 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothOut: Smoothing Out Sharp Minima to Improve Generalization in Deep Learning
Paper and Code
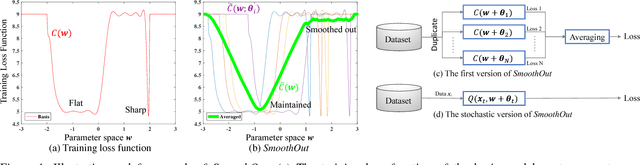
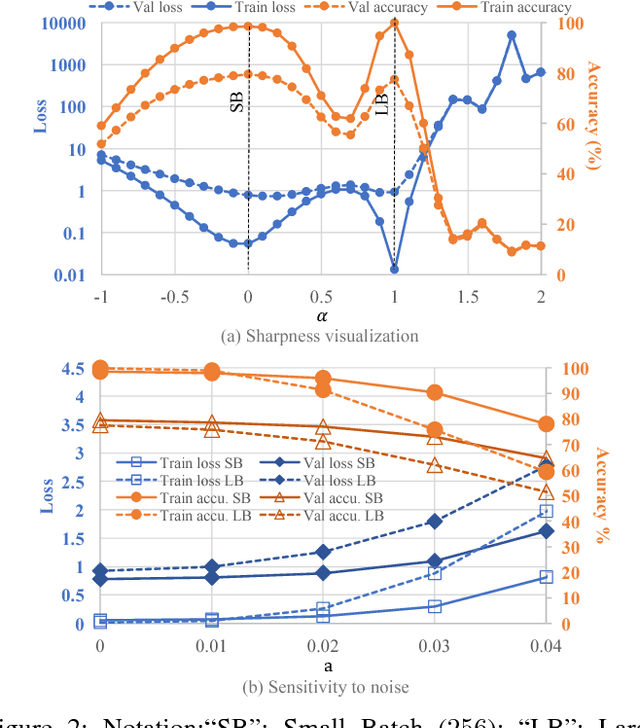
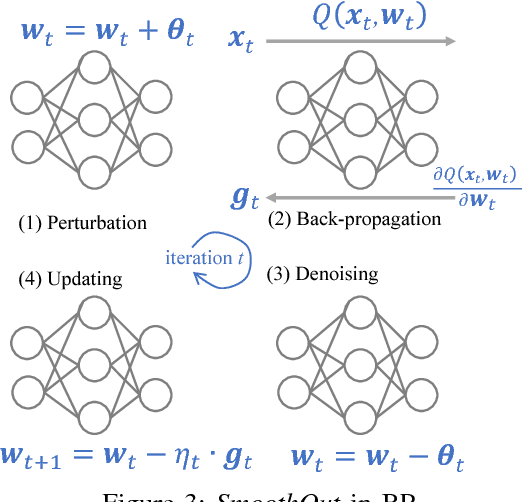
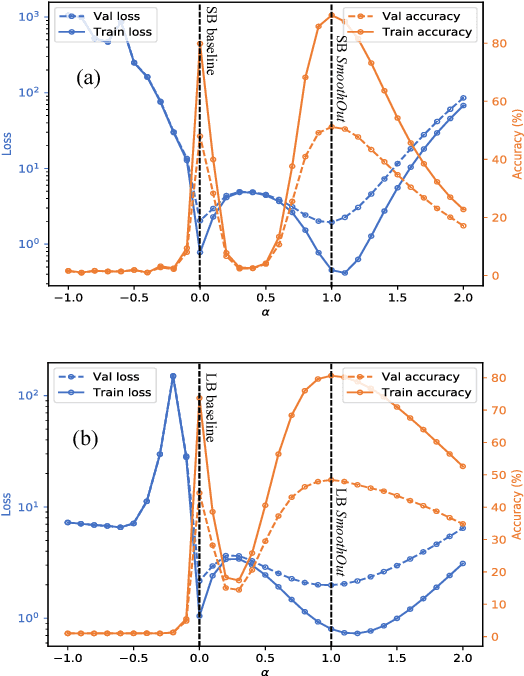
In Deep Learning, Stochastic Gradient Descent (SGD) is usually selected as the training method because of its efficiency and scalability; however, recently, a problem in SGD gains research interest: sharp minima in Deep Neural Networks (DNNs) have poor generalization [1][2]; especially, large-batch SGD tends to converge to sharp minima. It becomes an open question whether escaping sharp minima can improve the generalization. To answer this question, we proposed SmoothOut to smooth out sharp minima in DNNs and thereby improve generalization. In a nutshell, SmoothOut perturbs multiple copies of the DNN by noise injection and averages these copies. Injecting noises to SGD is widely for exploration, but SmoothOut differs in lots of ways: (1) de-noising process is applied before parameter updating; (2) uniform noises are injected instead of Gaussian noises; (3) the goal is to obtain an auxiliary function without sharp minima for better generalization, instead of higher exploration. We prove that SmoothOut can eliminate sharp minima. Training multiple DNN copies is inefficient, we further propose a stochastic version of SmoothOut which only introduces the overhead of noise injecting and de-noising per batch. We prove that the Stochastic SmoothOut is an unbiased approximation of the original SmoothOut. In experiments on a variety of DNNs and datasets, SmoothOut consistently improve generalization in both small-batch and large-batch training on the top of state-of-the-art solutions. Our source code is in https://github.com/wenwei202/smoothout