 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Prompt Mixture with Parameter-Free Routing for Federated Domain Generalization
Apr 29, 2025Federated domain generalization (FedDG) aims to learn a globally generalizable model from decentralized clients with heterogeneous data while preserving privacy. Recent studies have introduced prompt learning to adapt vision-language models (VLMs) in FedDG by learning a single global prompt. However, such a one-prompt-fits-all learning paradigm typically leads to performance degradation on personalized samples. Although the mixture of experts (MoE) offers a promising solution for specialization, existing MoE-based methods suffer from coarse image-level expert assignment and high communication costs from parameterized routers. To address these limitations, we propose TRIP, a Token-level prompt mixture with parameter-free routing framework for FedDG, which treats multiple prompts as distinct experts. Unlike existing image-level routing designs, TRIP assigns different tokens within an image to specific experts. To ensure communication efficiency, TRIP incorporates a parameter-free routing mechanism based on token clustering and optimal transport. The instance-specific prompt is then synthesized by aggregating experts, weighted by the number of tokens assigned to each. Additionally, TRIP develops an unbiased learning strategy for prompt experts, leveraging the VLM's zero-shot generalization capability. Extensive experiments across four benchmarks demonstrate that TRIP achieves optimal generalization results, with communication of only 1K parameters per round. Our code is available at https://github.com/GongShuai8210/TRIP.
Dynamic Prompt Allocation and Tuning for Continual Test-Time Adaptation
Dec 12, 2024Continual test-time adaptation (CTTA) has recently emerged to adapt a pre-trained source model to continuously evolving target distributions, which accommodates the dynamic nature of real-world environments. To mitigate the risk of catastrophic forgetting in CTTA, existing methods typically incorporate explicit regularization terms to constrain the variation of model parameters. However, they cannot fundamentally resolve catastrophic forgetting because they rely on a single shared model to adapt across all target domains, which inevitably leads to severe inter-domain interference. In this paper, we introduce learnable domain-specific prompts that guide the model to adapt to corresponding target domains, thereby partially disentangling the parameter space of different domains. In the absence of domain identity for target samples, we propose a novel dynamic Prompt AllocatIon aNd Tuning (PAINT) method, which utilizes a query mechanism to dynamically determine whether the current samples come from a known domain or an unexplored one. For known domains, the corresponding domain-specific prompt is directly selected, while for previously unseen domains, a new prompt is allocated. Prompt tuning is subsequently performed using mutual information maximization along with structural regularization. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our PAINT method for CTTA. We have released our code at https://github.com/Cadezzyr/PAINT.
Federated Domain Generalization via Prompt Learning and Aggregation
Nov 15, 2024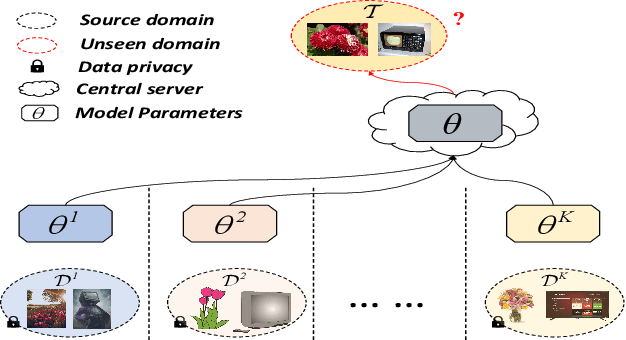
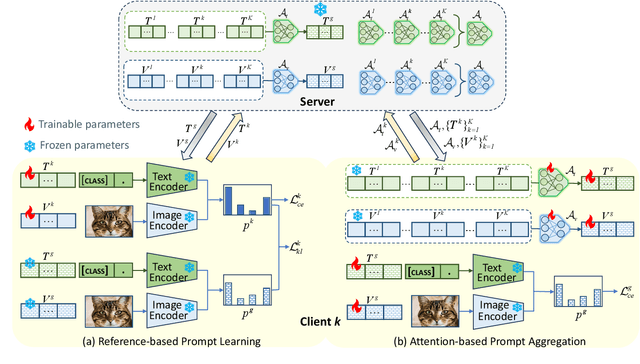
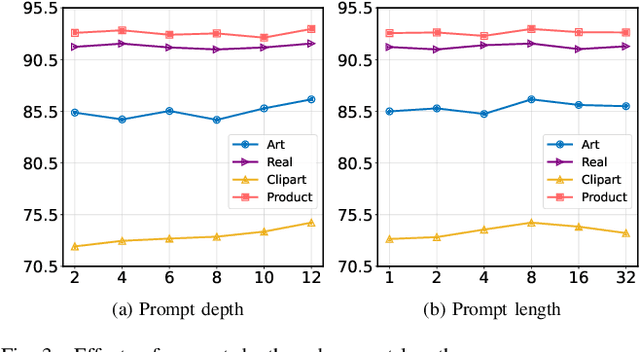
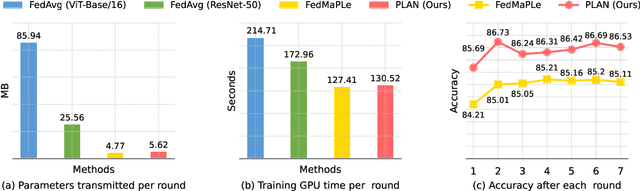
Federated domain generalization (FedDG) aims to improve the global model generalization in unseen domains by addressing data heterogeneity under privacy-preserving constraints. A common strategy in existing FedDG studies involves sharing domain-specific knowledge among clients, such as spectrum information, class prototypes, and data styles. However, this knowledge is extracted directly from local client samples, and sharing such sensitive information poses a potential risk of data leakage, which might not fully meet the requirements of FedDG. In this paper, we introduce prompt learning to adapt pre-trained vision-language models (VLMs) in the FedDG scenario, and leverage locally learned prompts as a more secure bridge to facilitate knowledge transfer among clients. Specifically, we propose a novel FedDG framework through Prompt Learning and AggregatioN (PLAN), which comprises two training stages to collaboratively generate local prompts and global prompts at each federated round. First, each client performs both text and visual prompt learning using their own data, with local prompts indirectly synchronized by regarding the global prompts as a common reference. Second, all domain-specific local prompts are exchanged among clients and selectively aggregated into the global prompts using lightweight attention-based aggregators. The global prompts are finally applied to adapt VLMs to unseen target domains. As our PLAN framework requires training only a limited number of prompts and lightweight aggregators, it offers notable advantages in computational and communication efficiency for FedDG. Extensive experiments demonstrate the superior generalization ability of PLAN across four benchmark datasets.
Do We Fully Understand Students' Knowledge States? Identifying and Mitigating Answer Bias in Knowledge Tracing
Aug 15, 2023



Knowledge tracing (KT) aims to monitor students' evolving knowledge states through their learning interactions with concept-related questions, and can be indirectly evaluated by predicting how students will perform on future questions. In this paper, we observe that there is a common phenomenon of answer bias, i.e., a highly unbalanced distribution of correct and incorrect answers for each question. Existing models tend to memorize the answer bias as a shortcut for achieving high prediction performance in KT, thereby failing to fully understand students' knowledge states. To address this issue, we approach the KT task from a causality perspective. A causal graph of KT is first established, from which we identify that the impact of answer bias lies in the direct causal effect of questions on students' responses. A novel COunterfactual REasoning (CORE) framework for KT is further proposed, which separately captures the total causal effect and direct causal effect during training, and mitigates answer bias by subtracting the latter from the former in testing. The CORE framework is applicable to various existing KT models, and we implement it based on the prevailing DKT, DKVMN, and AKT models, respectively. Extensive experiments on three benchmark datasets demonstrate the effectiveness of CORE in making the debiased inference for KT.
DGEKT: A Dual Graph Ensemble Learning Method for Knowledge Tracing
Nov 23, 2022


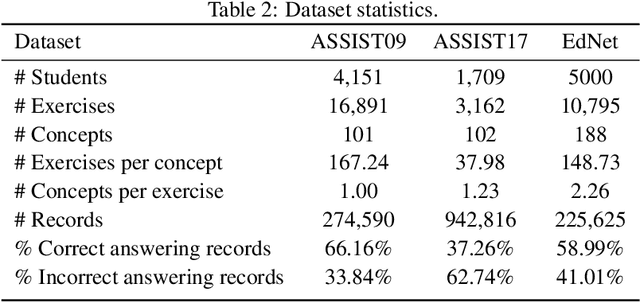
Knowledge tracing aims to trace students' evolving knowledge states by predicting their future performance on concept-related exercises. Recently, some graph-based models have been developed to incorporate the relationships between exercises to improve knowledge tracing, but only a single type of relationship information is generally explored. In this paper, we present a novel Dual Graph Ensemble learning method for Knowledge Tracing (DGEKT), which establishes a dual graph structure of students' learning interactions to capture the heterogeneous exercise-concept associations and interaction transitions by hypergraph modeling and directed graph modeling, respectively. To ensemble the dual graph models, we introduce the technique of online knowledge distillation, due to the fact that although the knowledge tracing model is expected to predict students' responses to the exercises related to different concepts, it is optimized merely with respect to the prediction accuracy on a single exercise at each step. With online knowledge distillation, the dual graph models are adaptively combined to form a stronger teacher model, which in turn provides its predictions on all exercises as extra supervision for better modeling ability. In the experiments, we compare DGEKT against eight knowledge tracing baselines on three benchmark datasets, and the results demonstrate that DGEKT achieves state-of-the-art performance.
Tri-Branch Convolutional Neural Networks for Top-$k$ Focused Academic Performance Prediction
Jul 22, 2021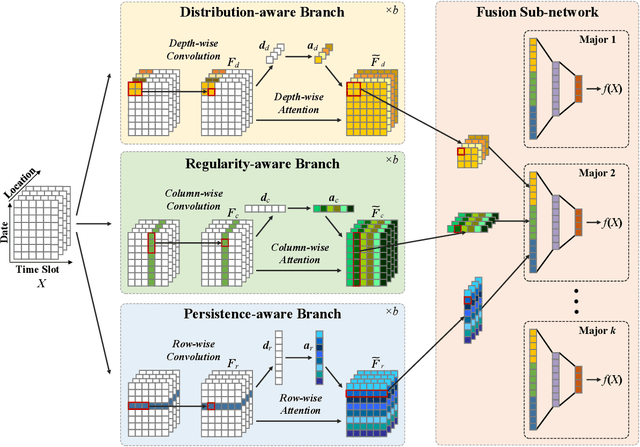
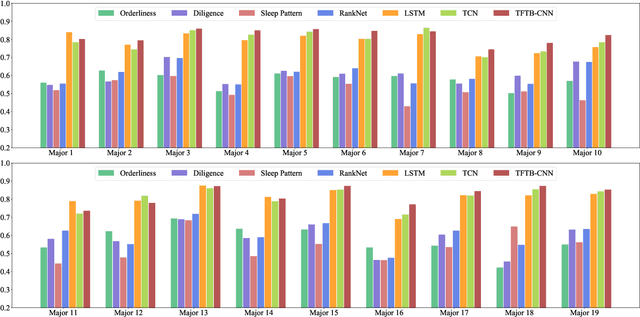
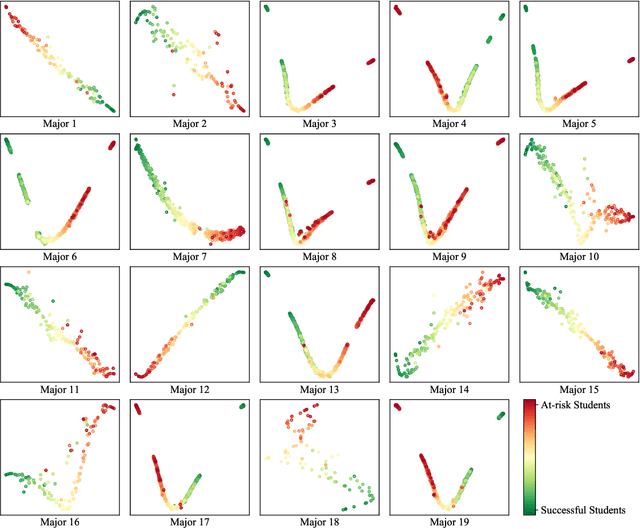

Academic performance prediction aims to leverage student-related information to predict their future academic outcomes, which is beneficial to numerous educational applications, such as personalized teaching and academic early warning. In this paper, we address the problem by analyzing students' daily behavior trajectories, which can be comprehensively tracked with campus smartcard records. Different from previous studies, we propose a novel Tri-Branch CNN architecture, which is equipped with row-wise, column-wise, and depth-wise convolution and attention operations, to capture the characteristics of persistence, regularity, and temporal distribution of student behavior in an end-to-end manner, respectively. Also, we cast academic performance prediction as a top-$k$ ranking problem, and introduce a top-$k$ focused loss to ensure the accuracy of identifying academically at-risk students. Extensive experiments were carried out on a large-scale real-world dataset, and we show that our approach substantially outperforms recently proposed methods for academic performance prediction. For the sake of reproducibility, our codes have been released at https://github.com/ZongJ1111/Academic-Performance-Prediction.
Temporal-Relational Hypergraph Tri-Attention Networks for Stock Trend Prediction
Jul 22, 2021Predicting the future price trends of stocks is a challenging yet intriguing problem given its critical role to help investors make profitable decisions. In this paper, we present a collaborative temporal-relational modeling framework for end-to-end stock trend prediction. The temporal dynamics of stocks is firstly captured with an attention-based recurrent neural network. Then, different from existing studies relying on the pairwise correlations between stocks, we argue that stocks are naturally connected as a collective group, and introduce the hypergraph structures to jointly characterize the stock group-wise relationships of industry-belonging and fund-holding. A novel hypergraph tri-attention network (HGTAN) is proposed to augment the hypergraph convolutional networks with a hierarchical organization of intra-hyperedge, inter-hyperedge, and inter-hypergraph attention modules. In this manner, HGTAN adaptively determines the importance of nodes, hyperedges, and hypergraphs during the information propagation among stocks, so that the potential synergies between stock movements can be fully exploited. Extensive experiments on real-world data demonstrate the effectiveness of our approach. Also, the results of investment simulation show that our approach can achieve a more desirable risk-adjusted return. The data and codes of our work have been released at https://github.com/lixiaojieff/HGTAN.
Towards Accurate and Robust Domain Adaptation under Noisy Environments
May 05, 2020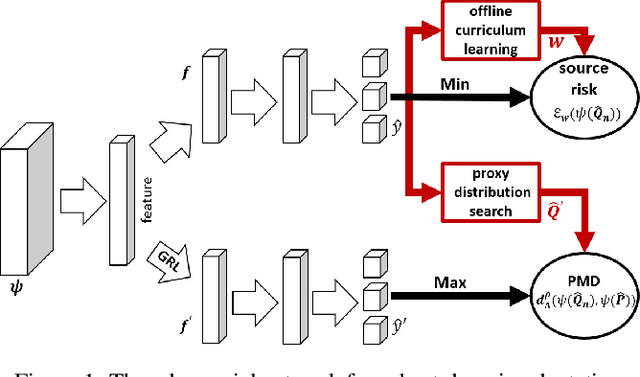

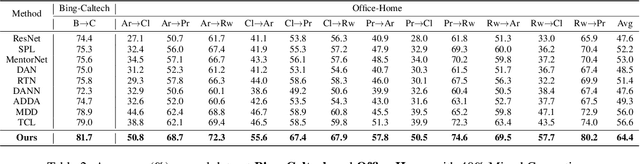
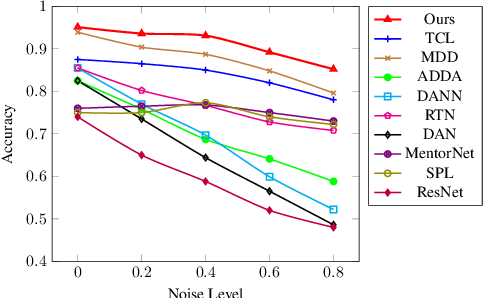
In non-stationary environments, learning machines usually confront the domain adaptation scenario where the data distribution does change over time. Previous domain adaptation works have achieved great success in theory and practice. However, they always lose robustness in noisy environments where the labels and features of examples from the source domain become corrupted. In this paper, we report our attempt towards achieving accurate noise-robust domain adaptation. We first give a theoretical analysis that reveals how harmful noises influence unsupervised domain adaptation. To eliminate the effect of label noise, we propose an offline curriculum learning for minimizing a newly-defined empirical source risk. To reduce the impact of feature noise, we propose a proxy distribution based margin discrepancy. We seamlessly transform our methods into an adversarial network that performs efficient joint optimization for them, successfully mitigating the negative influence from both data corruption and distribution shift. A series of empirical studies show that our algorithm remarkably outperforms state of the art, over 10% accuracy improvements in some domain adaptation tasks under noisy environments.