 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRASP: Gradient Realignment via Active Shared Perception for Multi-Agent Collaborative Optimization
Apr 01, 2026Non-stationarity arises from concurrent policy updates and leads to persistent environmental fluctuations. Existing approaches like Centralized Training with Decentralized Execution (CTDE) and sequential update schemes mitigate this issue. However, since the perception of the policies of other agents remains dependent on sampling environmental interaction data, the agent essentially operates in a passive perception state. This inevitably triggers equilibrium oscillations and significantly slows the convergence speed of the system. To address this issue, we propose Gradient Realignment via Active Shared Perception (GRASP), a novel framework that defines generalized Bellman equilibrium as a stable objective for policy evolution. The core mechanism of GRASP involves utilizing the independent gradients of agents to derive a defined consensus gradient, enabling agents to actively perceive policy updates and optimize team collaboration. Theoretically, we leverage the Kakutani Fixed-Point Theorem to prove that the consensus direction $u^*$ guarantees the existence and attainability of this equilibrium. Extensive experiments on StarCraft II Multi-Agent Challenge (SMAC) and Google Research Football (GRF) demonstrate the scalability and promising performance of the framework.
Taming the Instability: A Robust Second-Order Optimizer for Federated Learning over Non-IID Data
Mar 30, 2026In this paper, we present Federated Robust Curvature Optimization (FedRCO), a novel second-order optimization framework designed to improve convergence speed and reduce communication cost in Federated Learning systems under statistical heterogeneity. Existing second-order optimization methods are often computationally expensive and numerically unstable in distributed settings. In contrast, FedRCO addresses these challenges by integrating an efficient approximate curvature optimizer with a provable stability mechanism. Specifically, FedRCO incorporates three key components: (1) a Gradient Anomaly Monitor that detects and mitigates exploding gradients in real-time, (2) a Fail-Safe Resilience protocol that resets optimization states upon numerical instability, and (3) a Curvature-Preserving Adaptive Aggregation strategy that safely integrates global knowledge without erasing the local curvature geometry. Theoretical analysis shows that FedRCO can effectively mitigate instability and prevent unbounded updates while preserving optimization efficiency. Extensive experiments show that FedRCO achieves superior robustness against diverse non-IID scenarios while achieving higher accuracy and faster convergence than both state-of-the-art first-order and second-order methods.
Stabilized Fine-Tuning with LoRA in Federated Learning: Mitigating the Side Effect of Client Size and Rank via the Scaling Factor
Mar 09, 2026Large Language Models (LLMs) are pivotal in natural language processing. The impracticality of full fine-tuning has prompted Parameter-Efficient Fine-Tuning (PEFT) methods like Low-Rank Adaptation (LoRA), optimizing low-rank matrices A and B. In distributed scenarios where privacy constraints necessitate Federated Learning (FL), however, the integration of LoRA is often unstable. Specifically, we identify that aggregating updates from multiple clients introduces statistical variance that scales with the client count, causing gradient collapse when using high-rank adapters. Existing scaling factor candidates, such as the one used by Rank-Stabilized LoRA, ignore the interaction caused by the aggregation process. To bridge this gap, this paper introduces Stabilized Federated LoRA (SFed-LoRA), a framework that theoretically characterizes the interaction between adapter rank and federated aggregation. We derive an optimal scaling factor designed to effectively mitigate the aggregation error accumulating across N clients. By correcting the scaling mismatch inherent in previous approaches, SFed-LoRA restores the efficacy of high-rank adaptation without altering the original model architecture or increasing inference latency. Extensive experiments in diverse tasks, model architectures, and heterogeneous data distributions are conducted to validate our results. We demonstrate that SFed-LoRA prevents high-rank collapse, and achieves significantly improved stability and faster convergence compared with state-of-the-art baselines for high-rank adaptation.
Towards End-to-End Alignment of User Satisfaction via Questionnaire in Video Recommendation
Jan 28, 2026Short-video recommender systems typically optimize ranking models using dense user behavioral signals, such as clicks and watch time. However, these signals are only indirect proxies of user satisfaction and often suffer from noise and bias. Recently, explicit satisfaction feedback collected through questionnaires has emerged as a high-quality direct alignment supervision, but is extremely sparse and easily overwhelmed by abundant behavioral data, making it difficult to incorporate into online recommendation models. To address these challenges, we propose a novel framework which is towards End-to-End Alignment of user Satisfaction via Questionaire, named EASQ, to enable real-time alignment of ranking models with true user satisfaction. Specifically, we first construct an independent parameter pathway for sparse questionnaire signals by combining a multi-task architecture and a lightweight LoRA module. The multi-task design separates sparse satisfaction supervision from dense behavioral signals, preventing the former from being overwhelmed. The LoRA module pre-inject these preferences in a parameter-isolated manner, ensuring stability in the backbone while optimizing user satisfaction. Furthermore, we employ a DPO-based optimization objective tailored for online learning, which aligns the main model outputs with sparse satisfaction signals in real time. This design enables end-to-end online learning, allowing the model to continuously adapt to new questionnaire feedback while maintaining the stability and effectiveness of the backbone. Extensive offline experiments and large-scale online A/B tests demonstrate that EASQ consistently improves user satisfaction metrics across multiple scenarios. EASQ has been successfully deployed in a production short-video recommendation system, delivering significant and stable business gains.
LLM enhanced graph inference for long-term disease progression modelling
Nov 14, 2025Understanding the interactions between biomarkers among brain regions during neurodegenerative disease is essential for unravelling the mechanisms underlying disease progression. For example, pathophysiological models of Alzheimer's Disease (AD) typically describe how variables, such as regional levels of toxic proteins, interact spatiotemporally within a dynamical system driven by an underlying biological substrate, often based on brain connectivity. However, current methods grossly oversimplify the complex relationship between brain connectivity by assuming a single-modality brain connectome as the disease-spreading substrate. This leads to inaccurate predictions of pathology spread, especially during the long-term progression period. Meanhwile, other methods of learning such a graph in a purely data-driven way face the identifiability issue due to lack of proper constraint. We thus present a novel framework that uses Large Language Models (LLMs) as expert guides on the interaction of regional variables to enhance learning of disease progression from irregularly sampled longitudinal patient data. By leveraging LLMs' ability to synthesize multi-modal relationships and incorporate diverse disease-driving mechanisms, our method simultaneously optimizes 1) the construction of long-term disease trajectories from individual-level observations and 2) the biologically-constrained graph structure that captures interactions among brain regions with better identifiability. We demonstrate the new approach by estimating the pathology propagation using tau-PET imaging data from an Alzheimer's disease cohort. The new framework demonstrates superior prediction accuracy and interpretability compared to traditional approaches while revealing additional disease-driving factors beyond conventional connectivity measures.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
A Stage-Aware Mixture of Experts Framework for Neurodegenerative Disease Progression Modelling
Aug 09, 2025The long-term progression of neurodegenerative diseases is commonly conceptualized as a spatiotemporal diffusion process that consists of a graph diffusion process across the structural brain connectome and a localized reaction process within brain regions. However, modeling this progression remains challenging due to 1) the scarcity of longitudinal data obtained through irregular and infrequent subject visits and 2) the complex interplay of pathological mechanisms across brain regions and disease stages, where traditional models assume fixed mechanisms throughout disease progression. To address these limitations, we propose a novel stage-aware Mixture of Experts (MoE) framework that explicitly models how different contributing mechanisms dominate at different disease stages through time-dependent expert weighting.Data-wise, we utilize an iterative dual optimization method to properly estimate the temporal position of individual observations, constructing a co hort-level progression trajectory from irregular snapshots. Model-wise, we enhance the spatial component with an inhomogeneous graph neural diffusion model (IGND) that allows diffusivity to vary based on node states and time, providing more flexible representations of brain networks. We also introduce a localized neural reaction module to capture complex dynamics beyond standard processes.The resulting IGND-MoE model dynamically integrates these components across temporal states, offering a principled way to understand how stage-specific pathological mechanisms contribute to progression. The stage-wise weights yield novel clinical insights that align with literature, suggesting that graph-related processes are more influential at early stages, while other unknown physical processes become dominant later on.
An End-to-End Multi-objective Ensemble Ranking Framework for Video Recommendation
Aug 07, 2025We propose a novel End-to-end Multi-objective Ensemble Ranking framework (EMER) for the multi-objective ensemble ranking module, which is the most critical component of the short video recommendation system. EMER enhances personalization by replacing manually-designed heuristic formulas with an end-to-end modeling paradigm. EMER introduces a meticulously designed loss function to address the fundamental challenge of defining effective supervision for ensemble ranking, where no single ground-truth signal can fully capture user satisfaction. Moreover, EMER introduces novel sample organization method and transformer-based network architecture to capture the comparative relationships among candidates, which are critical for effective ranking. Additionally, we have proposed an offline-online consistent evaluation system to enhance the efficiency of offline model optimization, which is an established yet persistent challenge within the multi-objective ranking domain in industry. Abundant empirical tests are conducted on a real industrial dataset, and the results well demonstrate the effectiveness of our proposed framework. In addition, our framework has been deployed in the primary scenarios of Kuaishou, a short video recommendation platform with hundreds of millions of daily active users, achieving a 1.39% increase in overall App Stay Time and a 0.196% increase in 7-day user Lifetime(LT7), which are substantial improvements.
OneRec Technical Report
Jun 16, 2025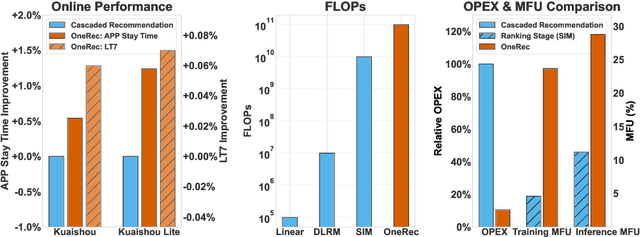

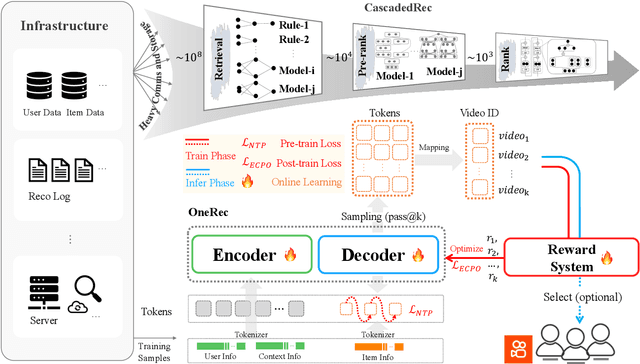

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Context-Adaptive Graph Neural Networks for Next POI Recommendation
Jun 12, 2025Next Point-of-Interest (POI) recommendation is a critical task in location-based services, aiming to predict users' next visits based on their check-in histories. While many existing methods leverage Graph Neural Networks (GNNs) to incorporate collaborative information and improve recommendation accuracy, most of them model each type of context using separate graphs, treating different factors in isolation. This limits their ability to model the co-influence of multiple contextual factors on user transitions during message propagation, resulting in suboptimal attention weights and recommendation performance. Furthermore, they often prioritize sequential components as the primary predictor, potentially undermining the semantic and structural information encoded in the POI embeddings learned by GNNs. To address these limitations, we propose a Context-Adaptive Graph Neural Networks (CAGNN) for next POI recommendation, which dynamically adjusts attention weights using edge-specific contextual factors and enables mutual enhancement between graph-based and sequential components. Specifically, CAGNN introduces (1) a context-adaptive attention mechanism that jointly incorporates different types of contextual factors into the attention computation during graph propagation, enabling the model to dynamically capture collaborative and context-dependent transition patterns; (2) a graph-sequential mutual enhancement module, which aligns the outputs of the graph- and sequential-based modules via the KL divergence, enabling mutual enhancement of both components. Experimental results on three real-world datasets demonstrate that CAGNN consistently outperforms state-of-the-art methods. Meanwhile, theoretical guarantees are provided that our context-adaptive attention mechanism improves the expressiveness of POI representations.