of a large number of unlabeled data to classify ankle fractures. Experiments show that the proposed method can segment fractures with fracture lines accurately and has better performance than the general method. At the same time, this method is superior to classification network in several indexes.
Large Language Model with Graph Convolution for Recommendation
Feb 14, 2024



In recent years, efforts have been made to use text information for better user profiling and item characterization in recommendations. However, text information can sometimes be of low quality, hindering its effectiveness for real-world applications. With knowledge and reasoning capabilities capsuled in Large Language Models (LLMs), utilizing LLMs emerges as a promising way for description improvement. However, existing ways of prompting LLMs with raw texts ignore structured knowledge of user-item interactions, which may lead to hallucination problems like inconsistent description generation. To this end, we propose a Graph-aware Convolutional LLM method to elicit LLMs to capture high-order relations in the user-item graph. To adapt text-based LLMs with structured graphs, We use the LLM as an aggregator in graph processing, allowing it to understand graph-based information step by step. Specifically, the LLM is required for description enhancement by exploring multi-hop neighbors layer by layer, thereby propagating information progressively in the graph. To enable LLMs to capture large-scale graph information, we break down the description task into smaller parts, which drastically reduces the context length of the token input with each step. Extensive experiments on three real-world datasets show that our method consistently outperforms state-of-the-art methods.
Bridging the Information Gap Between Domain-Specific Model and General LLM for Personalized Recommendation
Nov 07, 2023



Generative large language models(LLMs) are proficient in solving general problems but often struggle to handle domain-specific tasks. This is because most of domain-specific tasks, such as personalized recommendation, rely on task-related information for optimal performance. Current methods attempt to supplement task-related information to LLMs by designing appropriate prompts or employing supervised fine-tuning techniques. Nevertheless, these methods encounter the certain issue that information such as community behavior pattern in RS domain is challenging to express in natural language, which limits the capability of LLMs to surpass state-of-the-art domain-specific models. On the other hand, domain-specific models for personalized recommendation which mainly rely on user interactions are susceptible to data sparsity due to their limited common knowledge capabilities. To address these issues, we proposes a method to bridge the information gap between the domain-specific models and the general large language models. Specifically, we propose an information sharing module which serves as an information storage mechanism and also acts as a bridge for collaborative training between the LLMs and domain-specific models. By doing so, we can improve the performance of LLM-based recommendation with the help of user behavior pattern information mined by domain-specific models. On the other hand, the recommendation performance of domain-specific models can also be improved with the help of common knowledge learned by LLMs. Experimental results on three real-world datasets have demonstrated the effectiveness of the proposed method.
Enhancing Job Recommendation through LLM-based Generative Adversarial Networks
Jul 20, 2023
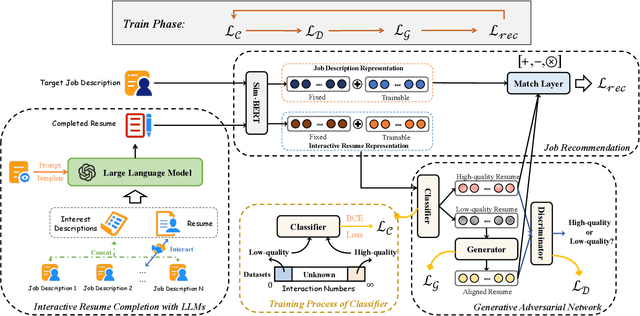


Recommending suitable jobs to users is a critical task in online recruitment platforms, as it can enhance users' satisfaction and the platforms' profitability. While existing job recommendation methods encounter challenges such as the low quality of users' resumes, which hampers their accuracy and practical effectiveness. With the rapid development of large language models (LLMs), utilizing the rich external knowledge encapsulated within them, as well as their powerful capabilities of text processing and reasoning, is a promising way to complete users' resumes for more accurate recommendations. However, directly leveraging LLMs to enhance recommendation results is not a one-size-fits-all solution, as LLMs may suffer from fabricated generation and few-shot problems, which degrade the quality of resume completion. In this paper, we propose a novel LLM-based approach for job recommendation. To alleviate the limitation of fabricated generation for LLMs, we extract accurate and valuable information beyond users' self-description, which helps the LLMs better profile users for resume completion. Specifically, we not only extract users' explicit properties (e.g., skills, interests) from their self-description but also infer users' implicit characteristics from their behaviors for more accurate and meaningful resume completion. Nevertheless, some users still suffer from few-shot problems, which arise due to scarce interaction records, leading to limited guidance for the models in generating high-quality resumes. To address this issue, we propose aligning unpaired low-quality with high-quality generated resumes by Generative Adversarial Networks (GANs), which can refine the resume representations for better recommendation results. Extensive experiments on three large real-world recruitment datasets demonstrate the effectiveness of our proposed method.
AiM: Taking Answers in Mind to Correct Chinese Cloze Tests in Educational Applications
Aug 26, 2022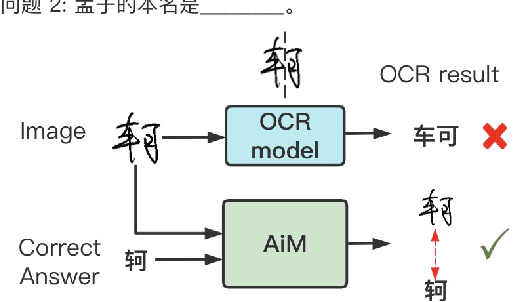
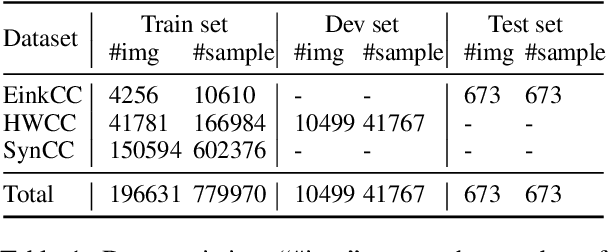
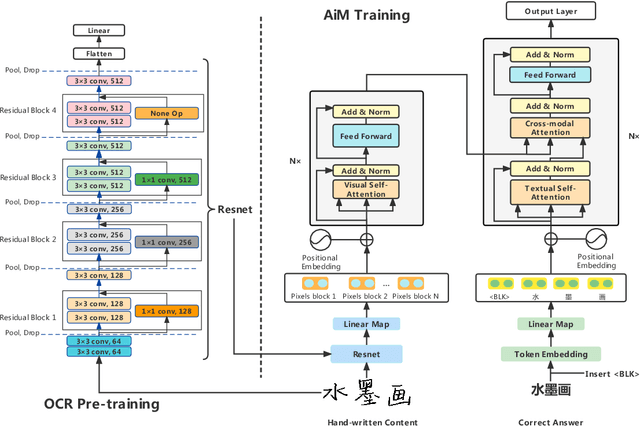
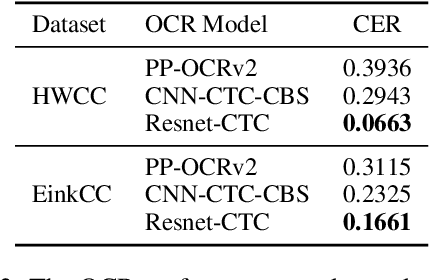
To automatically correct handwritten assignments, the traditional approach is to use an OCR model to recognize characters and compare them to answers. The OCR model easily gets confused on recognizing handwritten Chinese characters, and the textual information of the answers is missing during the model inference. However, teachers always have these answers in mind to review and correct assignments. In this paper, we focus on the Chinese cloze tests correction and propose a multimodal approach (named AiM). The encoded representations of answers interact with the visual information of students' handwriting. Instead of predicting 'right' or 'wrong', we perform the sequence labeling on the answer text to infer which answer character differs from the handwritten content in a fine-grained way. We take samples of OCR datasets as the positive samples for this task, and develop a negative sample augmentation method to scale up the training data. Experimental results show that AiM outperforms OCR-based methods by a large margin. Extensive studies demonstrate the effectiveness of our multimodal approach.
Seeking Patterns, Not just Memorizing Procedures: Contrastive Learning for Solving Math Word Problems
Oct 16, 2021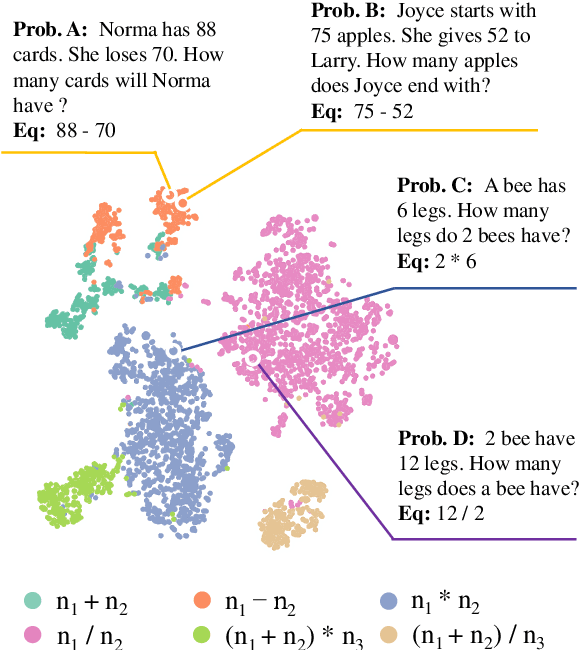

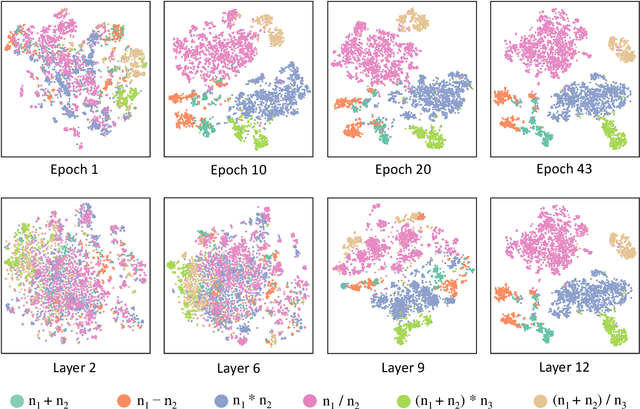
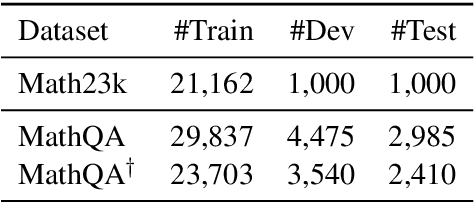
Math Word Problem (MWP) solving needs to discover the quantitative relationships over natural language narratives. Recent work shows that existing models memorize procedures from context and rely on shallow heuristics to solve MWPs. In this paper, we look at this issue and argue that the cause is a lack of overall understanding of MWP patterns. We first investigate how a neural network understands patterns only from semantics, and observe that, if the prototype equations are the same, most problems get closer representations and those representations apart from them or close to other prototypes tend to produce wrong solutions. Inspired by it, we propose a contrastive learning approach, where the neural network perceives the divergence of patterns. We collect contrastive examples by converting the prototype equation into a tree and seeking similar tree structures. The solving model is trained with an auxiliary objective on the collected examples, resulting in the representations of problems with similar prototypes being pulled closer. We conduct experiments on the Chinese dataset Math23k and the English dataset MathQA. Our method greatly improves the performance in monolingual and multilingual settings.
Relation-Aware Neighborhood Matching Model for Entity Alignment
Dec 15, 2020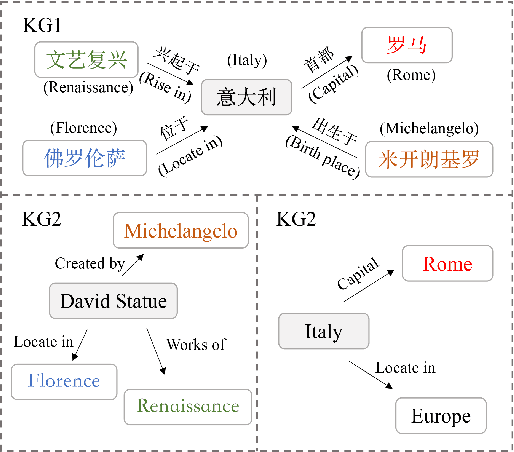
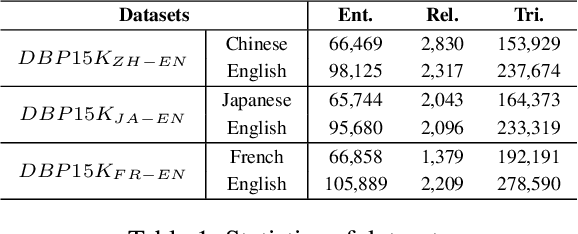
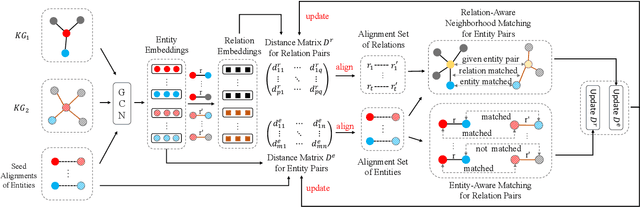
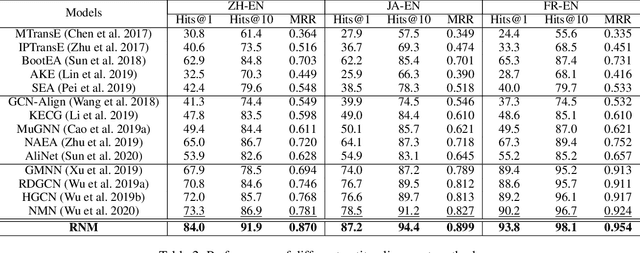
Entity alignment which aims at linking entities with the same meaning from different knowledge graphs (KGs) is a vital step for knowledge fusion. Existing research focused on learning embeddings of entities by utilizing structural information of KGs for entity alignment. These methods can aggregate information from neighboring nodes but may also bring noise from neighbors. Most recently, several researchers attempted to compare neighboring nodes in pairs to enhance the entity alignment. However, they ignored the relations between entities which are also important for neighborhood matching. In addition, existing methods paid less attention to the positive interactions between the entity alignment and the relation alignment. To deal with these issues, we propose a novel Relation-aware Neighborhood Matching model named RNM for entity alignment. Specifically, we propose to utilize the neighborhood matching to enhance the entity alignment. Besides comparing neighbor nodes when matching neighborhood, we also try to explore useful information from the connected relations. Moreover, an iterative framework is designed to leverage the positive interactions between the entity alignment and the relation alignment in a semi-supervised manner. Experimental results on three real-world datasets demonstrate that the proposed model RNM performs better than state-of-the-art methods.
LightPAFF: A Two-Stage Distillation Framework for Pre-training and Fine-tuning
Apr 27, 2020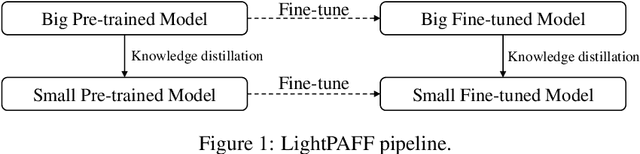
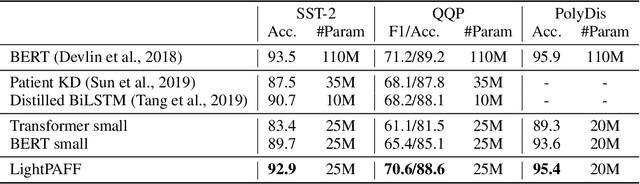

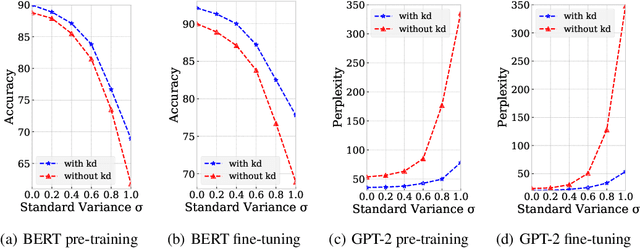
While pre-training and fine-tuning, e.g., BERT~\citep{devlin2018bert}, GPT-2~\citep{radford2019language}, have achieved great success in language understanding and generation tasks, the pre-trained models are usually too big for online deployment in terms of both memory cost and inference speed, which hinders them from practical online usage. In this paper, we propose LightPAFF, a Lightweight Pre-training And Fine-tuning Framework that leverages two-stage knowledge distillation to transfer knowledge from a big teacher model to a lightweight student model in both pre-training and fine-tuning stages. In this way the lightweight model can achieve similar accuracy as the big teacher model, but with much fewer parameters and thus faster online inference speed. LightPAFF can support different pre-training methods (such as BERT, GPT-2 and MASS~\citep{song2019mass}) and be applied to many downstream tasks. Experiments on three language understanding tasks, three language modeling tasks and three sequence to sequence generation tasks demonstrate that while achieving similar accuracy with the big BERT, GPT-2 and MASS models, LightPAFF reduces the model size by nearly 5x and improves online inference speed by 5x-7x.
Representation Learning with Ordered Relation Paths for Knowledge Graph Completion
Sep 26, 2019

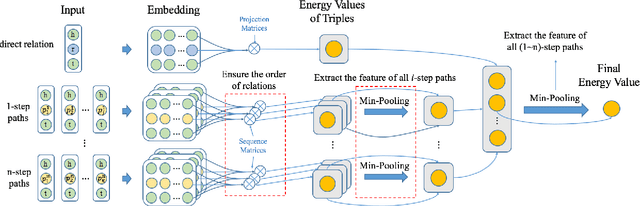
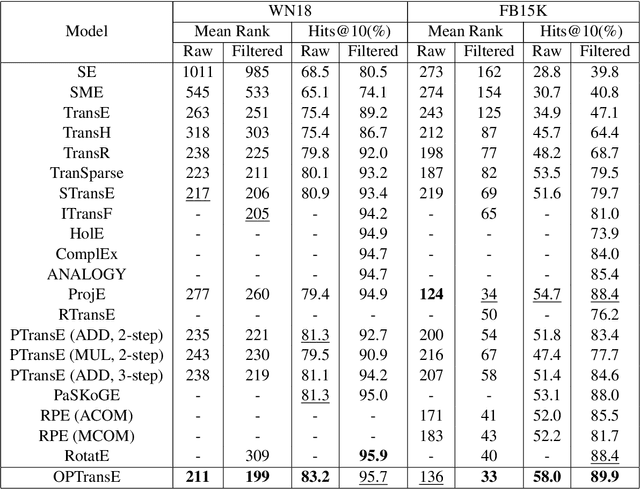
Incompleteness is a common problem for existing knowledge graphs (KGs), and the completion of KG which aims to predict links between entities is challenging. Most existing KG completion methods only consider the direct relation between nodes and ignore the relation paths which contain useful information for link prediction. Recently, a few methods take relation paths into consideration but pay less attention to the order of relations in paths which is important for reasoning. In addition, these path-based models always ignore nonlinear contributions of path features for link prediction. To solve these problems, we propose a novel KG completion method named OPTransE. Instead of embedding both entities of a relation into the same latent space as in previous methods, we project the head entity and the tail entity of each relation into different spaces to guarantee the order of relations in the path. Meanwhile, we adopt a pooling strategy to extract nonlinear and complex features of different paths to further improve the performance of link prediction. Experimental results on two benchmark datasets show that the proposed model OPTransE performs better than state-of-the-art methods.