 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Single-Step Non-Autoregressive Automatic Speech Recognition Architecture with High Accuracy and Inference Speed
Jun 13, 2024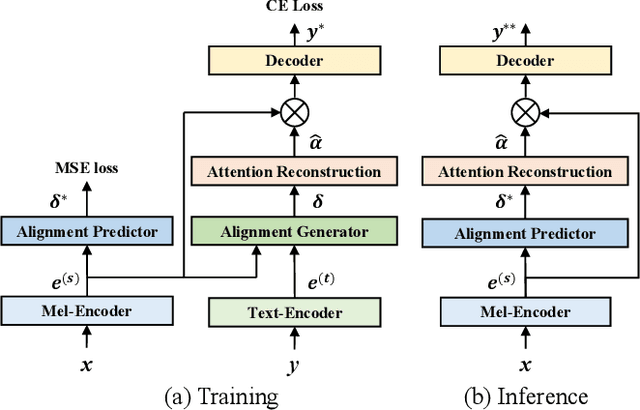
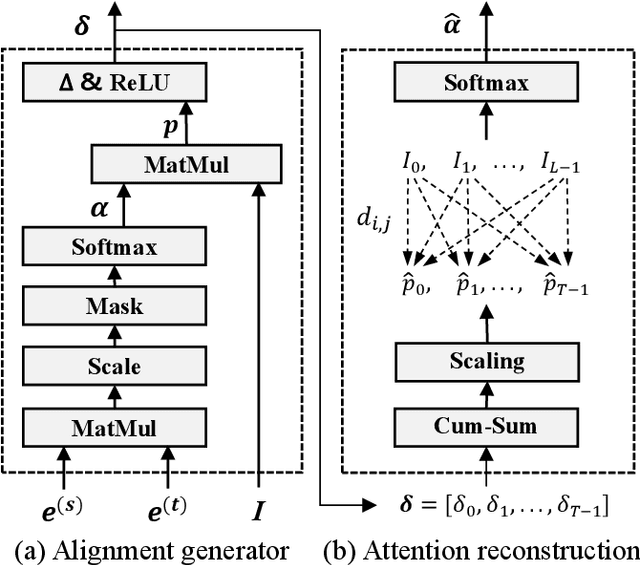
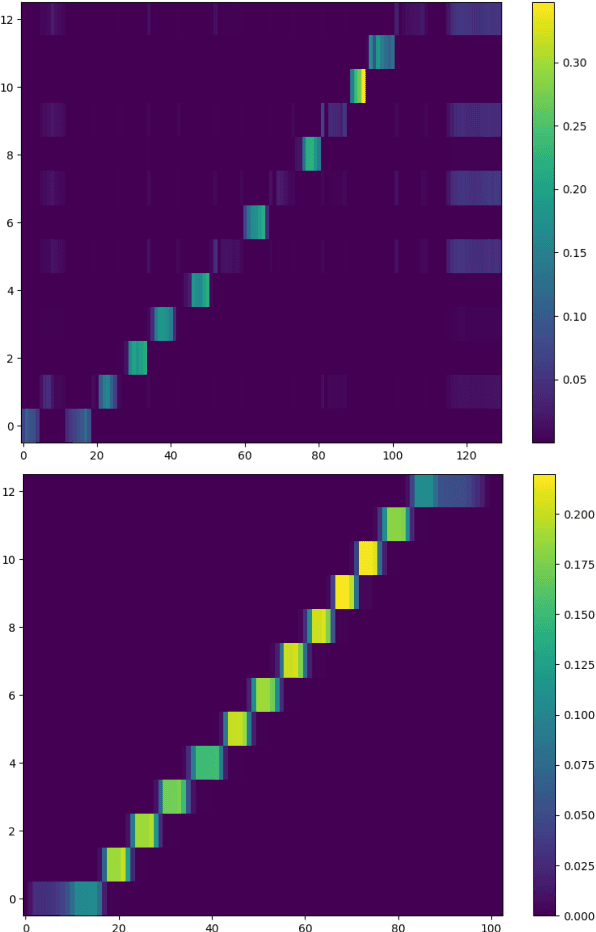
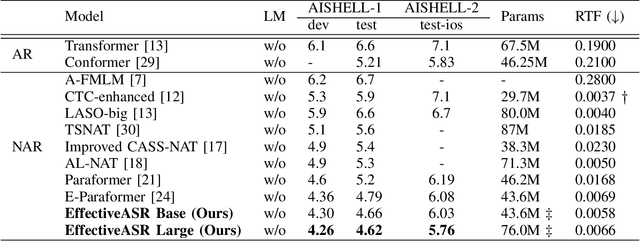
Non-autoregressive (NAR) automatic speech recognition (ASR) models predict tokens independently and simultaneously, bringing high inference speed. However, there is still a gap in the accuracy of the NAR models compared to the autoregressive (AR) models. To further narrow the gap between the NAR and AR models, we propose a single-step NAR ASR architecture with high accuracy and inference speed, called EfficientASR. It uses an Index Mapping Vector (IMV) based alignment generator to generate alignments during training, and an alignment predictor to learn the alignments for inference. It can be trained end-to-end (E2E) with cross-entropy loss combined with alignment loss. The proposed EfficientASR achieves competitive results on the AISHELL-1 and AISHELL-2 benchmarks compared to the state-of-the-art (SOTA) models. Specifically, it achieves character error rates (CER) of 4.26%/4.62% on the AISHELL-1 dev/test dataset, which outperforms the SOTA AR Conformer with about 30x inference speedup.