 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Prompt Mixture with Parameter-Free Routing for Federated Domain Generalization
Apr 29, 2025Federated domain generalization (FedDG) aims to learn a globally generalizable model from decentralized clients with heterogeneous data while preserving privacy. Recent studies have introduced prompt learning to adapt vision-language models (VLMs) in FedDG by learning a single global prompt. However, such a one-prompt-fits-all learning paradigm typically leads to performance degradation on personalized samples. Although the mixture of experts (MoE) offers a promising solution for specialization, existing MoE-based methods suffer from coarse image-level expert assignment and high communication costs from parameterized routers. To address these limitations, we propose TRIP, a Token-level prompt mixture with parameter-free routing framework for FedDG, which treats multiple prompts as distinct experts. Unlike existing image-level routing designs, TRIP assigns different tokens within an image to specific experts. To ensure communication efficiency, TRIP incorporates a parameter-free routing mechanism based on token clustering and optimal transport. The instance-specific prompt is then synthesized by aggregating experts, weighted by the number of tokens assigned to each. Additionally, TRIP develops an unbiased learning strategy for prompt experts, leveraging the VLM's zero-shot generalization capability. Extensive experiments across four benchmarks demonstrate that TRIP achieves optimal generalization results, with communication of only 1K parameters per round. Our code is available at https://github.com/GongShuai8210/TRIP.
Federated Domain Generalization via Prompt Learning and Aggregation
Nov 15, 2024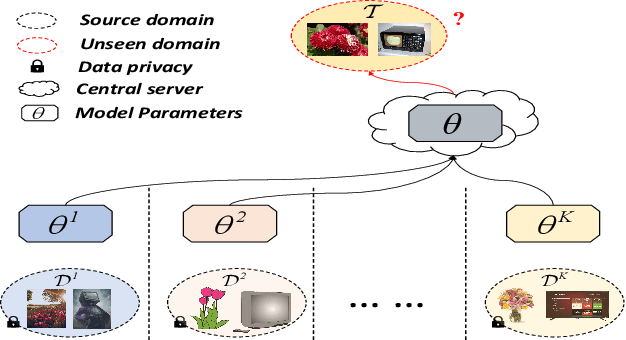
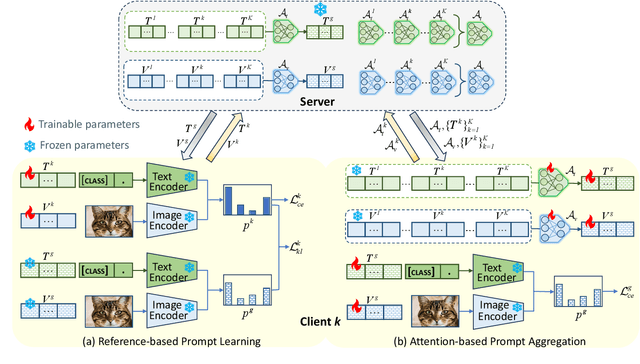
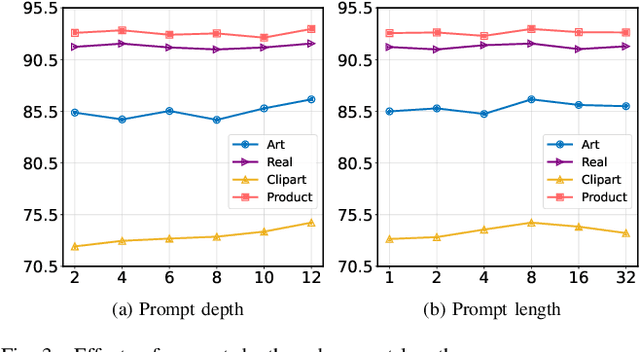
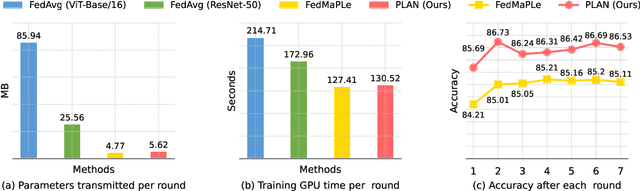
Federated domain generalization (FedDG) aims to improve the global model generalization in unseen domains by addressing data heterogeneity under privacy-preserving constraints. A common strategy in existing FedDG studies involves sharing domain-specific knowledge among clients, such as spectrum information, class prototypes, and data styles. However, this knowledge is extracted directly from local client samples, and sharing such sensitive information poses a potential risk of data leakage, which might not fully meet the requirements of FedDG. In this paper, we introduce prompt learning to adapt pre-trained vision-language models (VLMs) in the FedDG scenario, and leverage locally learned prompts as a more secure bridge to facilitate knowledge transfer among clients. Specifically, we propose a novel FedDG framework through Prompt Learning and AggregatioN (PLAN), which comprises two training stages to collaboratively generate local prompts and global prompts at each federated round. First, each client performs both text and visual prompt learning using their own data, with local prompts indirectly synchronized by regarding the global prompts as a common reference. Second, all domain-specific local prompts are exchanged among clients and selectively aggregated into the global prompts using lightweight attention-based aggregators. The global prompts are finally applied to adapt VLMs to unseen target domains. As our PLAN framework requires training only a limited number of prompts and lightweight aggregators, it offers notable advantages in computational and communication efficiency for FedDG. Extensive experiments demonstrate the superior generalization ability of PLAN across four benchmark datasets.
Improving Generalization in Meta-Learning via Meta-Gradient Augmentation
Jun 14, 2023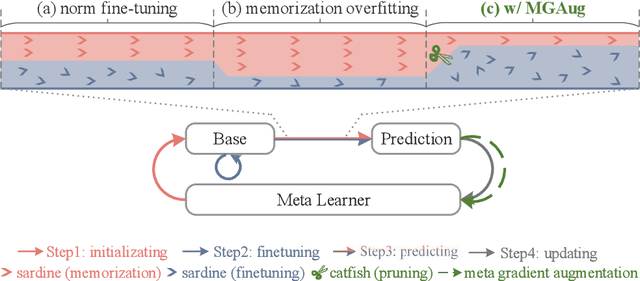
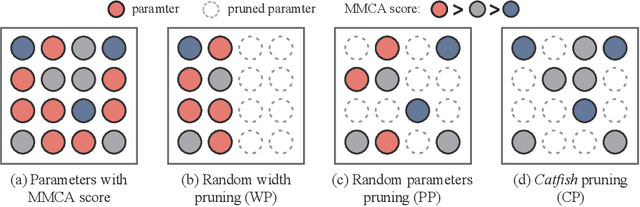
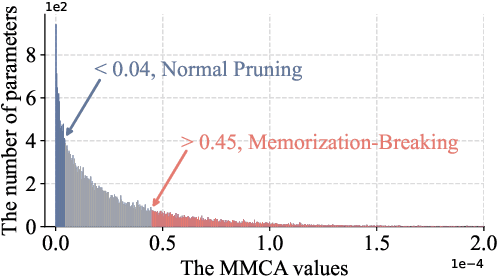
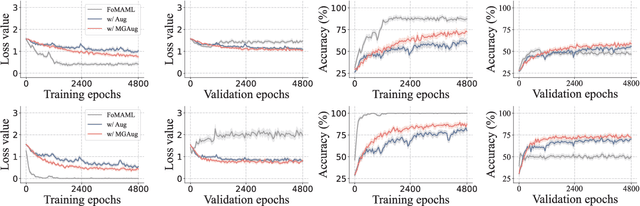
Meta-learning methods typically follow a two-loop framework, where each loop potentially suffers from notorious overfitting, hindering rapid adaptation and generalization to new tasks. Existing schemes solve it by enhancing the mutual-exclusivity or diversity of training samples, but these data manipulation strategies are data-dependent and insufficiently flexible. This work alleviates overfitting in meta-learning from the perspective of gradient regularization and proposes a data-independent \textbf{M}eta-\textbf{G}radient \textbf{Aug}mentation (\textbf{MGAug}) method. The key idea is to first break the rote memories by network pruning to address memorization overfitting in the inner loop, and then the gradients of pruned sub-networks naturally form the high-quality augmentation of the meta-gradient to alleviate learner overfitting in the outer loop. Specifically, we explore three pruning strategies, including \textit{random width pruning}, \textit{random parameter pruning}, and a newly proposed \textit{catfish pruning} that measures a Meta-Memorization Carrying Amount (MMCA) score for each parameter and prunes high-score ones to break rote memories as much as possible. The proposed MGAug is theoretically guaranteed by the generalization bound from the PAC-Bayes framework. In addition, we extend a lightweight version, called MGAug-MaxUp, as a trade-off between performance gains and resource overhead. Extensive experiments on multiple few-shot learning benchmarks validate MGAug's effectiveness and significant improvement over various meta-baselines. The code is publicly available at \url{https://github.com/xxLifeLover/Meta-Gradient-Augmentation}.
Exploring Linear Feature Disentanglement For Neural Networks
Mar 22, 2022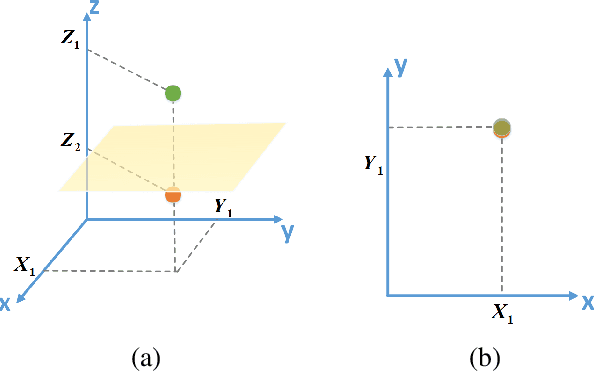

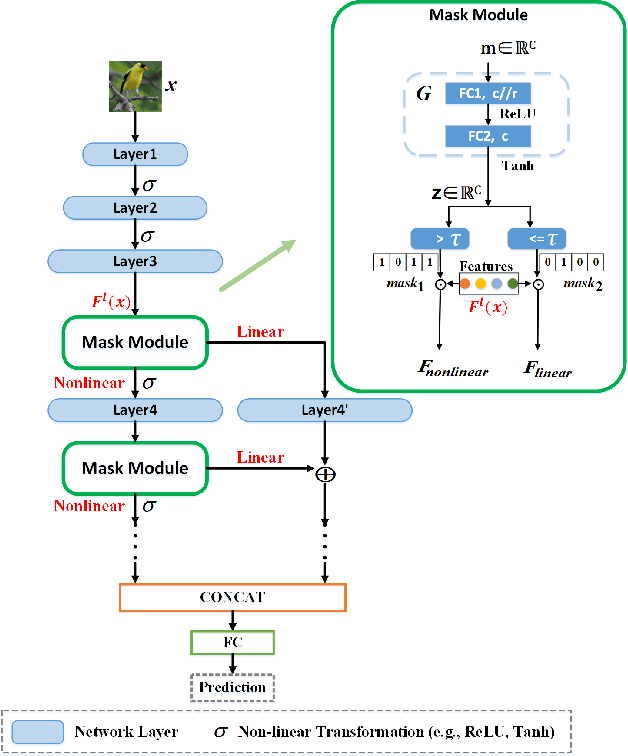

Non-linear activation functions, e.g., Sigmoid, ReLU, and Tanh, have achieved great success in neural networks (NNs). Due to the complex non-linear characteristic of samples, the objective of those activation functions is to project samples from their original feature space to a linear separable feature space. This phenomenon ignites our interest in exploring whether all features need to be transformed by all non-linear functions in current typical NNs, i.e., whether there exists a part of features arriving at the linear separable feature space in the intermediate layers, that does not require further non-linear variation but an affine transformation instead. To validate the above hypothesis, we explore the problem of linear feature disentanglement for neural networks in this paper. Specifically, we devise a learnable mask module to distinguish between linear and non-linear features. Through our designed experiments we found that some features reach the linearly separable space earlier than the others and can be detached partly from the NNs. The explored method also provides a readily feasible pruning strategy which barely affects the performance of the original model. We conduct our experiments on four datasets and present promising results.
Series Photo Selection via Multi-view Graph Learning
Mar 18, 2022
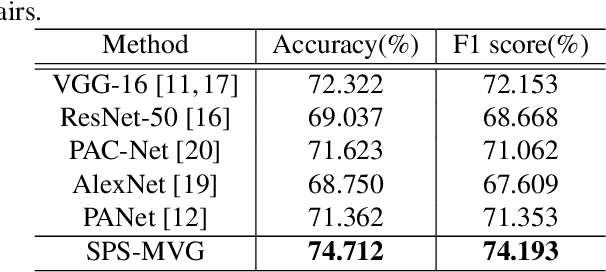
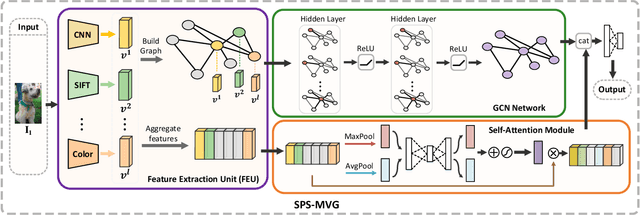

Series photo selection (SPS) is an important branch of the image aesthetics quality assessment, which focuses on finding the best one from a series of nearly identical photos. While a great progress has been observed, most of the existing SPS approaches concentrate solely on extracting features from the original image, neglecting that multiple views, e.g, saturation level, color histogram and depth of field of the image, will be of benefit to successfully reflecting the subtle aesthetic changes. Taken multi-view into consideration, we leverage a graph neural network to construct the relationships between multi-view features. Besides, multiple views are aggregated with an adaptive-weight self-attention module to verify the significance of each view. Finally, a siamese network is proposed to select the best one from a series of nearly identical photos. Experimental results demonstrate that our model accomplish the highest success rates compared with competitive methods.
Temporal-Relational Hypergraph Tri-Attention Networks for Stock Trend Prediction
Jul 22, 2021Predicting the future price trends of stocks is a challenging yet intriguing problem given its critical role to help investors make profitable decisions. In this paper, we present a collaborative temporal-relational modeling framework for end-to-end stock trend prediction. The temporal dynamics of stocks is firstly captured with an attention-based recurrent neural network. Then, different from existing studies relying on the pairwise correlations between stocks, we argue that stocks are naturally connected as a collective group, and introduce the hypergraph structures to jointly characterize the stock group-wise relationships of industry-belonging and fund-holding. A novel hypergraph tri-attention network (HGTAN) is proposed to augment the hypergraph convolutional networks with a hierarchical organization of intra-hyperedge, inter-hyperedge, and inter-hypergraph attention modules. In this manner, HGTAN adaptively determines the importance of nodes, hyperedges, and hypergraphs during the information propagation among stocks, so that the potential synergies between stock movements can be fully exploited. Extensive experiments on real-world data demonstrate the effectiveness of our approach. Also, the results of investment simulation show that our approach can achieve a more desirable risk-adjusted return. The data and codes of our work have been released at https://github.com/lixiaojieff/HGTAN.
A Survey on Natural Language Video Localization
Apr 01, 2021
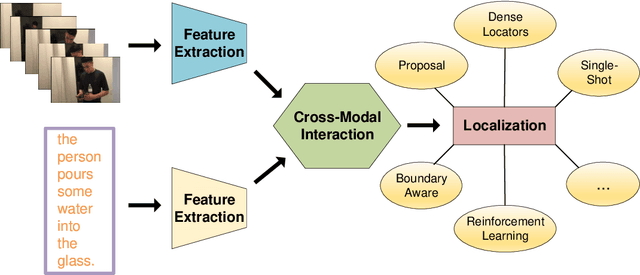


Natural language video localization (NLVL), which aims to locate a target moment from a video that semantically corresponds to a text query, is a novel and challenging task. Toward this end, in this paper, we present a comprehensive survey of the NLVL algorithms, where we first propose the pipeline of NLVL, and then categorize them into supervised and weakly-supervised methods, following by the analysis of the strengths and weaknesses of each kind of methods. Subsequently, we present the dataset, evaluation protocols and the general performance analysis. Finally, the possible perspectives are obtained by summarizing the existing methods.
Attention Model Enhanced Network for Classification of Breast Cancer Image
Oct 07, 2020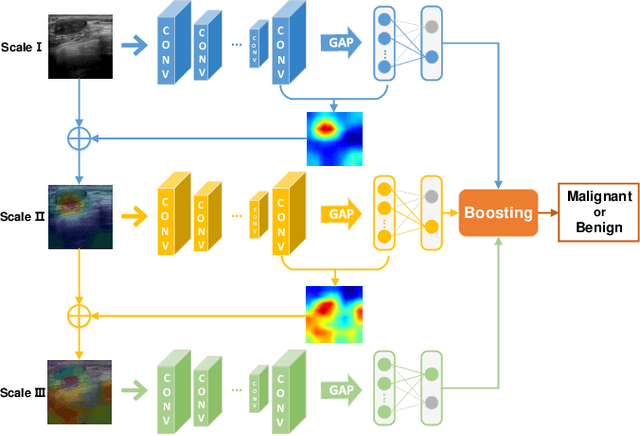
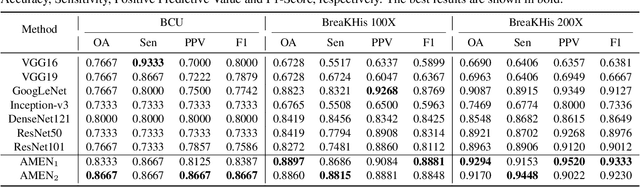
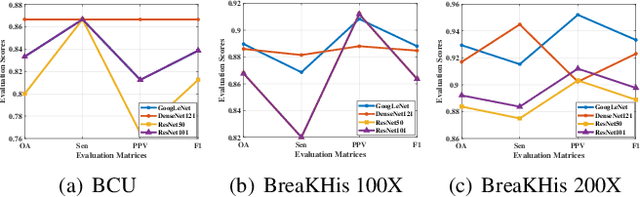
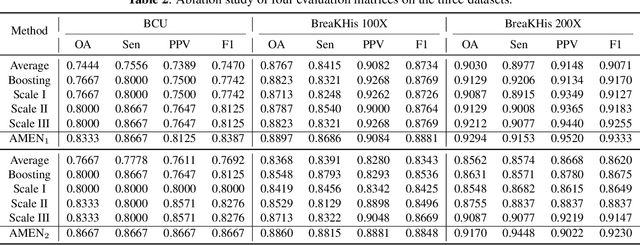
Breast cancer classification remains a challenging task due to inter-class ambiguity and intra-class variability. Existing deep learning-based methods try to confront this challenge by utilizing complex nonlinear projections. However, these methods typically extract global features from entire images, neglecting the fact that the subtle detail information can be crucial in extracting discriminative features. In this study, we propose a novel method named Attention Model Enhanced Network (AMEN), which is formulated in a multi-branch fashion with pixel-wised attention model and classification submodular. Specifically, the feature learning part in AMEN can generate pixel-wised attention map, while the classification submodular are utilized to classify the samples. To focus more on subtle detail information, the sample image is enhanced by the pixel-wised attention map generated from former branch. Furthermore, boosting strategy are adopted to fuse classification results from different branches for better performance. Experiments conducted on three benchmark datasets demonstrate the superiority of the proposed method under various scenarios.
Learning Binary Semantic Embedding for Histology Image Classification and Retrieval
Oct 07, 2020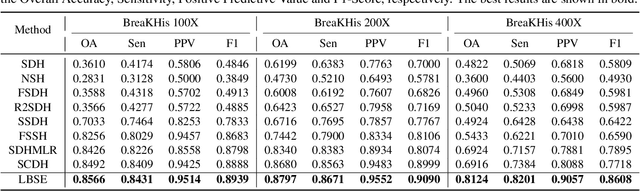
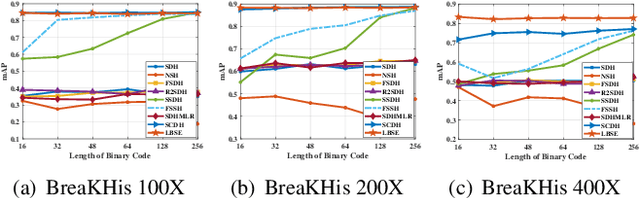
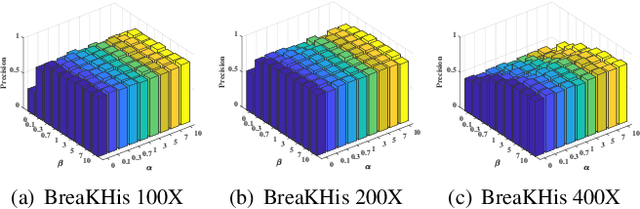
With the development of medical imaging technology and machine learning, computer-assisted diagnosis which can provide impressive reference to pathologists, attracts extensive research interests. The exponential growth of medical images and uninterpretability of traditional classification models have hindered the applications of computer-assisted diagnosis. To address these issues, we propose a novel method for Learning Binary Semantic Embedding (LBSE). Based on the efficient and effective embedding, classification and retrieval are performed to provide interpretable computer-assisted diagnosis for histology images. Furthermore, double supervision, bit uncorrelation and balance constraint, asymmetric strategy and discrete optimization are seamlessly integrated in the proposed method for learning binary embedding. Experiments conducted on three benchmark datasets validate the superiority of LBSE under various scenarios.
Reinforcing Short-Length Hashing
Apr 24, 2020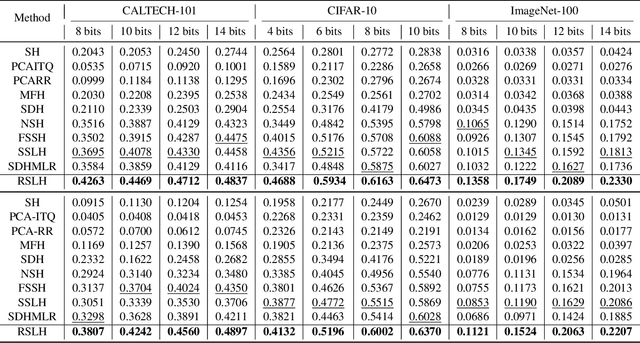
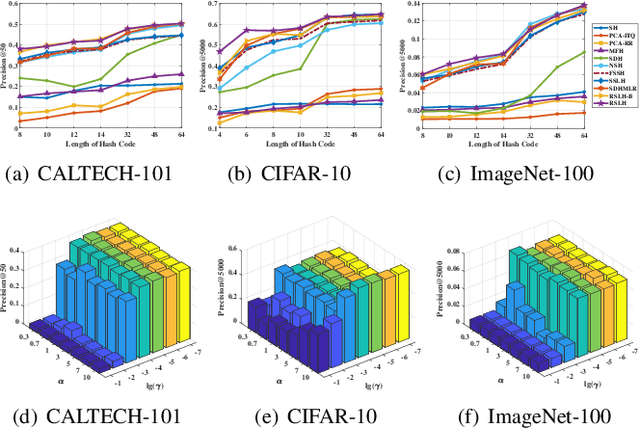
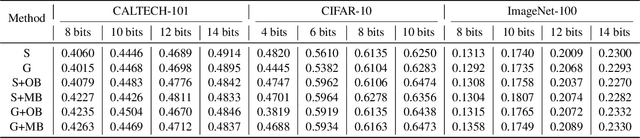
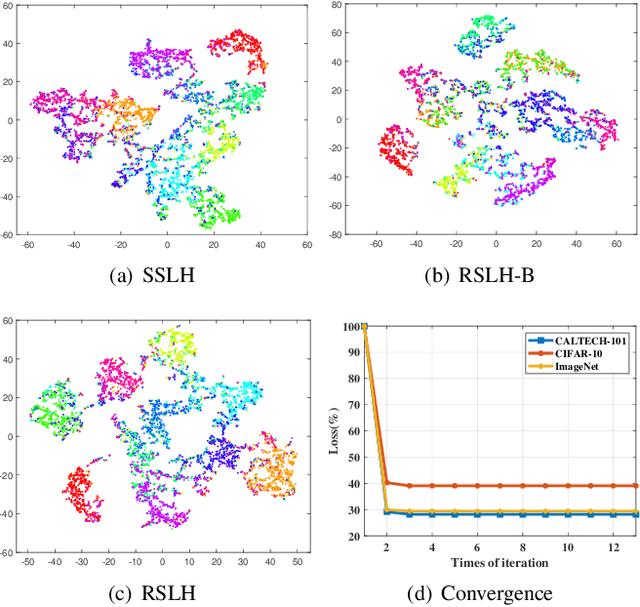
Due to the compelling efficiency in retrieval and storage, similarity-preserving hashing has been widely applied to approximate nearest neighbor search in large-scale image retrieval. However, existing methods have poor performance in retrieval using an extremely short-length hash code due to weak ability of classification and poor distribution of hash bit. To address this issue, in this study, we propose a novel reinforcing short-length hashing (RSLH). In this proposed RSLH, mutual reconstruction between the hash representation and semantic labels is performed to preserve the semantic information. Furthermore, to enhance the accuracy of hash representation, a pairwise similarity matrix is designed to make a balance between accuracy and training expenditure on memory. In addition, a parameter boosting strategy is integrated to reinforce the precision with hash bits fusion. Extensive experiments on three large-scale image benchmarks demonstrate the superior performance of RSLH under various short-length hashing scenarios.