 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMark: Scalable In-Generation Watermark with Blind Extraction for Video Diffusion
Mar 03, 2026Artificial Intelligence Generated Content (AIGC), particularly video generation with diffusion models, has been advanced rapidly. Invisible watermarking is a key technology for protecting AI-generated videos and tracing harmful content, and thus plays a crucial role in AI safety. Beyond post-processing watermarks which inevitably degrade video quality, recent studies have proposed distortion-free in-generation watermarking for video diffusion models. However, existing in-generation approaches are non-blind: they require maintaining all the message-key pairs and performing template-based matching during extraction, which incurs prohibitive computational costs at scale. Moreover, when applied to modern video diffusion models with causal 3D Variational Autoencoders (VAEs), their robustness against temporal disturbance becomes extremely weak. To overcome these challenges, we propose SIGMark, a Scalable In-Generation watermarking framework with blind extraction for video diffusion. To achieve blind-extraction, we propose to generate watermarked initial noise using a Global set of Frame-wise PseudoRandom Coding keys (GF-PRC), reducing the cost of storing large-scale information while preserving noise distribution and diversity for distortion-free watermarking. To enhance robustness, we further design a Segment Group-Ordering module (SGO) tailored to causal 3D VAEs, ensuring robust watermark inversion during extraction under temporal disturbance. Comprehensive experiments on modern diffusion models show that SIGMark achieves very high bit-accuracy during extraction under both temporal and spatial disturbances with minimal overhead, demonstrating its scalability and robustness. Our project is available at https://jeremyzhao1998.github.io/SIGMark-release/.
C-LoRA: Contextual Low-Rank Adaptation for Uncertainty Estimation in Large Language Models
May 23, 2025Low-Rank Adaptation (LoRA) offers a cost-effective solution for fine-tuning large language models (LLMs), but it often produces overconfident predictions in data-scarce few-shot settings. To address this issue, several classical statistical learning approaches have been repurposed for scalable uncertainty-aware LoRA fine-tuning. However, these approaches neglect how input characteristics affect the predictive uncertainty estimates. To address this limitation, we propose Contextual Low-Rank Adaptation (\textbf{C-LoRA}) as a novel uncertainty-aware and parameter efficient fine-tuning approach, by developing new lightweight LoRA modules contextualized to each input data sample to dynamically adapt uncertainty estimates. Incorporating data-driven contexts into the parameter posteriors, C-LoRA mitigates overfitting, achieves well-calibrated uncertainties, and yields robust predictions. Extensive experiments demonstrate that C-LoRA consistently outperforms the state-of-the-art uncertainty-aware LoRA methods in both uncertainty quantification and model generalization. Ablation studies further confirm the critical role of our contextual modules in capturing sample-specific uncertainties. C-LoRA sets a new standard for robust, uncertainty-aware LLM fine-tuning in few-shot regimes.
VLM-based Prompts as the Optimal Assistant for Unpaired Histopathology Virtual Staining
Apr 22, 2025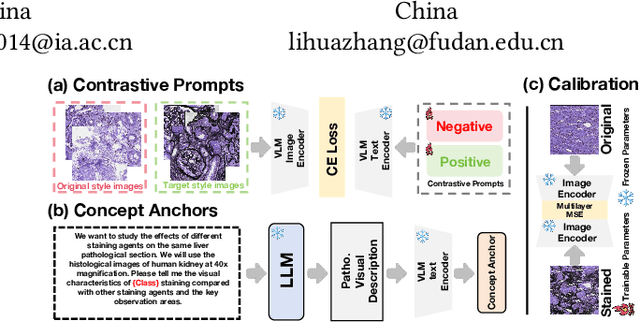
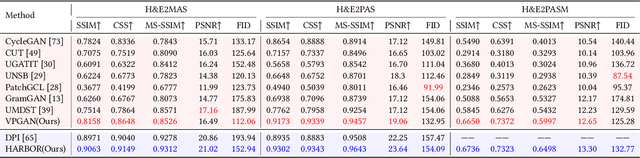
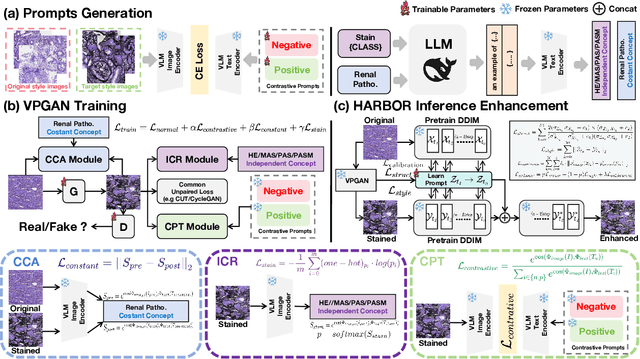

In histopathology, tissue sections are typically stained using common H&E staining or special stains (MAS, PAS, PASM, etc.) to clearly visualize specific tissue structures. The rapid advancement of deep learning offers an effective solution for generating virtually stained images, significantly reducing the time and labor costs associated with traditional histochemical staining. However, a new challenge arises in separating the fundamental visual characteristics of tissue sections from the visual differences induced by staining agents. Additionally, virtual staining often overlooks essential pathological knowledge and the physical properties of staining, resulting in only style-level transfer. To address these issues, we introduce, for the first time in virtual staining tasks, a pathological vision-language large model (VLM) as an auxiliary tool. We integrate contrastive learnable prompts, foundational concept anchors for tissue sections, and staining-specific concept anchors to leverage the extensive knowledge of the pathological VLM. This approach is designed to describe, frame, and enhance the direction of virtual staining. Furthermore, we have developed a data augmentation method based on the constraints of the VLM. This method utilizes the VLM's powerful image interpretation capabilities to further integrate image style and structural information, proving beneficial in high-precision pathological diagnostics. Extensive evaluations on publicly available multi-domain unpaired staining datasets demonstrate that our method can generate highly realistic images and enhance the accuracy of downstream tasks, such as glomerular detection and segmentation. Our code is available at: https://github.com/CZZZZZZZZZZZZZZZZZ/VPGAN-HARBOR
Enhancing Visual Representation for Text-based Person Searching
Dec 30, 2024



Text-based person search aims to retrieve the matched pedestrians from a large-scale image database according to the text description. The core difficulty of this task is how to extract effective details from pedestrian images and texts, and achieve cross-modal alignment in a common latent space. Prior works adopt image and text encoders pre-trained on unimodal data to extract global and local features from image and text respectively, and then global-local alignment is achieved explicitly. However, these approaches still lack the ability of understanding visual details, and the retrieval accuracy is still limited by identity confusion. In order to alleviate the above problems, we rethink the importance of visual features for text-based person search, and propose VFE-TPS, a Visual Feature Enhanced Text-based Person Search model. It introduces a pre-trained multimodal backbone CLIP to learn basic multimodal features and constructs Text Guided Masked Image Modeling task to enhance the model's ability of learning local visual details without explicit annotation. In addition, we design Identity Supervised Global Visual Feature Calibration task to guide the model learn identity-aware global visual features. The key finding of our study is that, with the help of our proposed auxiliary tasks, the knowledge embedded in the pre-trained CLIP model can be successfully adapted to text-based person search task, and the model's visual understanding ability is significantly enhanced. Experimental results on three benchmarks demonstrate that our proposed model exceeds the existing approaches, and the Rank-1 accuracy is significantly improved with a notable margin of about $1\%\sim9\%$. Our code can be found at https://github.com/zhangweifeng1218/VFE_TPS.
N3H-Core: Neuron-designed Neural Network Accelerator via FPGA-based Heterogeneous Computing Cores
Dec 15, 2021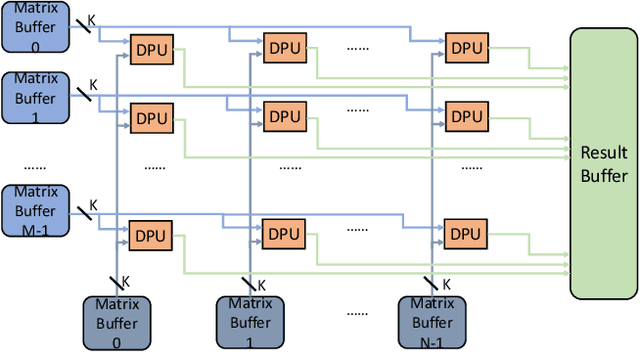
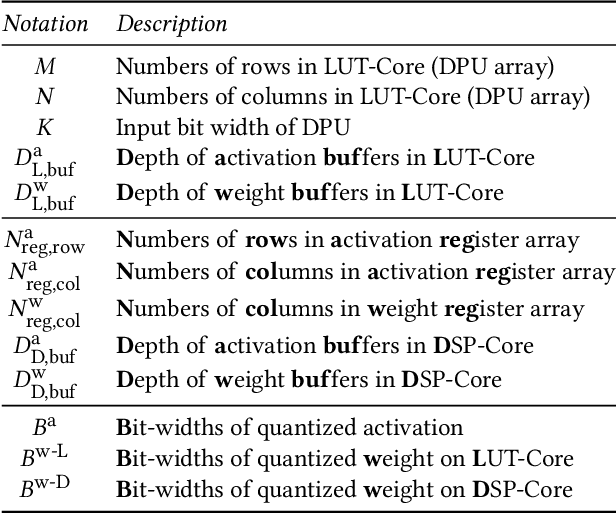
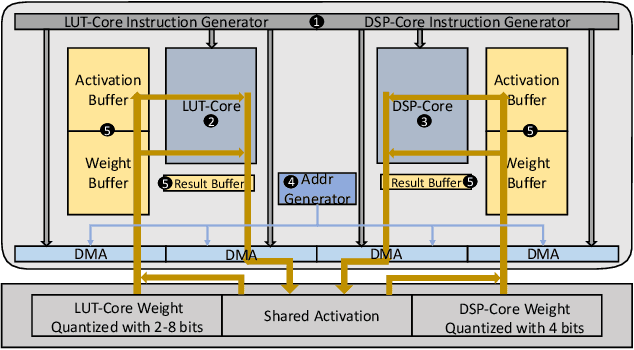
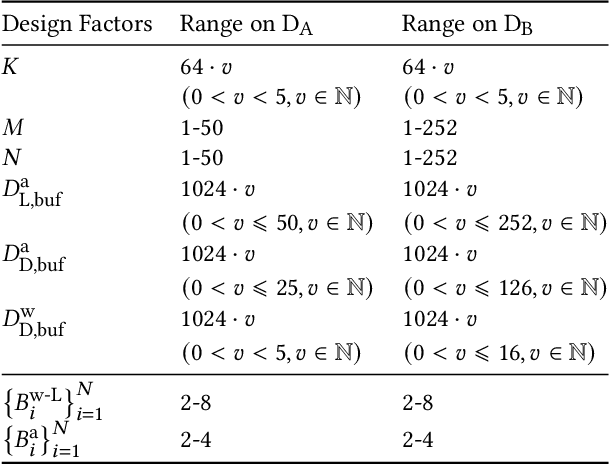
Accelerating the neural network inference by FPGA has emerged as a popular option, since the reconfigurability and high performance computing capability of FPGA intrinsically satisfies the computation demand of the fast-evolving neural algorithms. However, the popular neural accelerators on FPGA (e.g., Xilinx DPU) mainly utilize the DSP resources for constructing their processing units, while the rich LUT resources are not well exploited. Via the software-hardware co-design approach, in this work, we develop an FPGA-based heterogeneous computing system for neural network acceleration. From the hardware perspective, the proposed accelerator consists of DSP- and LUT-based GEneral Matrix-Multiplication (GEMM) computing cores, which forms the entire computing system in a heterogeneous fashion. The DSP- and LUT-based GEMM cores are computed w.r.t a unified Instruction Set Architecture (ISA) and unified buffers. Along the data flow of the neural network inference path, the computation of the convolution/fully-connected layer is split into two portions, handled by the DSP- and LUT-based GEMM cores asynchronously. From the software perspective, we mathematically and systematically model the latency and resource utilization of the proposed heterogeneous accelerator, regarding varying system design configurations. Through leveraging the reinforcement learning technique, we construct a framework to achieve end-to-end selection and optimization of the design specification of target heterogeneous accelerator, including workload split strategy, mixed-precision quantization scheme, and resource allocation of DSP- and LUT-core. In virtue of the proposed design framework and heterogeneous computing system, our design outperforms the state-of-the-art Mix&Match design with latency reduced by 1.12-1.32x with higher inference accuracy. The N3H-core is open-sourced at: https://github.com/elliothe/N3H_Core.
Learning to Affiliate: Mutual Centralized Learning for Few-shot Classification
Jun 10, 2021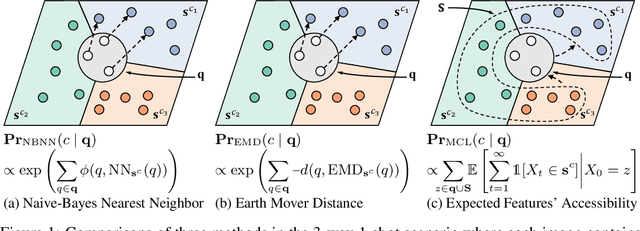
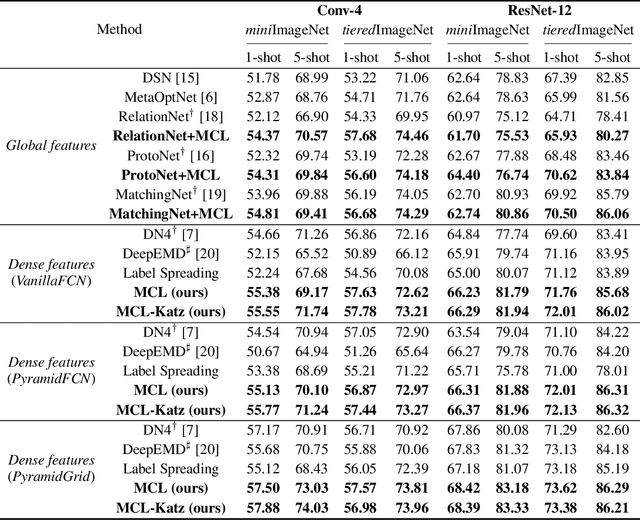
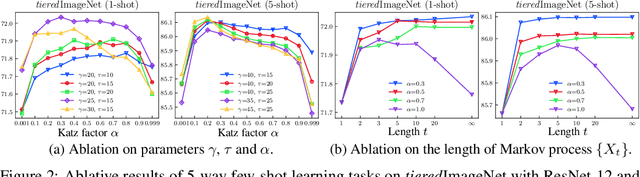
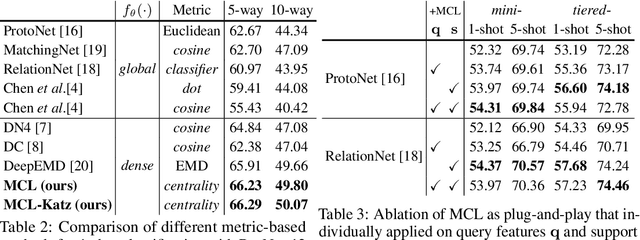
Few-shot learning (FSL) aims to learn a classifier that can be easily adapted to accommodate new tasks not seen during training, given only a few examples. To handle the limited-data problem in few-shot regimes, recent methods tend to collectively use a set of local features to densely represent an image instead of using a mixed global feature. They generally explore a unidirectional query-to-support paradigm in FSL, e.g., find the nearest/optimal support feature for each query feature and aggregate these local matches for a joint classification. In this paper, we propose a new method Mutual Centralized Learning (MCL) to fully affiliate the two disjoint sets of dense features in a bidirectional paradigm. We associate each local feature with a particle that can bidirectionally random walk in a discrete feature space by the affiliations. To estimate the class probability, we propose the features' accessibility that measures the expected number of visits to the support features of that class in a Markov process. We relate our method to learning a centrality on an affiliation network and demonstrate its capability to be plugged in existing methods by highlighting centralized local features. Experiments show that our method achieves the state-of-the-art on both miniImageNet and tieredImageNet.
Cross-modal Knowledge Reasoning for Knowledge-based Visual Question Answering
Aug 31, 2020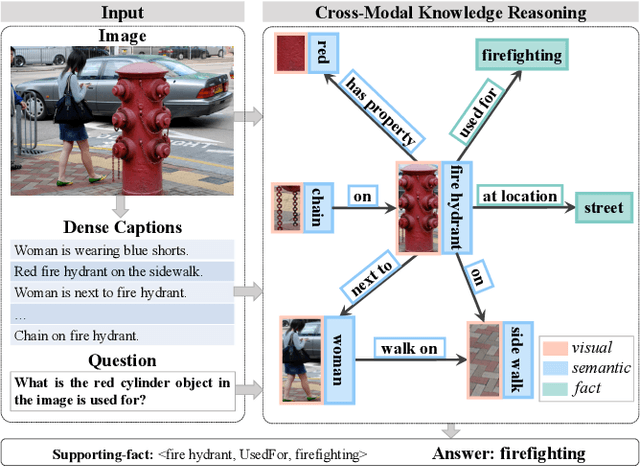
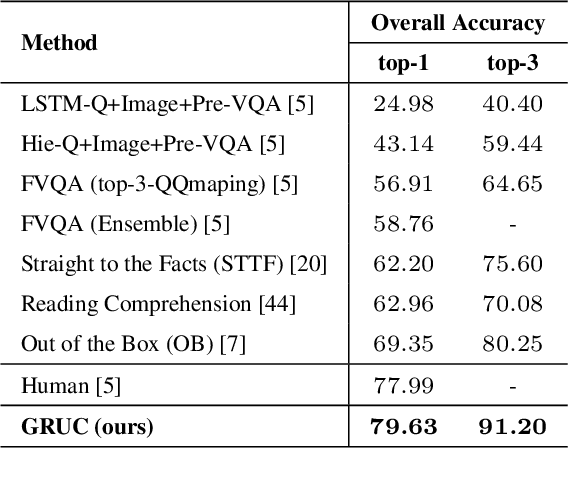

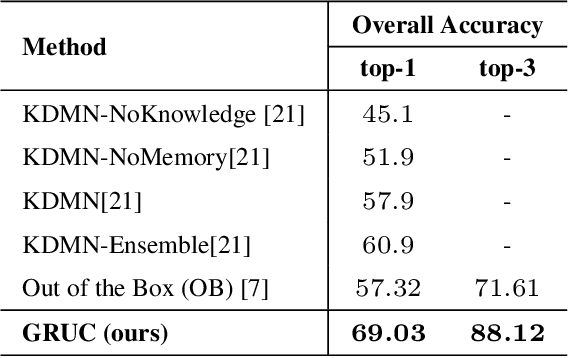
Knowledge-based Visual Question Answering (KVQA) requires external knowledge beyond the visible content to answer questions about an image. This ability is challenging but indispensable to achieve general VQA. One limitation of existing KVQA solutions is that they jointly embed all kinds of information without fine-grained selection, which introduces unexpected noises for reasoning the correct answer. How to capture the question-oriented and information-complementary evidence remains a key challenge to solve the problem. Inspired by the human cognition theory, in this paper, we depict an image by multiple knowledge graphs from the visual, semantic and factual views. Thereinto, the visual graph and semantic graph are regarded as image-conditioned instantiation of the factual graph. On top of these new representations, we re-formulate Knowledge-based Visual Question Answering as a recurrent reasoning process for obtaining complementary evidence from multimodal information. To this end, we decompose the model into a series of memory-based reasoning steps, each performed by a G raph-based R ead, U pdate, and C ontrol ( GRUC ) module that conducts parallel reasoning over both visual and semantic information. By stacking the modules multiple times, our model performs transitive reasoning and obtains question-oriented concept representations under the constrain of different modalities. Finally, we perform graph neural networks to infer the global-optimal answer by jointly considering all the concepts. We achieve a new state-of-the-art performance on three popular benchmark datasets, including FVQA, Visual7W-KB and OK-VQA, and demonstrate the effectiveness and interpretability of our model with extensive experiments.
Regularized Training and Tight Certification for Randomized Smoothed Classifier with Provable Robustness
Feb 17, 2020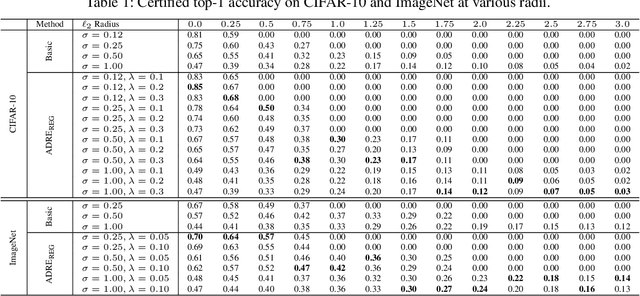
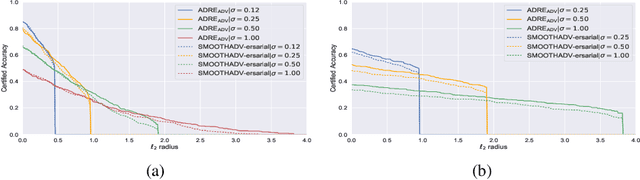
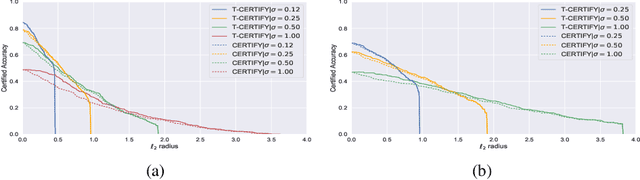
Recently smoothing deep neural network based classifiers via isotropic Gaussian perturbation is shown to be an effective and scalable way to provide state-of-the-art probabilistic robustness guarantee against $\ell_2$ norm bounded adversarial perturbations. However, how to train a good base classifier that is accurate and robust when smoothed has not been fully investigated. In this work, we derive a new regularized risk, in which the regularizer can adaptively encourage the accuracy and robustness of the smoothed counterpart when training the base classifier. It is computationally efficient and can be implemented in parallel with other empirical defense methods. We discuss how to implement it under both standard (non-adversarial) and adversarial training scheme. At the same time, we also design a new certification algorithm, which can leverage the regularization effect to provide tighter robustness lower bound that holds with high probability. Our extensive experimentation demonstrates the effectiveness of the proposed training and certification approaches on CIFAR-10 and ImageNet datasets.
Sionnx: Automatic Unit Test Generator for ONNX Conformance
Jun 12, 2019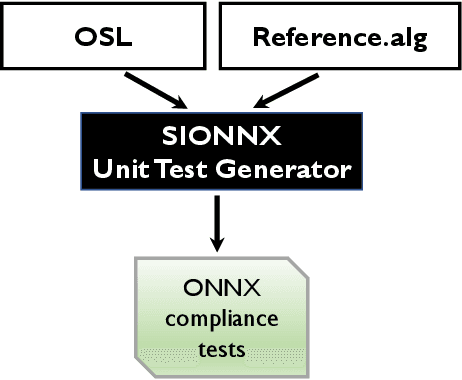
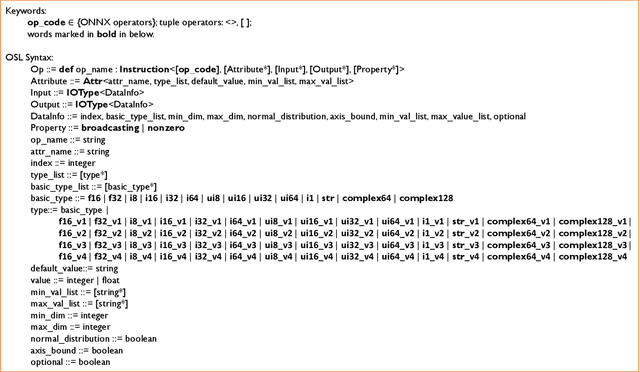

Open Neural Network Exchange (ONNX) is an open format to represent AI models and is supported by many machine learning frameworks. While ONNX defines unified and portable computation operators across various frameworks, the conformance tests for those operators are insufficient, which makes it difficult to verify if an operator's behavior in an ONNX backend implementation complies with the ONNX standard. In this paper, we present the first automatic unit test generator named Sionnx for verifying the compliance of ONNX implementation. First, we propose a compact yet complete set of rules to describe the operator's attributes and the properties of its operands. Second, we design an Operator Specification Language (OSL) to provide a high-level description for the operator's syntax. Finally, through this easy-to-use specification language, we are able to build a full testing specification which leverages LLVM TableGen to automatically generate unit tests for ONNX operators with much large coverage. Sionnx is lightweight and flexible to support cross-framework verification. The Sionnx framework is open-sourced in the github repository (https://github.com/alibaba/Sionnx).
Software-Defined Design Space Exploration for an Efficient AI Accelerator Architecture
Mar 18, 2019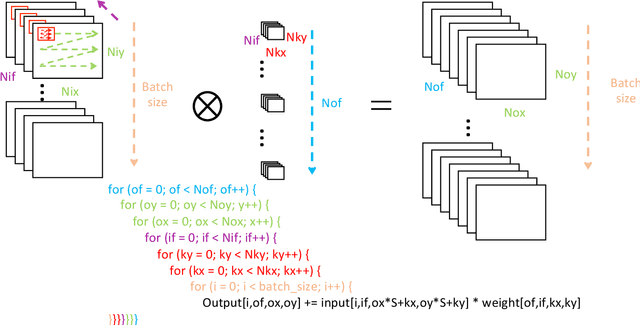


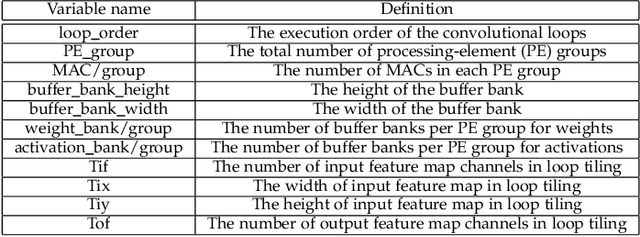
Deep neural networks (DNNs) have been shown to outperform conventional machine learning algorithms across a wide range of applications, e.g., image recognition, object detection, robotics, and natural language processing. However, the high computational complexity of DNNs often necessitates extremely fast and efficient hardware. The problem gets worse as the size of neural networks grows exponentially. As a result, customized hardware accelerators have been developed to accelerate DNN processing without sacrificing model accuracy. However, previous accelerator design studies have not fully considered the characteristics of the target applications, which may lead to sub-optimal architecture designs. On the other hand, new DNN models have been developed for better accuracy, but their compatibility with the underlying hardware accelerator is often overlooked. In this article, we propose an application-driven framework for architectural design space exploration of DNN accelerators. This framework is based on a hardware analytical model of individual DNN operations. It models the accelerator design task as a multi-dimensional optimization problem. We demonstrate that it can be efficaciously used in application-driven accelerator architecture design. Given a target DNN, the framework can generate efficient accelerator design solutions with optimized performance and area. Furthermore, we explore the opportunity to use the framework for accelerator configuration optimization under simultaneous diverse DNN applications. The framework is also capable of improving neural network models to best fit the underlying hardware resources.