 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle Self-Training for Semi-Supervised Object Detection with Distribution Consistency Reweighting
Jul 12, 2022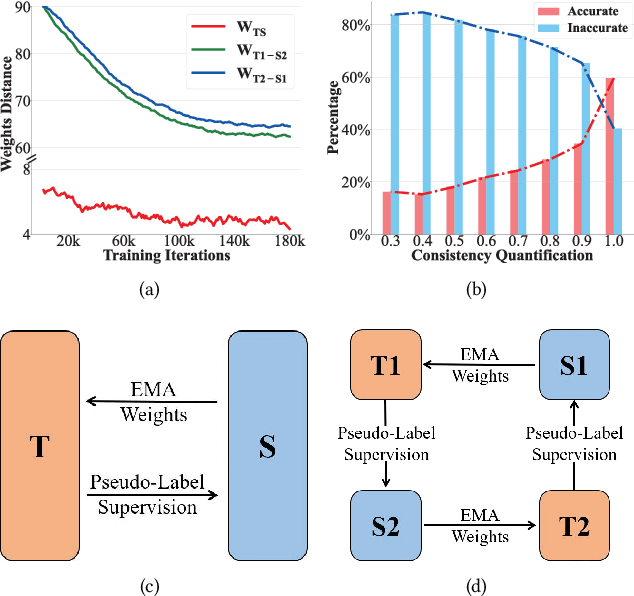
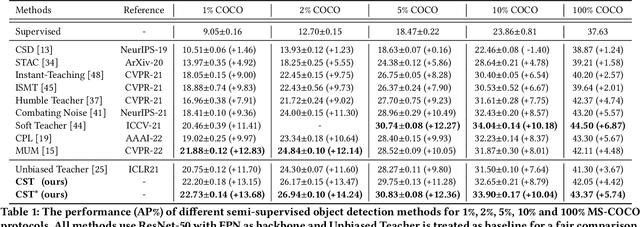
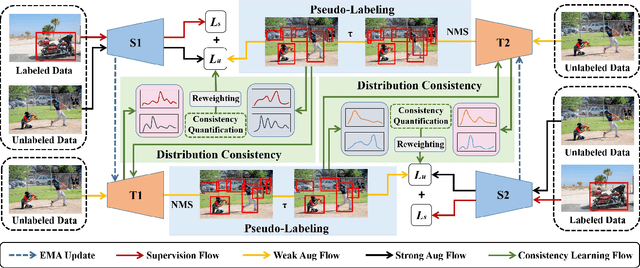
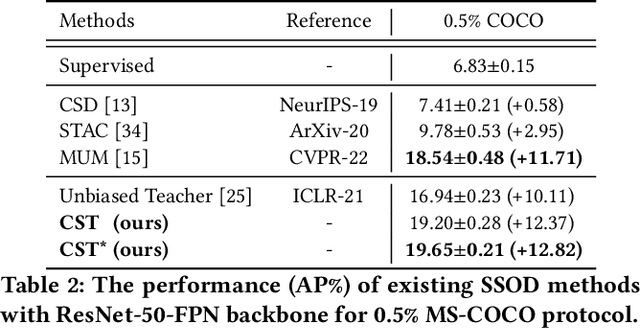
Recently, many semi-supervised object detection (SSOD) methods adopt teacher-student framework and have achieved state-of-the-art results. However, the teacher network is tightly coupled with the student network since the teacher is an exponential moving average (EMA) of the student, which causes a performance bottleneck. To address the coupling problem, we propose a Cycle Self-Training (CST) framework for SSOD, which consists of two teachers T1 and T2, two students S1 and S2. Based on these networks, a cycle self-training mechanism is built, i.e., S1${\rightarrow}$T1${\rightarrow}$S2${\rightarrow}$T2${\rightarrow}$S1. For S${\rightarrow}$T, we also utilize the EMA weights of the students to update the teachers. For T${\rightarrow}$S, instead of providing supervision for its own student S1(S2) directly, the teacher T1(T2) generates pseudo-labels for the student S2(S1), which looses the coupling effect. Moreover, owing to the property of EMA, the teacher is most likely to accumulate the biases from the student and make the mistakes irreversible. To mitigate the problem, we also propose a distribution consistency reweighting strategy, where pseudo-labels are reweighted based on distribution consistency across the teachers T1 and T2. With the strategy, the two students S2 and S1 can be trained robustly with noisy pseudo labels to avoid confirmation biases. Extensive experiments prove the superiority of CST by consistently improving the AP over the baseline and outperforming state-of-the-art methods by 2.1% absolute AP improvements with scarce labeled data.
MVStylizer: An Efficient Edge-Assisted Video Photorealistic Style Transfer System for Mobile Phones
Jun 01, 2020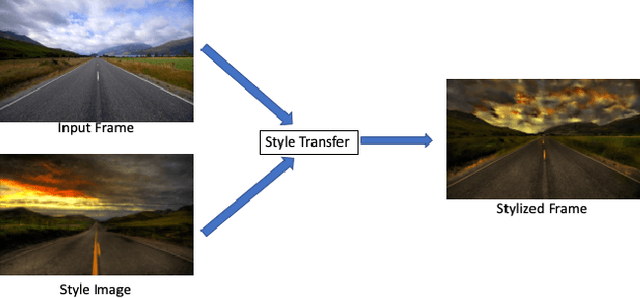
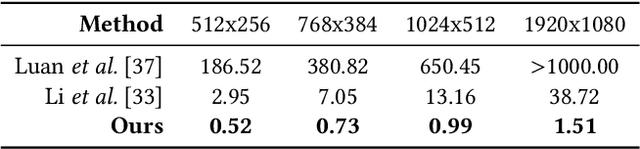

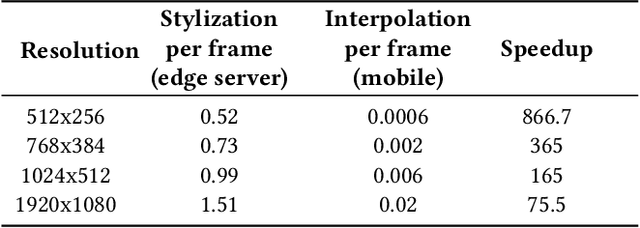
Recent research has made great progress in realizing neural style transfer of images, which denotes transforming an image to a desired style. Many users start to use their mobile phones to record their daily life, and then edit and share the captured images and videos with other users. However, directly applying existing style transfer approaches on videos, i.e., transferring the style of a video frame by frame, requires an extremely large amount of computation resources. It is still technically unaffordable to perform style transfer of videos on mobile phones. To address this challenge, we propose MVStylizer, an efficient edge-assisted photorealistic video style transfer system for mobile phones. Instead of performing stylization frame by frame, only key frames in the original video are processed by a pre-trained deep neural network (DNN) on edge servers, while the rest of stylized intermediate frames are generated by our designed optical-flow-based frame interpolation algorithm on mobile phones. A meta-smoothing module is also proposed to simultaneously upscale a stylized frame to arbitrary resolution and remove style transfer related distortions in these upscaled frames. In addition, for the sake of continuously enhancing the performance of the DNN model on the edge server, we adopt a federated learning scheme to keep retraining each DNN model on the edge server with collected data from mobile clients and syncing with a global DNN model on the cloud server. Such a scheme effectively leverages the diversity of collected data from various mobile clients and efficiently improves the system performance. Our experiments demonstrate that MVStylizer can generate stylized videos with an even better visual quality compared to the state-of-the-art method while achieving 75.5$\times$ speedup for 1920$\times$1080 videos.
Regularized Training and Tight Certification for Randomized Smoothed Classifier with Provable Robustness
Feb 17, 2020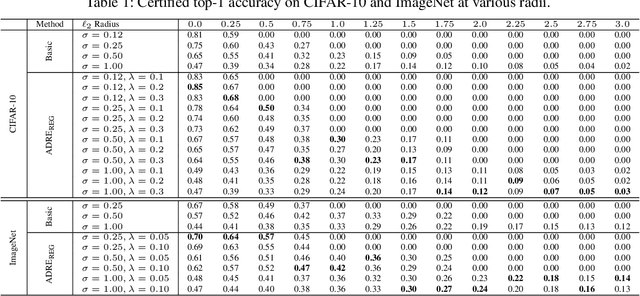
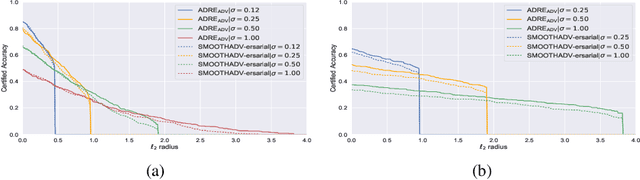
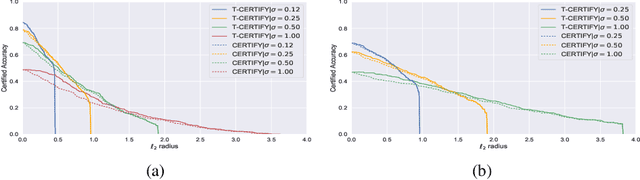
Recently smoothing deep neural network based classifiers via isotropic Gaussian perturbation is shown to be an effective and scalable way to provide state-of-the-art probabilistic robustness guarantee against $\ell_2$ norm bounded adversarial perturbations. However, how to train a good base classifier that is accurate and robust when smoothed has not been fully investigated. In this work, we derive a new regularized risk, in which the regularizer can adaptively encourage the accuracy and robustness of the smoothed counterpart when training the base classifier. It is computationally efficient and can be implemented in parallel with other empirical defense methods. We discuss how to implement it under both standard (non-adversarial) and adversarial training scheme. At the same time, we also design a new certification algorithm, which can leverage the regularization effect to provide tighter robustness lower bound that holds with high probability. Our extensive experimentation demonstrates the effectiveness of the proposed training and certification approaches on CIFAR-10 and ImageNet datasets.
Conditional Transferring Features: Scaling GANs to Thousands of Classes with 30% Less High-quality Data for Training
Sep 25, 2019
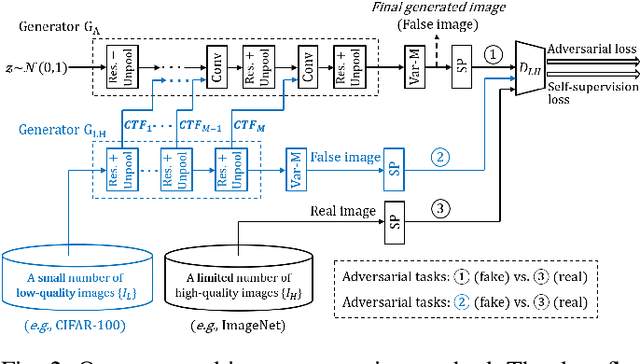
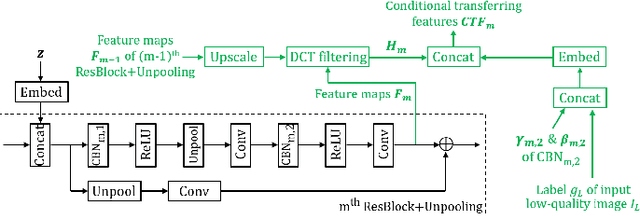

Generative adversarial network (GAN) has greatly improved the quality of unsupervised image generation. Previous GAN-based methods often require a large amount of high-quality training data while producing a small number (e.g., tens) of classes. This work aims to scale up GANs to thousands of classes meanwhile reducing the use of high-quality data in training. We propose an image generation method based on conditional transferring features, which can capture pixel-level semantic changes when transforming low-quality images into high-quality ones. Moreover, self-supervision learning is integrated into our GAN architecture to provide more label-free semantic supervisory information observed from the training data. As such, training our GAN architecture requires much fewer high-quality images with a small number of additional low-quality images. The experiments on CIFAR-10 and STL-10 show that even removing 30% high-quality images from the training set, our method can still outperform previous ones. The scalability on object classes has been experimentally validated: our method with 30% fewer high-quality images obtains the best quality in generating 1,000 ImageNet classes, as well as generating all 3,755 classes of CASIA-HWDB1.0 Chinese handwriting characters.
Towards Leveraging the Information of Gradients in Optimization-based Adversarial Attack
Dec 06, 2018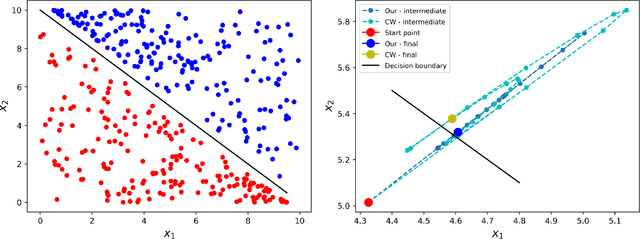
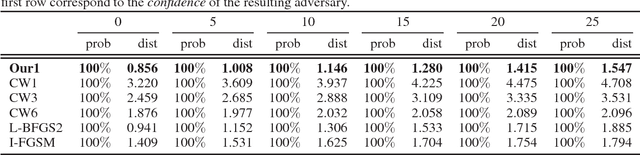
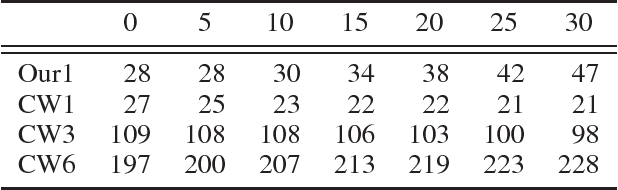
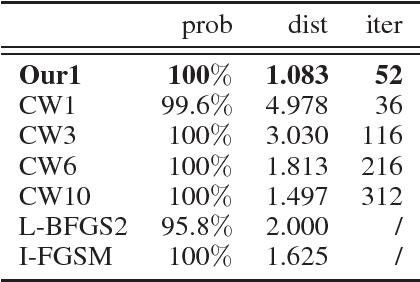
In recent years, deep neural networks demonstrated state-of-the-art performance in a large variety of tasks and therefore have been adopted in many applications. On the other hand, the latest studies revealed that neural networks are vulnerable to adversarial examples obtained by carefully adding small perturbation to legitimate samples. Based upon the observation, many attack methods were proposed. Among them, the optimization-based CW attack is the most powerful as the produced adversarial samples present much less distortion compared to other methods. The better attacking effect, however, comes at the cost of running more iterations and thus longer computation time to reach desirable results. In this work, we propose to leverage the information of gradients as a guidance during the search of adversaries. More specifically, directly incorporating the gradients into the perturbation can be regarded as a constraint added to the optimization process. We intuitively and empirically prove the rationality of our method in reducing the search space. Our experiments show that compared to the original CW attack, the proposed method requires fewer iterations towards adversarial samples, obtaining a higher success rate and resulting in smaller $\ell_2$ distortion.
SmoothOut: Smoothing Out Sharp Minima to Improve Generalization in Deep Learning
Sep 01, 2018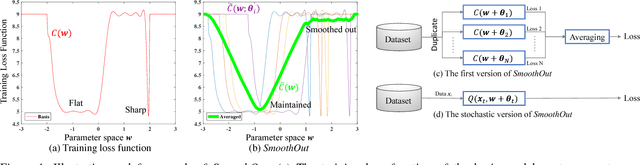
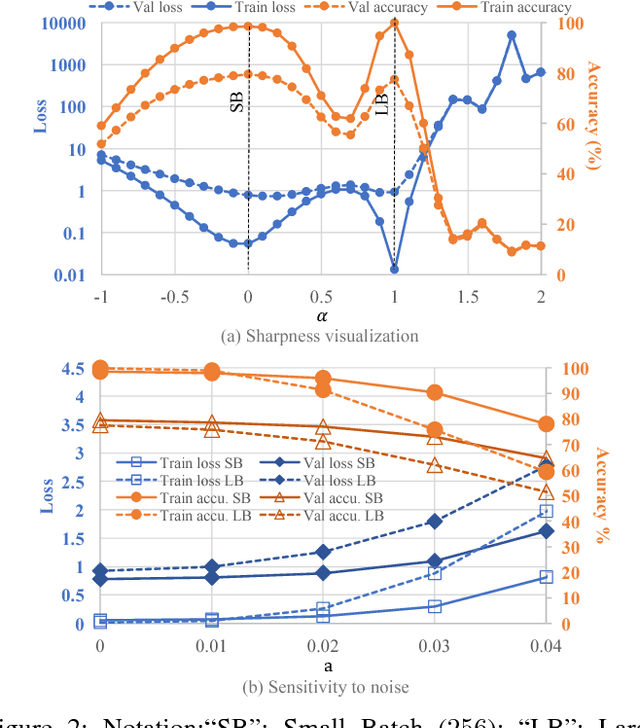
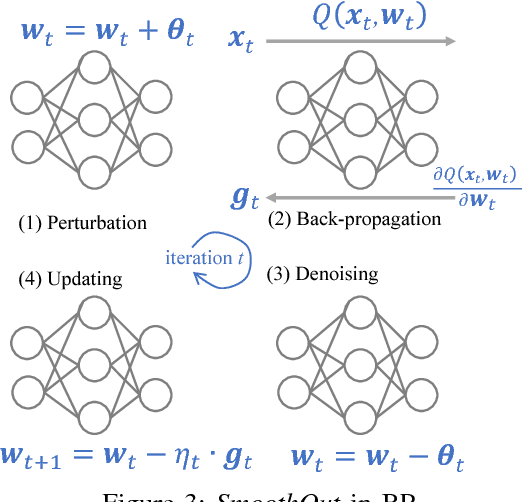
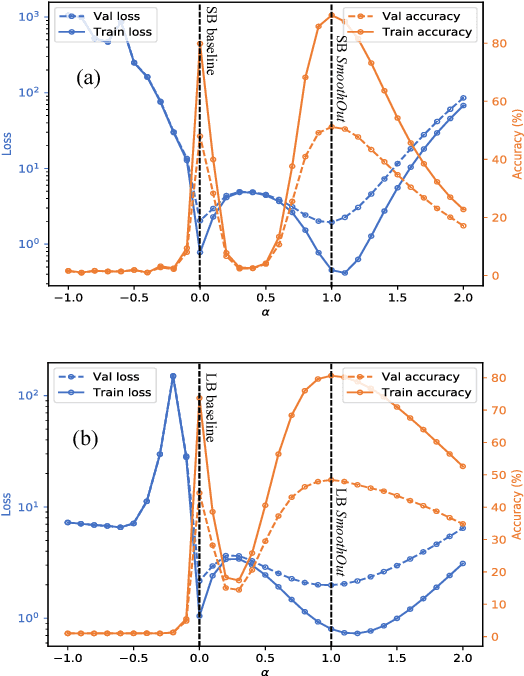
In Deep Learning, Stochastic Gradient Descent (SGD) is usually selected as the training method because of its efficiency and scalability; however, recently, a problem in SGD gains research interest: sharp minima in Deep Neural Networks (DNNs) have poor generalization [1][2]; especially, large-batch SGD tends to converge to sharp minima. It becomes an open question whether escaping sharp minima can improve the generalization. To answer this question, we proposed SmoothOut to smooth out sharp minima in DNNs and thereby improve generalization. In a nutshell, SmoothOut perturbs multiple copies of the DNN by noise injection and averages these copies. Injecting noises to SGD is widely for exploration, but SmoothOut differs in lots of ways: (1) de-noising process is applied before parameter updating; (2) uniform noises are injected instead of Gaussian noises; (3) the goal is to obtain an auxiliary function without sharp minima for better generalization, instead of higher exploration. We prove that SmoothOut can eliminate sharp minima. Training multiple DNN copies is inefficient, we further propose a stochastic version of SmoothOut which only introduces the overhead of noise injecting and de-noising per batch. We prove that the Stochastic SmoothOut is an unbiased approximation of the original SmoothOut. In experiments on a variety of DNNs and datasets, SmoothOut consistently improve generalization in both small-batch and large-batch training on the top of state-of-the-art solutions. Our source code is in https://github.com/wenwei202/smoothout
MAT: A Multi-strength Adversarial Training Method to Mitigate Adversarial Attacks
May 11, 2018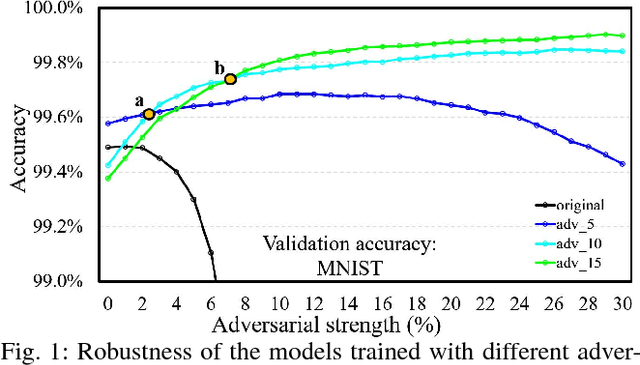
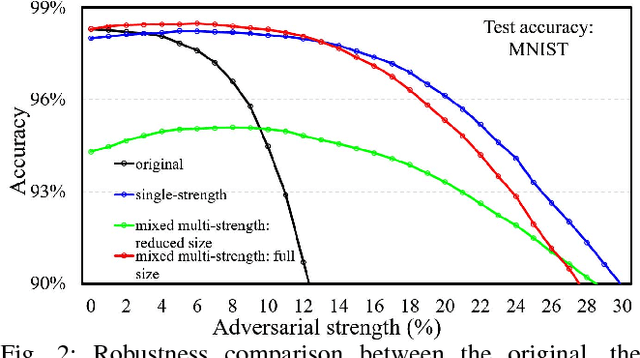
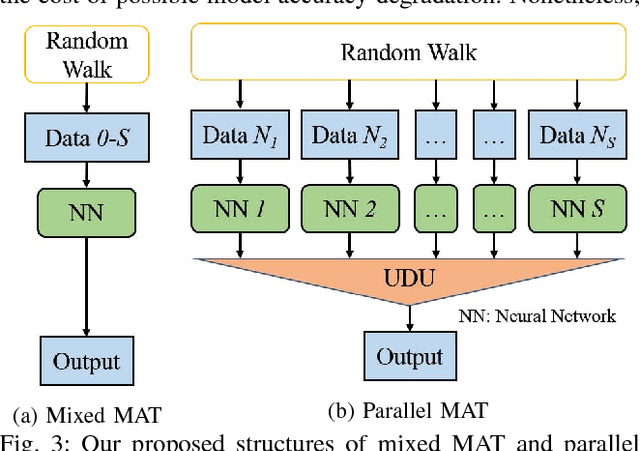
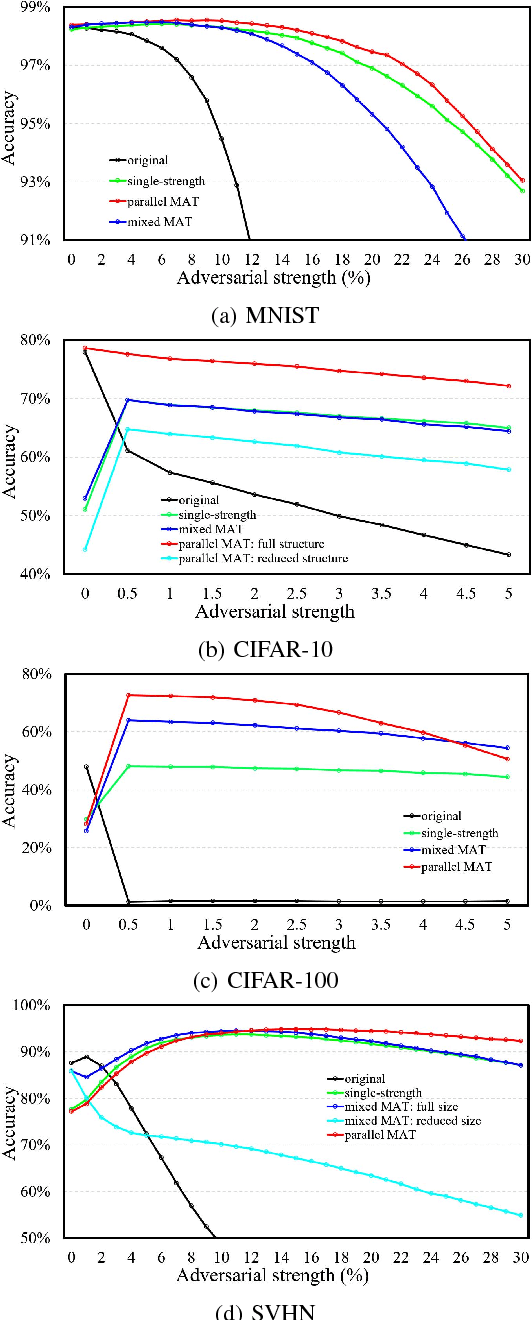
Some recent works revealed that deep neural networks (DNNs) are vulnerable to so-called adversarial attacks where input examples are intentionally perturbed to fool DNNs. In this work, we revisit the DNN training process that includes adversarial examples into the training dataset so as to improve DNN's resilience to adversarial attacks, namely, adversarial training. Our experiments show that different adversarial strengths, i.e., perturbation levels of adversarial examples, have different working zones to resist the attack. Based on the observation, we propose a multi-strength adversarial training method (MAT) that combines the adversarial training examples with different adversarial strengths to defend adversarial attacks. Two training structures - mixed MAT and parallel MAT - are developed to facilitate the tradeoffs between training time and memory occupation. Our results show that MAT can substantially minimize the accuracy degradation of deep learning systems to adversarial attacks on MNIST, CIFAR-10, CIFAR-100, and SVHN.
TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning
Dec 29, 2017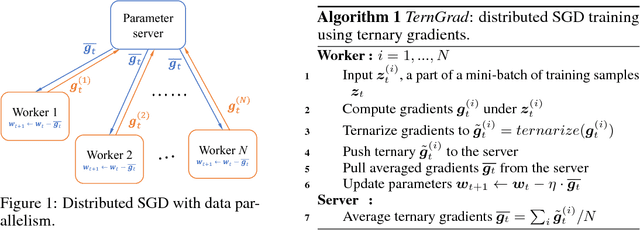
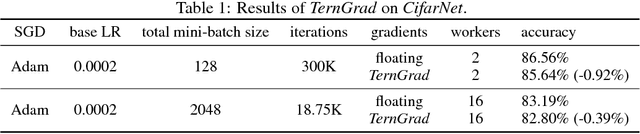
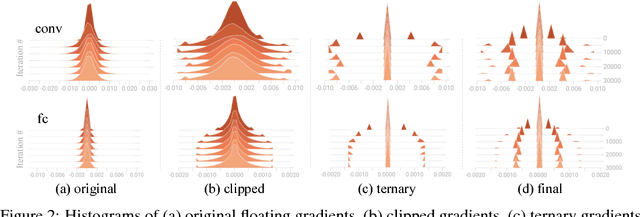

High network communication cost for synchronizing gradients and parameters is the well-known bottleneck of distributed training. In this work, we propose TernGrad that uses ternary gradients to accelerate distributed deep learning in data parallelism. Our approach requires only three numerical levels {-1,0,1}, which can aggressively reduce the communication time. We mathematically prove the convergence of TernGrad under the assumption of a bound on gradients. Guided by the bound, we propose layer-wise ternarizing and gradient clipping to improve its convergence. Our experiments show that applying TernGrad on AlexNet does not incur any accuracy loss and can even improve accuracy. The accuracy loss of GoogLeNet induced by TernGrad is less than 2% on average. Finally, a performance model is proposed to study the scalability of TernGrad. Experiments show significant speed gains for various deep neural networks. Our source code is available.
Coordinating Filters for Faster Deep Neural Networks
Jul 25, 2017
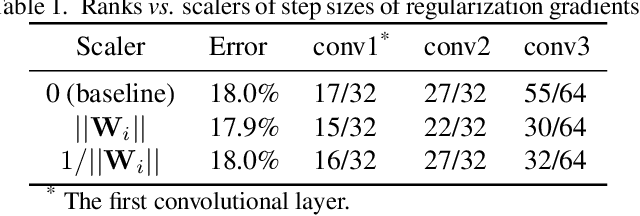
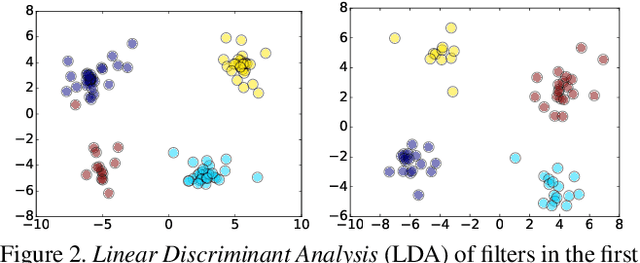
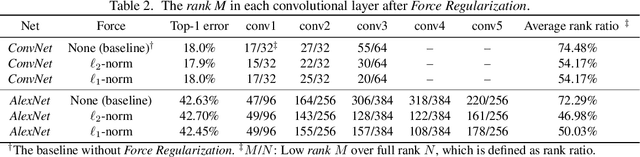
Very large-scale Deep Neural Networks (DNNs) have achieved remarkable successes in a large variety of computer vision tasks. However, the high computation intensity of DNNs makes it challenging to deploy these models on resource-limited systems. Some studies used low-rank approaches that approximate the filters by low-rank basis to accelerate the testing. Those works directly decomposed the pre-trained DNNs by Low-Rank Approximations (LRA). How to train DNNs toward lower-rank space for more efficient DNNs, however, remains as an open area. To solve the issue, in this work, we propose Force Regularization, which uses attractive forces to enforce filters so as to coordinate more weight information into lower-rank space. We mathematically and empirically verify that after applying our technique, standard LRA methods can reconstruct filters using much lower basis and thus result in faster DNNs. The effectiveness of our approach is comprehensively evaluated in ResNets, AlexNet, and GoogLeNet. In AlexNet, for example, Force Regularization gains 2x speedup on modern GPU without accuracy loss and 4.05x speedup on CPU by paying small accuracy degradation. Moreover, Force Regularization better initializes the low-rank DNNs such that the fine-tuning can converge faster toward higher accuracy. The obtained lower-rank DNNs can be further sparsified, proving that Force Regularization can be integrated with state-of-the-art sparsity-based acceleration methods. Source code is available in https://github.com/wenwei202/caffe
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation
Apr 03, 2017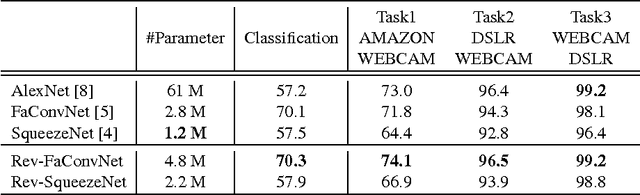
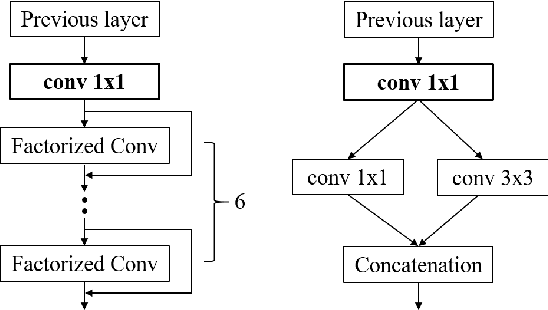
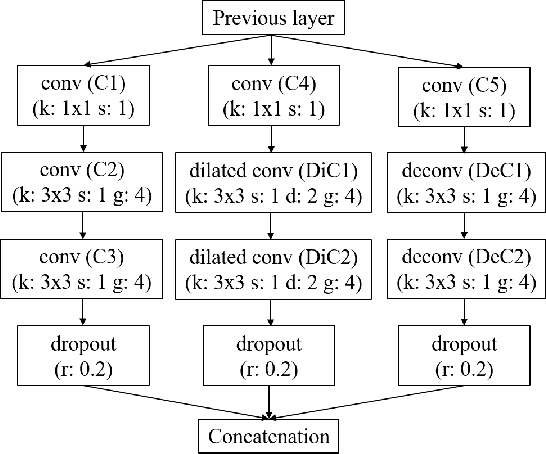
Recently, DNN model compression based on network architecture design, e.g., SqueezeNet, attracted a lot attention. No accuracy drop on image classification is observed on these extremely compact networks, compared to well-known models. An emerging question, however, is whether these model compression techniques hurt DNN's learning ability other than classifying images on a single dataset. Our preliminary experiment shows that these compression methods could degrade domain adaptation (DA) ability, though the classification performance is preserved. Therefore, we propose a new compact network architecture and unsupervised DA method in this paper. The DNN is built on a new basic module Conv-M which provides more diverse feature extractors without significantly increasing parameters. The unified framework of our DA method will simultaneously learn invariance across domains, reduce divergence of feature representations, and adapt label prediction. Our DNN has 4.1M parameters, which is only 6.7% of AlexNet or 59% of GoogLeNet. Experiments show that our DNN obtains GoogLeNet-level accuracy both on classification and DA, and our DA method slightly outperforms previous competitive ones. Put all together, our DA strategy based on our DNN achieves state-of-the-art on sixteen of total eighteen DA tasks on popular Office-31 and Office-Caltech datasets.