 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Visual Representation for Text-based Person Searching
Dec 30, 2024



Text-based person search aims to retrieve the matched pedestrians from a large-scale image database according to the text description. The core difficulty of this task is how to extract effective details from pedestrian images and texts, and achieve cross-modal alignment in a common latent space. Prior works adopt image and text encoders pre-trained on unimodal data to extract global and local features from image and text respectively, and then global-local alignment is achieved explicitly. However, these approaches still lack the ability of understanding visual details, and the retrieval accuracy is still limited by identity confusion. In order to alleviate the above problems, we rethink the importance of visual features for text-based person search, and propose VFE-TPS, a Visual Feature Enhanced Text-based Person Search model. It introduces a pre-trained multimodal backbone CLIP to learn basic multimodal features and constructs Text Guided Masked Image Modeling task to enhance the model's ability of learning local visual details without explicit annotation. In addition, we design Identity Supervised Global Visual Feature Calibration task to guide the model learn identity-aware global visual features. The key finding of our study is that, with the help of our proposed auxiliary tasks, the knowledge embedded in the pre-trained CLIP model can be successfully adapted to text-based person search task, and the model's visual understanding ability is significantly enhanced. Experimental results on three benchmarks demonstrate that our proposed model exceeds the existing approaches, and the Rank-1 accuracy is significantly improved with a notable margin of about $1\%\sim9\%$. Our code can be found at https://github.com/zhangweifeng1218/VFE_TPS.
A Single-Step Non-Autoregressive Automatic Speech Recognition Architecture with High Accuracy and Inference Speed
Jun 13, 2024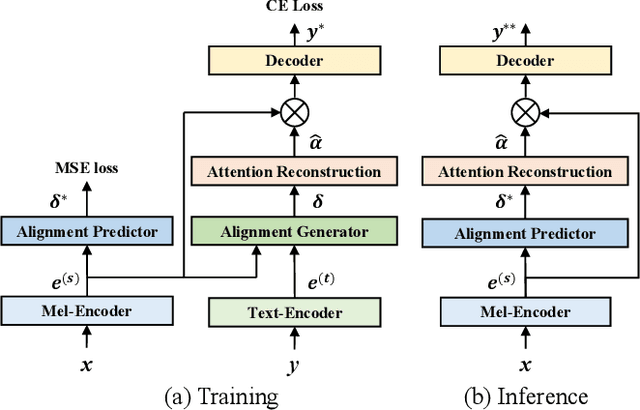
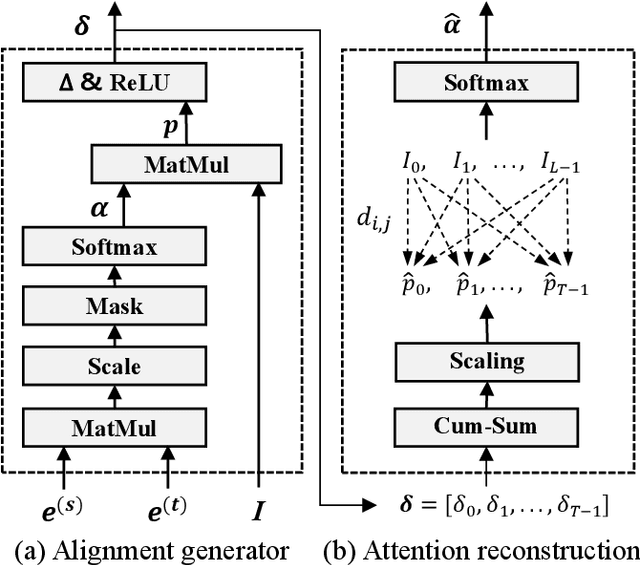
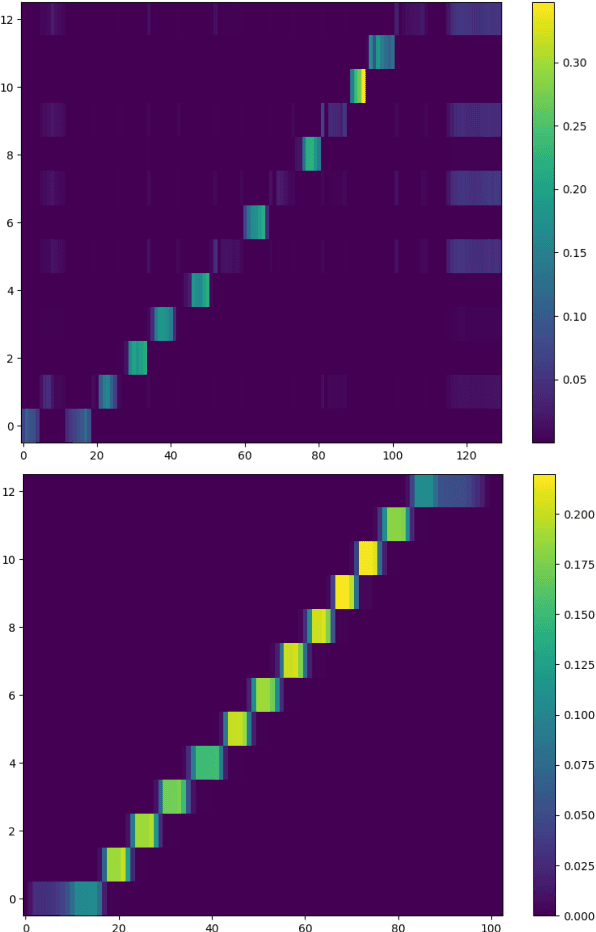
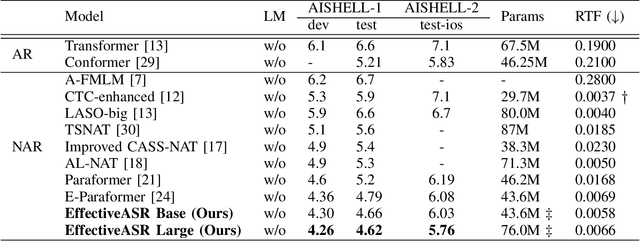
Non-autoregressive (NAR) automatic speech recognition (ASR) models predict tokens independently and simultaneously, bringing high inference speed. However, there is still a gap in the accuracy of the NAR models compared to the autoregressive (AR) models. To further narrow the gap between the NAR and AR models, we propose a single-step NAR ASR architecture with high accuracy and inference speed, called EfficientASR. It uses an Index Mapping Vector (IMV) based alignment generator to generate alignments during training, and an alignment predictor to learn the alignments for inference. It can be trained end-to-end (E2E) with cross-entropy loss combined with alignment loss. The proposed EfficientASR achieves competitive results on the AISHELL-1 and AISHELL-2 benchmarks compared to the state-of-the-art (SOTA) models. Specifically, it achieves character error rates (CER) of 4.26%/4.62% on the AISHELL-1 dev/test dataset, which outperforms the SOTA AR Conformer with about 30x inference speedup.
Statistical modelling and Bayesian inversion for a Compton imaging system: application to radioactive source localisation
Feb 16, 2024This paper presents a statistical forward model for a Compton imaging system, called Compton imager. This system, under development at the University of Illinois Urbana Champaign, is a variant of Compton cameras with a single type of sensors which can simultaneously act as scatterers and absorbers. This imager is convenient for imaging situations requiring a wide field of view. The proposed statistical forward model is then used to solve the inverse problem of estimating the location and energy of point-like sources from observed data. This inverse problem is formulated and solved in a Bayesian framework by using a Metropolis within Gibbs algorithm for the estimation of the location, and an expectation-maximization algorithm for the estimation of the energy. This approach leads to more accurate estimation when compared with the deterministic standard back-projection approach, with the additional benefit of uncertainty quantification in the low photon imaging setting.
Algorithms for TRISO Fuel Identification Based on X-ray CT Validated on Tungsten-Carbide Compacts
Apr 28, 2022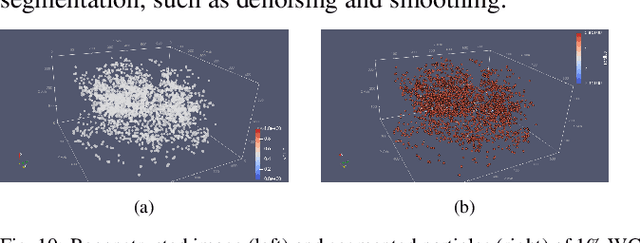
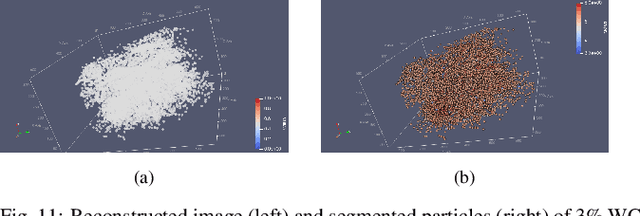

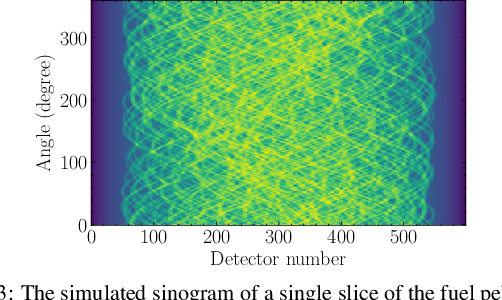
Tristructural-isotropic (TRISO) fuel is one of the most mature fuel types for candidate advanced reactor types under development. TRISO-fuel pebbles flow continuously through the reactor core and can be reinserted into the reactor several times until a target burnup is reached. The capability of identifying individual fuel pebbles would allow us to calculate the fuel residence time in the core and validate pebble flow computational models, prevent excessive burnup accumulation or premature fuel discharge, and maintain accountability of special nuclear materials during fuel circulation. In this work, we have developed a 3D image reconstruction and segmentation algorithm to accurately segment TRISO particles and extract the unique 3D distribution. We have developed a rotation-invariant and noise-robust identification algorithm that allows us to identify the pebble and retrieve the pebble ID in the presence of rotations and noises. We also report the results of 200kV X-ray CT image reconstruction of a mock-up fuel sample consisting of tungsten-carbide (WC) kernels in a lucite matrix. The 3D distribution of TRISO particles along with other signatures such as $^{235}$U enrichment and burnup level extracted through neutron multiplicity counting, would enable accurate fuel identification in a reasonable amount of time.
Analyzing the Intensity of Complaints on Social Media
Apr 20, 2022
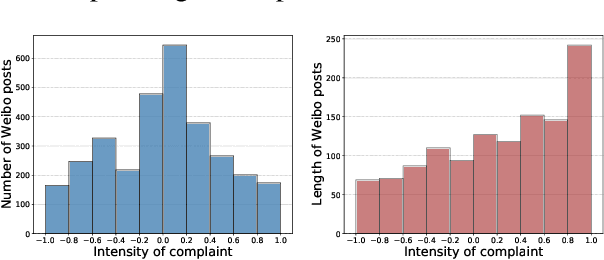

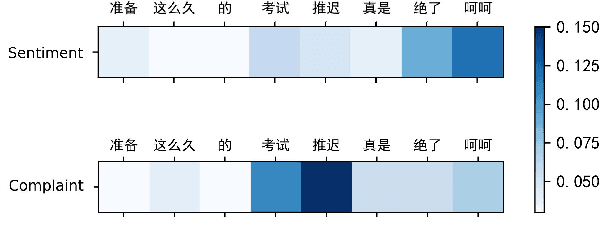
Complaining is a speech act that expresses a negative inconsistency between reality and human expectations. While prior studies mostly focus on identifying the existence or the type of complaints, in this work, we present the first study in computational linguistics of measuring the intensity of complaints from text. Analyzing complaints from such perspective is particularly useful, as complaints of certain degrees may cause severe consequences for companies or organizations. We create the first Chinese dataset containing 3,103 posts about complaints from Weibo, a popular Chinese social media platform. These posts are then annotated with complaints intensity scores using Best-Worst Scaling (BWS) method. We show that complaints intensity can be accurately estimated by computational models with the best mean square error achieving 0.11. Furthermore, we conduct a comprehensive linguistic analysis around complaints, including the connections between complaints and sentiment, and a cross-lingual comparison for complaints expressions used by Chinese and English speakers. We finally show that our complaints intensity scores can be incorporated for better estimating the popularity of posts on social media.