 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Image Fusion Method based on Feature Mutual Mapping
Jan 29, 2022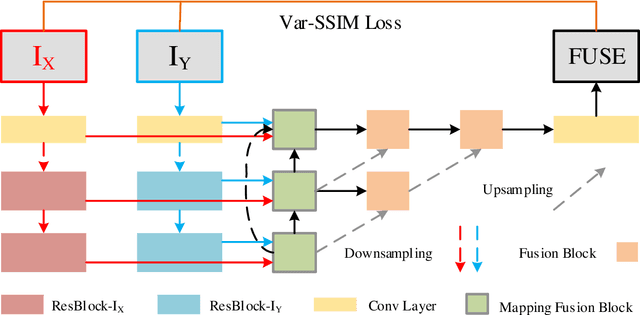
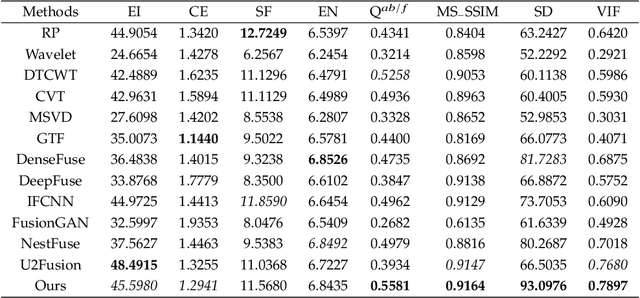
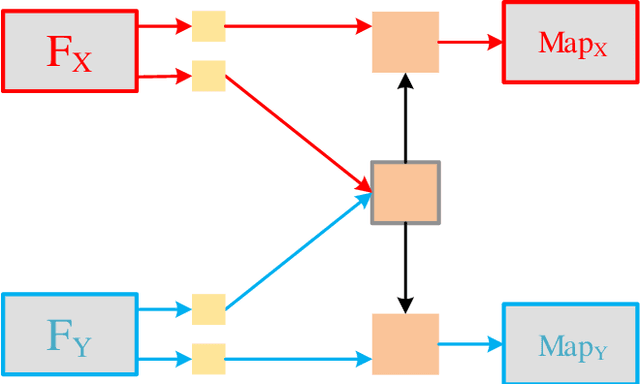
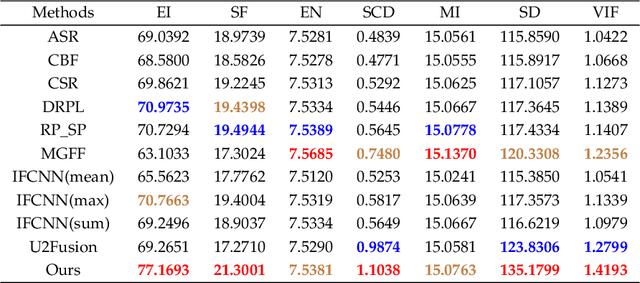
Deep learning-based image fusion approaches have obtained wide attention in recent years, achieving promising performance in terms of visual perception. However, the fusion module in the current deep learning-based methods suffers from two limitations, \textit{i.e.}, manually designed fusion function, and input-independent network learning. In this paper, we propose an unsupervised adaptive image fusion method to address the above issues. We propose a feature mutual mapping fusion module and dual-branch multi-scale autoencoder. More specifically, we construct a global map to measure the connections of pixels between the input source images. % The found mapping relationship guides the image fusion. Besides, we design a dual-branch multi-scale network through sampling transformation to extract discriminative image features. We further enrich feature representations of different scales through feature aggregation in the decoding process. Finally, we propose a modified loss function to train the network with efficient convergence property. Through sufficient training on infrared and visible image data sets, our method also shows excellent generalized performance in multi-focus and medical image fusion. Our method achieves superior performance in both visual perception and objective evaluation. Experiments prove that the performance of our proposed method on a variety of image fusion tasks surpasses other state-of-the-art methods, proving the effectiveness and versatility of our approach.
Regularized Training and Tight Certification for Randomized Smoothed Classifier with Provable Robustness
Feb 17, 2020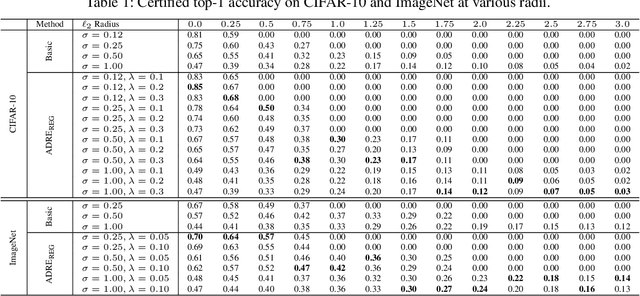
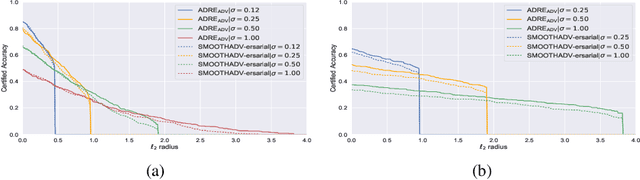
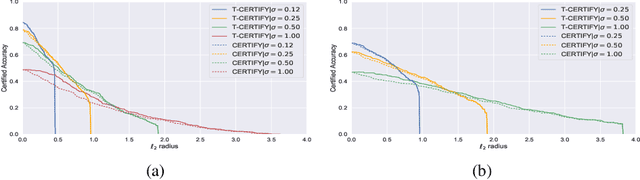
Recently smoothing deep neural network based classifiers via isotropic Gaussian perturbation is shown to be an effective and scalable way to provide state-of-the-art probabilistic robustness guarantee against $\ell_2$ norm bounded adversarial perturbations. However, how to train a good base classifier that is accurate and robust when smoothed has not been fully investigated. In this work, we derive a new regularized risk, in which the regularizer can adaptively encourage the accuracy and robustness of the smoothed counterpart when training the base classifier. It is computationally efficient and can be implemented in parallel with other empirical defense methods. We discuss how to implement it under both standard (non-adversarial) and adversarial training scheme. At the same time, we also design a new certification algorithm, which can leverage the regularization effect to provide tighter robustness lower bound that holds with high probability. Our extensive experimentation demonstrates the effectiveness of the proposed training and certification approaches on CIFAR-10 and ImageNet datasets.
Sionnx: Automatic Unit Test Generator for ONNX Conformance
Jun 12, 2019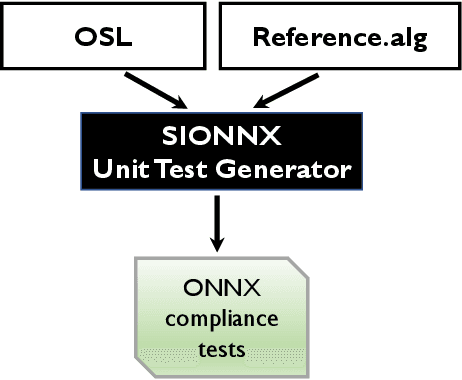
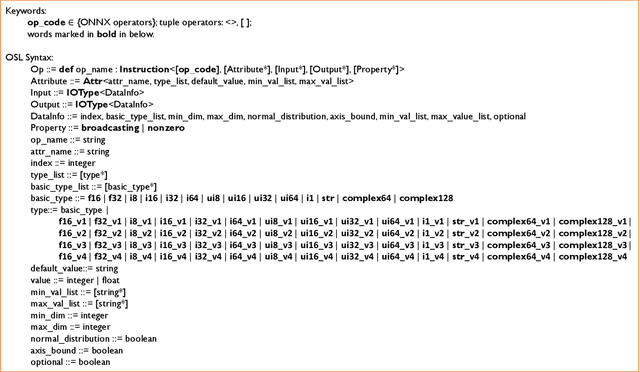

Open Neural Network Exchange (ONNX) is an open format to represent AI models and is supported by many machine learning frameworks. While ONNX defines unified and portable computation operators across various frameworks, the conformance tests for those operators are insufficient, which makes it difficult to verify if an operator's behavior in an ONNX backend implementation complies with the ONNX standard. In this paper, we present the first automatic unit test generator named Sionnx for verifying the compliance of ONNX implementation. First, we propose a compact yet complete set of rules to describe the operator's attributes and the properties of its operands. Second, we design an Operator Specification Language (OSL) to provide a high-level description for the operator's syntax. Finally, through this easy-to-use specification language, we are able to build a full testing specification which leverages LLVM TableGen to automatically generate unit tests for ONNX operators with much large coverage. Sionnx is lightweight and flexible to support cross-framework verification. The Sionnx framework is open-sourced in the github repository (https://github.com/alibaba/Sionnx).
Hardware-Guided Symbiotic Training for Compact, Accurate, yet Execution-Efficient LSTM
Jan 30, 2019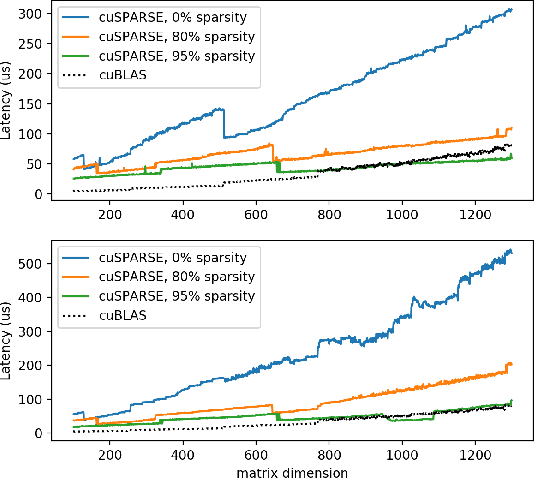
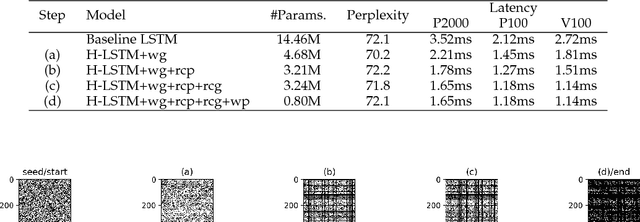
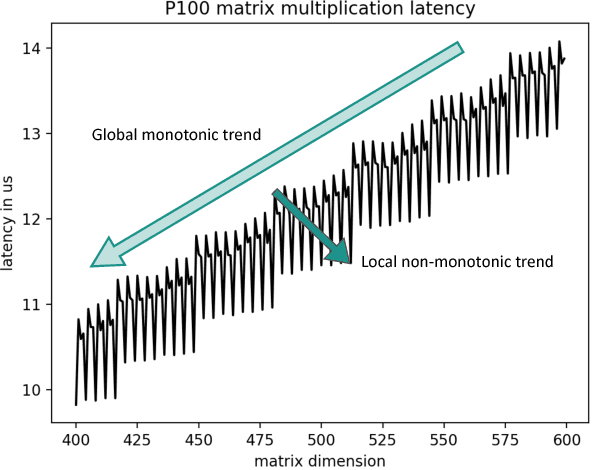
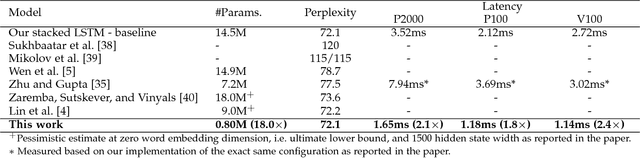
Many long short-term memory (LSTM) applications need fast yet compact models. Neural network compression approaches, such as the grow-and-prune paradigm, have proved to be promising for cutting down network complexity by skipping insignificant weights. However, current compression strategies are mostly hardware-agnostic and network complexity reduction does not always translate into execution efficiency. In this work, we propose a hardware-guided symbiotic training methodology for compact, accurate, yet execution-efficient inference models. It is based on our observation that hardware may introduce substantial non-monotonic behavior, which we call the latency hysteresis effect, when evaluating network size vs. inference latency. This observation raises question about the mainstream smaller-dimension-is-better compression strategy, which often leads to a sub-optimal model architecture. By leveraging the hardware-impacted hysteresis effect and sparsity, we are able to achieve the symbiosis of model compactness and accuracy with execution efficiency, thus reducing LSTM latency while increasing its accuracy. We have evaluated our algorithms on language modeling and speech recognition applications. Relative to the traditional stacked LSTM architecture obtained for the Penn Treebank dataset, we reduce the number of parameters by 18.0x (30.5x) and measured run-time latency by up to 2.4x (5.2x) on Nvidia GPUs (Intel Xeon CPUs) without any accuracy degradation. For the DeepSpeech2 architecture obtained for the AN4 dataset, we reduce the number of parameters by 7.0x (19.4x), word error rate from 12.9% to 9.9% (10.4%), and measured run-time latency by up to 1.7x (2.4x) on Nvidia GPUs (Intel Xeon CPUs). Thus, our method yields compact, accurate, yet execution-efficient inference models.