 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVM: Towards Structure-Preserving Neural Response Modeling in the Visual Cortex Across Stimuli and Individuals
Dec 17, 2025While deep learning models have shown strong performance in simulating neural responses, they often fail to clearly separate stable visual encoding from condition-specific adaptation, which limits their ability to generalize across stimuli and individuals. We introduce the Adaptive Visual Model (AVM), a structure-preserving framework that enables condition-aware adaptation through modular subnetworks, without modifying the core representation. AVM keeps a Vision Transformer-based encoder frozen to capture consistent visual features, while independently trained modulation paths account for neural response variations driven by stimulus content and subject identity. We evaluate AVM in three experimental settings, including stimulus-level variation, cross-subject generalization, and cross-dataset adaptation, all of which involve structured changes in inputs and individuals. Across two large-scale mouse V1 datasets, AVM outperforms the state-of-the-art V1T model by approximately 2% in predictive correlation, demonstrating robust generalization, interpretable condition-wise modulation, and high architectural efficiency. Specifically, AVM achieves a 9.1% improvement in explained variance (FEVE) under the cross-dataset adaptation setting. These results suggest that AVM provides a unified framework for adaptive neural modeling across biological and experimental conditions, offering a scalable solution under structural constraints. Its design may inform future approaches to cortical modeling in both neuroscience and biologically inspired AI systems.
Flower Across Time and Media: Sentiment Analysis of Tang Song Poetry and Visual Correspondence
May 07, 2025
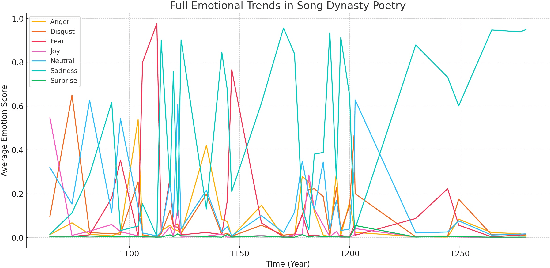


The Tang (618 to 907) and Song (960 to 1279) dynasties witnessed an extraordinary flourishing of Chinese cultural expression, where floral motifs served as a dynamic medium for both poetic sentiment and artistic design. While previous scholarship has examined these domains independently, the systematic correlation between evolving literary emotions and visual culture remains underexplored. This study addresses that gap by employing BERT-based sentiment analysis to quantify emotional patterns in floral imagery across Tang Song poetry, then validating these patterns against contemporaneous developments in decorative arts.Our approach builds upon recent advances in computational humanities while remaining grounded in traditional sinological methods. By applying a fine tuned BERT model to analyze peony and plum blossom imagery in classical poetry, we detect measurable shifts in emotional connotations between the Tang and Song periods. These textual patterns are then cross berenced with visual evidence from textiles, ceramics, and other material culture, revealing previously unrecognized synergies between literary expression and artistic representation.
Token-Level Prompt Mixture with Parameter-Free Routing for Federated Domain Generalization
Apr 29, 2025Federated domain generalization (FedDG) aims to learn a globally generalizable model from decentralized clients with heterogeneous data while preserving privacy. Recent studies have introduced prompt learning to adapt vision-language models (VLMs) in FedDG by learning a single global prompt. However, such a one-prompt-fits-all learning paradigm typically leads to performance degradation on personalized samples. Although the mixture of experts (MoE) offers a promising solution for specialization, existing MoE-based methods suffer from coarse image-level expert assignment and high communication costs from parameterized routers. To address these limitations, we propose TRIP, a Token-level prompt mixture with parameter-free routing framework for FedDG, which treats multiple prompts as distinct experts. Unlike existing image-level routing designs, TRIP assigns different tokens within an image to specific experts. To ensure communication efficiency, TRIP incorporates a parameter-free routing mechanism based on token clustering and optimal transport. The instance-specific prompt is then synthesized by aggregating experts, weighted by the number of tokens assigned to each. Additionally, TRIP develops an unbiased learning strategy for prompt experts, leveraging the VLM's zero-shot generalization capability. Extensive experiments across four benchmarks demonstrate that TRIP achieves optimal generalization results, with communication of only 1K parameters per round. Our code is available at https://github.com/GongShuai8210/TRIP.
Dynamic Prompt Allocation and Tuning for Continual Test-Time Adaptation
Dec 12, 2024Continual test-time adaptation (CTTA) has recently emerged to adapt a pre-trained source model to continuously evolving target distributions, which accommodates the dynamic nature of real-world environments. To mitigate the risk of catastrophic forgetting in CTTA, existing methods typically incorporate explicit regularization terms to constrain the variation of model parameters. However, they cannot fundamentally resolve catastrophic forgetting because they rely on a single shared model to adapt across all target domains, which inevitably leads to severe inter-domain interference. In this paper, we introduce learnable domain-specific prompts that guide the model to adapt to corresponding target domains, thereby partially disentangling the parameter space of different domains. In the absence of domain identity for target samples, we propose a novel dynamic Prompt AllocatIon aNd Tuning (PAINT) method, which utilizes a query mechanism to dynamically determine whether the current samples come from a known domain or an unexplored one. For known domains, the corresponding domain-specific prompt is directly selected, while for previously unseen domains, a new prompt is allocated. Prompt tuning is subsequently performed using mutual information maximization along with structural regularization. Extensive experiments on three benchmark datasets demonstrate the effectiveness of our PAINT method for CTTA. We have released our code at https://github.com/Cadezzyr/PAINT.
Federated Domain Generalization via Prompt Learning and Aggregation
Nov 15, 2024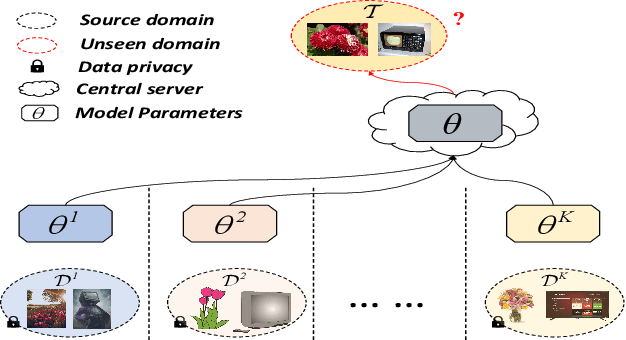
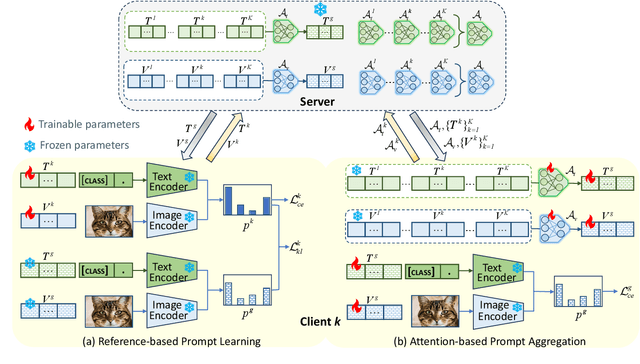
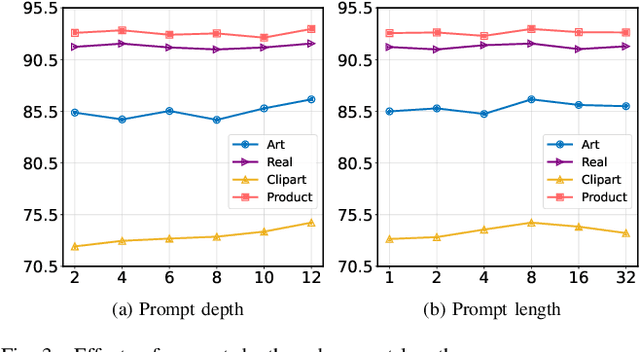
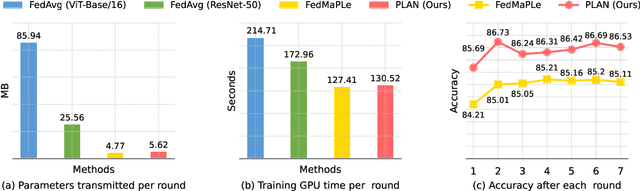
Federated domain generalization (FedDG) aims to improve the global model generalization in unseen domains by addressing data heterogeneity under privacy-preserving constraints. A common strategy in existing FedDG studies involves sharing domain-specific knowledge among clients, such as spectrum information, class prototypes, and data styles. However, this knowledge is extracted directly from local client samples, and sharing such sensitive information poses a potential risk of data leakage, which might not fully meet the requirements of FedDG. In this paper, we introduce prompt learning to adapt pre-trained vision-language models (VLMs) in the FedDG scenario, and leverage locally learned prompts as a more secure bridge to facilitate knowledge transfer among clients. Specifically, we propose a novel FedDG framework through Prompt Learning and AggregatioN (PLAN), which comprises two training stages to collaboratively generate local prompts and global prompts at each federated round. First, each client performs both text and visual prompt learning using their own data, with local prompts indirectly synchronized by regarding the global prompts as a common reference. Second, all domain-specific local prompts are exchanged among clients and selectively aggregated into the global prompts using lightweight attention-based aggregators. The global prompts are finally applied to adapt VLMs to unseen target domains. As our PLAN framework requires training only a limited number of prompts and lightweight aggregators, it offers notable advantages in computational and communication efficiency for FedDG. Extensive experiments demonstrate the superior generalization ability of PLAN across four benchmark datasets.
A Single-Step Non-Autoregressive Automatic Speech Recognition Architecture with High Accuracy and Inference Speed
Jun 13, 2024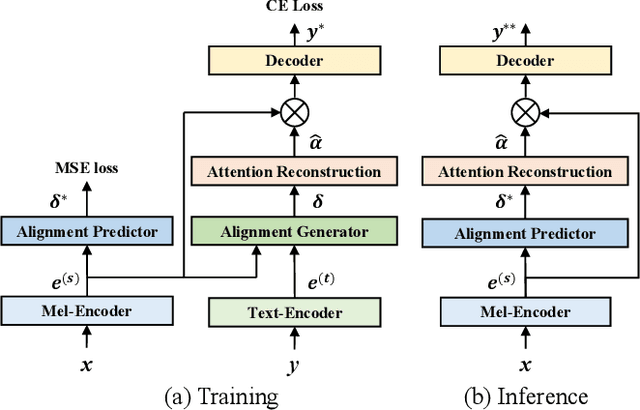
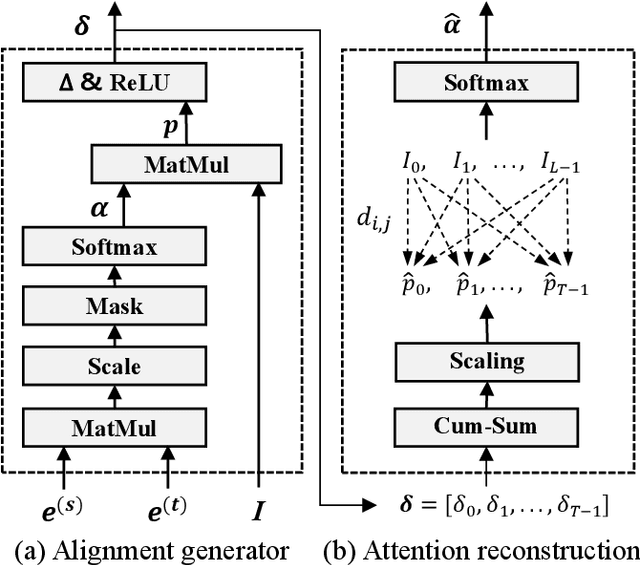
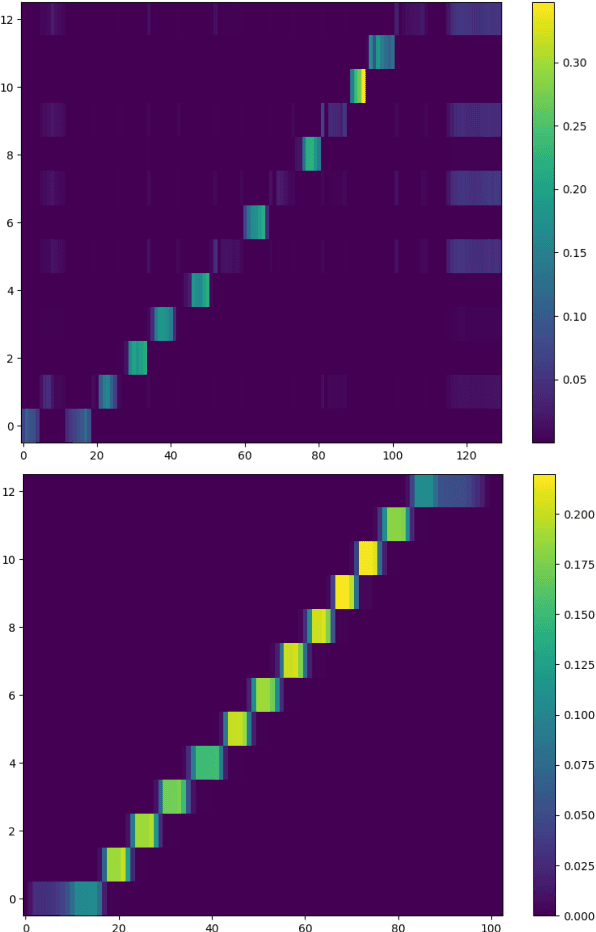
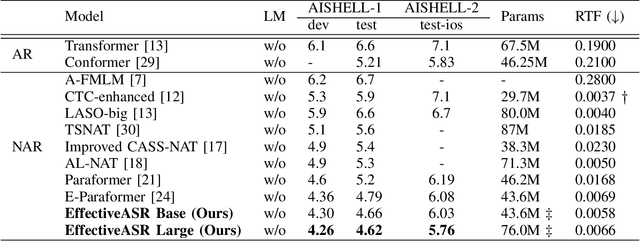
Non-autoregressive (NAR) automatic speech recognition (ASR) models predict tokens independently and simultaneously, bringing high inference speed. However, there is still a gap in the accuracy of the NAR models compared to the autoregressive (AR) models. To further narrow the gap between the NAR and AR models, we propose a single-step NAR ASR architecture with high accuracy and inference speed, called EfficientASR. It uses an Index Mapping Vector (IMV) based alignment generator to generate alignments during training, and an alignment predictor to learn the alignments for inference. It can be trained end-to-end (E2E) with cross-entropy loss combined with alignment loss. The proposed EfficientASR achieves competitive results on the AISHELL-1 and AISHELL-2 benchmarks compared to the state-of-the-art (SOTA) models. Specifically, it achieves character error rates (CER) of 4.26%/4.62% on the AISHELL-1 dev/test dataset, which outperforms the SOTA AR Conformer with about 30x inference speedup.