 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSG-LegalCite: A Principle-Augmented Benchmark for Legal Citation Retrieval in Singapore Law
May 20, 2026Legal citation in common-law systems depends not only on factual similarity, but also on the legal principle for which a precedent is invoked. However, existing benchmarks for legal citation retrieval use case facts, citation context, or full judgments as inputs, where the governing legal principle is often missing or only implicitly expressed and entangled with broader context. As a result, models may retrieve precedents that are factually similar yet doctrinally irrelevant. This limitation is particularly consequential in Singapore, where the legal system has evolved independently: only domestic precedents are binding, while foreign authorities serve merely as persuasive references. Thus, we propose a new retrieval paradigm that ranks cited cases based on queries integrating case facts and explicit legal principles, inspired by real-world legal reasoning workflows. To support this paradigm, we introduce SG-LegalCite, a dataset of 100,890 case-principle pairs extracted from 8,523 Singapore Supreme Court judgments spanning from 2000 to 2025. Experiments across 11 baselines demonstrate the effectiveness of our principle-augmented retrieval paradigm, showing that explicit legal principles provide strong discriminative signals for legal citation retrieval.
Through Their Eyes: Fixation-aligned Tuning for Personalized User Emulation
Apr 10, 2026Large language model (LLM) agents are increasingly deployed as scalable user simulators for recommender system evaluation. Yet existing simulators perceive recommendations through text or structured metadata rather than the visual interfaces real users browse-a critical gap, since attention over recommendation layouts is both visually driven and highly personalized. We investigate whether aligning a vision-language model's (VLM's) visual attention with user-specific gaze patterns can improve simulation fidelity. Analysis of a real-world eye-tracking dataset collected in a carousel-based recommendation setting reveals that users exhibit stable individual gaze patterns strongly predictive of click behavior. Building on this finding, we propose Fixation-Aligned Tuning for user Emulation (FixATE). Our approach first probes the VLM's internal visual attention via interpretability operators to obtain a slot-level relevance distribution comparable with human fixation, and then learns personalized soft prompts to steer the model's attention toward each user's characteristic fixation pattern. Experiments across three interpretability-based probing operators and two architecturally distinct VLM backbones demonstrate consistent improvements in both attention alignment and click prediction accuracy. These results suggest that making the model "see like the user" is a viable path toward simulators that more faithfully reproduce how users perceive and act in recommendation interfaces.
Think When Needed: Model-Aware Reasoning Routing for LLM-based Ranking
Jan 26, 2026Large language models (LLMs) are increasingly applied to ranking tasks in retrieval and recommendation. Although reasoning prompting can enhance ranking utility, our preliminary exploration reveals that its benefits are inconsistent and come at a substantial computational cost, suggesting that when to reason is as crucial as how to reason. To address this issue, we propose a reasoning routing framework that employs a lightweight, plug-and-play router head to decide whether to use direct inference (Non-Think) or reasoning (Think) for each instance before generation. The router head relies solely on pre-generation signals: i) compact ranking-aware features (e.g., candidate dispersion) and ii) model-aware difficulty signals derived from a diagnostic checklist reflecting the model's estimated need for reasoning. By leveraging these features before generation, the router outputs a controllable token that determines whether to apply the Think mode. Furthermore, the router can adaptively select its operating policy along the validation Pareto frontier during deployment, enabling dynamic allocation of computational resources toward instances most likely to benefit from Think under varying system constraints. Experiments on three public ranking datasets with different scales of open-source LLMs show consistent improvements in ranking utility with reduced token consumption (e.g., +6.3\% NDCG@10 with -49.5\% tokens on MovieLens with Qwen3-4B), demonstrating reasoning routing as a practical solution to the accuracy-efficiency trade-off.
MMGRid: Navigating Temporal-aware and Cross-domain Generative Recommendation via Model Merging
Jan 22, 2026Model merging (MM) offers an efficient mechanism for integrating multiple specialized models without access to original training data or costly retraining. While MM has demonstrated success in domains like computer vision, its role in recommender systems (RSs) remains largely unexplored. Recently, Generative Recommendation (GR) has emerged as a new paradigm in RSs, characterized by rapidly growing model scales and substantial computational costs, making MM particularly appealing for cost-sensitive deployment scenarios. In this work, we present the first systematic study of MM in GR through a contextual lens. We focus on a fundamental yet underexplored challenge in real-world: how to merge generative recommenders specialized to different real-world contexts, arising from temporal evolving user behaviors and heterogeneous application domains. To this end, we propose a unified framework MMGRid, a structured contextual grid of GR checkpoints that organizes models trained under diverse contexts induced by temporal evolution and domain diversity. All checkpoints are derived from a shared base LLM but fine-tuned on context-specific data, forming a realistic and controlled model space for systematically analyzing MM across GR paradigms and merging algorithms. Our investigation reveals several key insights. First, training GR models from LLMs can introduce parameter conflicts during merging due to token distribution shifts and objective disparities; such conflicts can be alleviated by disentangling task-aware and context-specific parameter changes via base model replacement. Second, incremental training across contexts induces recency bias, which can be effectively balanced through weighted contextual merging. Notably, we observe that optimal merging weights correlate with context-dependent interaction characteristics, offering practical guidance for weight selection in real-world deployments.
Mirroring Users: Towards Building Preference-aligned User Simulator with User Feedback in Recommendation
Aug 25, 2025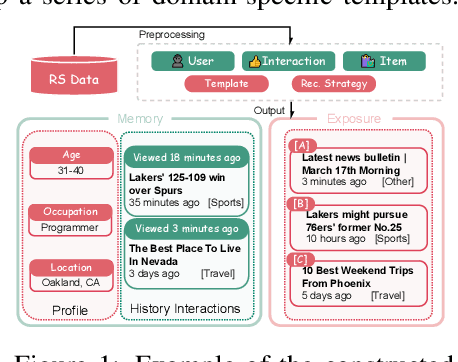
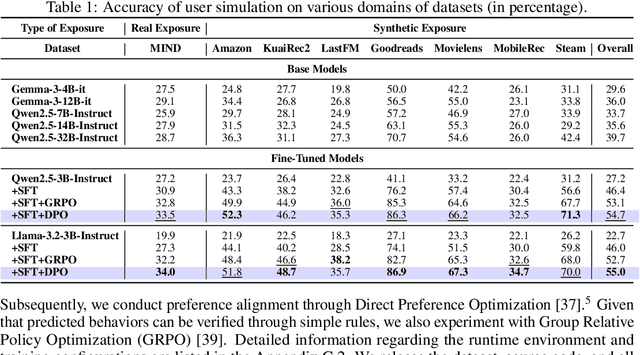
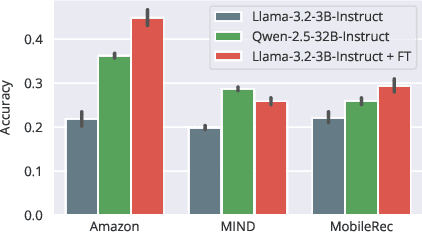
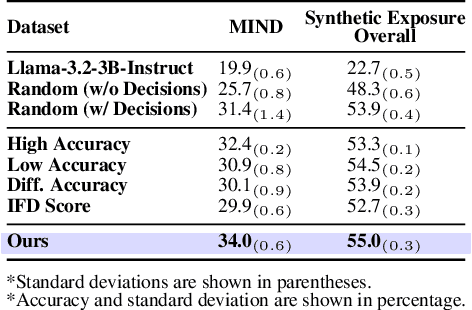
User simulation is increasingly vital to develop and evaluate recommender systems (RSs). While Large Language Models (LLMs) offer promising avenues to simulate user behavior, they often struggle with the absence of specific domain alignment required for RSs and the efficiency demands of large-scale simulation. A vast yet underutilized resource for enhancing this alignment is the extensive user feedback inherent in RSs. However, directly leveraging such feedback presents two significant challenges. First, user feedback in RSs is often ambiguous and noisy, which negatively impacts effective preference alignment. Second, the massive volume of feedback largely hinders the efficiency of preference alignment, necessitating an efficient filtering mechanism to identify more informative samples. To overcome these hurdles, we introduce a novel data construction framework that leverages user feedback in RSs with advanced LLM capabilities to generate high-quality simulation data. Our framework unfolds in two key phases: (1) employing LLMs to generate cognitive decision-making processes on constructed simulation samples, reducing ambiguity in raw user feedback; (2) data distillation based on uncertainty estimation and behavior sampling to filter challenging yet denoised simulation samples. Accordingly, we fine-tune lightweight LLMs, as user simulators, using such high-quality dataset with corresponding decision-making processes. Extensive experiments verify that our framework significantly boosts the alignment with human preferences and in-domain reasoning capabilities of fine-tuned LLMs, and provides more insightful and interpretable signals when interacting with RSs. We believe our work will advance the RS community and offer valuable insights for broader human-centric AI research.
Uncertain Multi-Objective Recommendation via Orthogonal Meta-Learning Enhanced Bayesian Optimization
Feb 18, 2025Recommender systems (RSs) play a crucial role in shaping our digital interactions, influencing how we access and engage with information across various domains. Traditional research has predominantly centered on maximizing recommendation accuracy, often leading to unintended side effects such as echo chambers and constrained user experiences. Drawing inspiration from autonomous driving, we introduce a novel framework that categorizes RS autonomy into five distinct levels, ranging from basic rule-based accuracy-driven systems to behavior-aware, uncertain multi-objective RSs - where users may have varying needs, such as accuracy, diversity, and fairness. In response, we propose an approach that dynamically identifies and optimizes multiple objectives based on individual user preferences, fostering more ethical and intelligent user-centric recommendations. To navigate the uncertainty inherent in multi-objective RSs, we develop a Bayesian optimization (BO) framework that captures personalized trade-offs between different objectives while accounting for their uncertain interdependencies. Furthermore, we introduce an orthogonal meta-learning paradigm to enhance BO efficiency and effectiveness by leveraging shared knowledge across similar tasks and mitigating conflicts among objectives through the discovery of orthogonal information. Finally, extensive empirical evaluations demonstrate the effectiveness of our method in optimizing uncertain multi-objectives for individual users, paving the way for more adaptive and user-focused RSs.
Re2LLM: Reflective Reinforcement Large Language Model for Session-based Recommendation
Mar 27, 2024



Large Language Models (LLMs) are emerging as promising approaches to enhance session-based recommendation (SBR), where both prompt-based and fine-tuning-based methods have been widely investigated to align LLMs with SBR. However, the former methods struggle with optimal prompts to elicit the correct reasoning of LLMs due to the lack of task-specific feedback, leading to unsatisfactory recommendations. Although the latter methods attempt to fine-tune LLMs with domain-specific knowledge, they face limitations such as high computational costs and reliance on open-source backbones. To address such issues, we propose a Reflective Reinforcement Large Language Model (Re2LLM) for SBR, guiding LLMs to focus on specialized knowledge essential for more accurate recommendations effectively and efficiently. In particular, we first design the Reflective Exploration Module to effectively extract knowledge that is readily understandable and digestible by LLMs. To be specific, we direct LLMs to examine recommendation errors through self-reflection and construct a knowledge base (KB) comprising hints capable of rectifying these errors. To efficiently elicit the correct reasoning of LLMs, we further devise the Reinforcement Utilization Module to train a lightweight retrieval agent. It learns to select hints from the constructed KB based on the task-specific feedback, where the hints can serve as guidance to help correct LLMs reasoning for better recommendations. Extensive experiments on multiple real-world datasets demonstrate that our method consistently outperforms state-of-the-art methods.
Large Language Model with Graph Convolution for Recommendation
Feb 14, 2024



In recent years, efforts have been made to use text information for better user profiling and item characterization in recommendations. However, text information can sometimes be of low quality, hindering its effectiveness for real-world applications. With knowledge and reasoning capabilities capsuled in Large Language Models (LLMs), utilizing LLMs emerges as a promising way for description improvement. However, existing ways of prompting LLMs with raw texts ignore structured knowledge of user-item interactions, which may lead to hallucination problems like inconsistent description generation. To this end, we propose a Graph-aware Convolutional LLM method to elicit LLMs to capture high-order relations in the user-item graph. To adapt text-based LLMs with structured graphs, We use the LLM as an aggregator in graph processing, allowing it to understand graph-based information step by step. Specifically, the LLM is required for description enhancement by exploring multi-hop neighbors layer by layer, thereby propagating information progressively in the graph. To enable LLMs to capture large-scale graph information, we break down the description task into smaller parts, which drastically reduces the context length of the token input with each step. Extensive experiments on three real-world datasets show that our method consistently outperforms state-of-the-art methods.
Bridging the Information Gap Between Domain-Specific Model and General LLM for Personalized Recommendation
Nov 07, 2023



Generative large language models(LLMs) are proficient in solving general problems but often struggle to handle domain-specific tasks. This is because most of domain-specific tasks, such as personalized recommendation, rely on task-related information for optimal performance. Current methods attempt to supplement task-related information to LLMs by designing appropriate prompts or employing supervised fine-tuning techniques. Nevertheless, these methods encounter the certain issue that information such as community behavior pattern in RS domain is challenging to express in natural language, which limits the capability of LLMs to surpass state-of-the-art domain-specific models. On the other hand, domain-specific models for personalized recommendation which mainly rely on user interactions are susceptible to data sparsity due to their limited common knowledge capabilities. To address these issues, we proposes a method to bridge the information gap between the domain-specific models and the general large language models. Specifically, we propose an information sharing module which serves as an information storage mechanism and also acts as a bridge for collaborative training between the LLMs and domain-specific models. By doing so, we can improve the performance of LLM-based recommendation with the help of user behavior pattern information mined by domain-specific models. On the other hand, the recommendation performance of domain-specific models can also be improved with the help of common knowledge learned by LLMs. Experimental results on three real-world datasets have demonstrated the effectiveness of the proposed method.
Enhancing Job Recommendation through LLM-based Generative Adversarial Networks
Jul 20, 2023
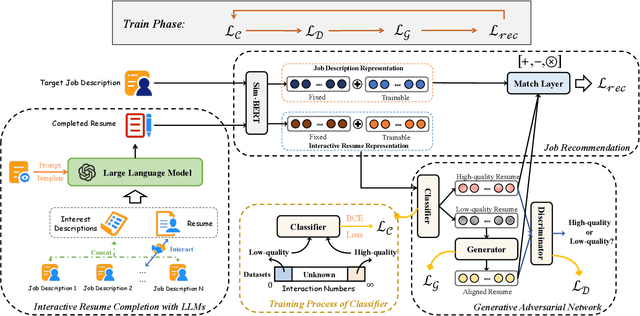


Recommending suitable jobs to users is a critical task in online recruitment platforms, as it can enhance users' satisfaction and the platforms' profitability. While existing job recommendation methods encounter challenges such as the low quality of users' resumes, which hampers their accuracy and practical effectiveness. With the rapid development of large language models (LLMs), utilizing the rich external knowledge encapsulated within them, as well as their powerful capabilities of text processing and reasoning, is a promising way to complete users' resumes for more accurate recommendations. However, directly leveraging LLMs to enhance recommendation results is not a one-size-fits-all solution, as LLMs may suffer from fabricated generation and few-shot problems, which degrade the quality of resume completion. In this paper, we propose a novel LLM-based approach for job recommendation. To alleviate the limitation of fabricated generation for LLMs, we extract accurate and valuable information beyond users' self-description, which helps the LLMs better profile users for resume completion. Specifically, we not only extract users' explicit properties (e.g., skills, interests) from their self-description but also infer users' implicit characteristics from their behaviors for more accurate and meaningful resume completion. Nevertheless, some users still suffer from few-shot problems, which arise due to scarce interaction records, leading to limited guidance for the models in generating high-quality resumes. To address this issue, we propose aligning unpaired low-quality with high-quality generated resumes by Generative Adversarial Networks (GANs), which can refine the resume representations for better recommendation results. Extensive experiments on three large real-world recruitment datasets demonstrate the effectiveness of our proposed method.