 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-based Gray-box Adversarial Attack Against Deep Face Recognition
Jan 12, 2022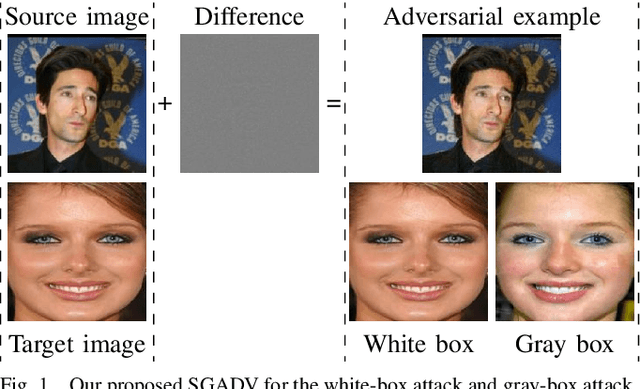
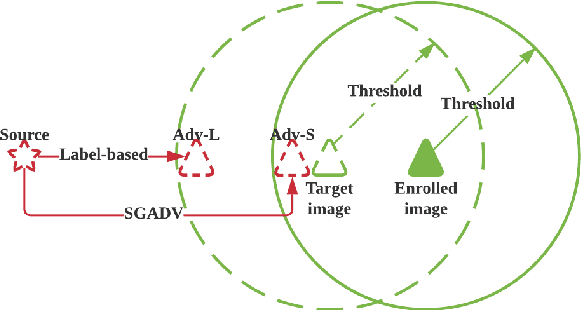
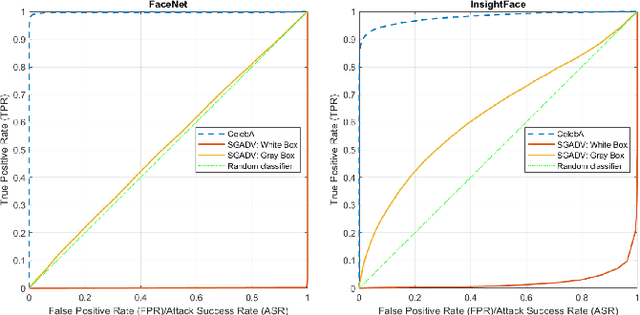

The majority of adversarial attack techniques perform well against deep face recognition when the full knowledge of the system is revealed (\emph{white-box}). However, such techniques act unsuccessfully in the gray-box setting where the face templates are unknown to the attackers. In this work, we propose a similarity-based gray-box adversarial attack (SGADV) technique with a newly developed objective function. SGADV utilizes the dissimilarity score to produce the optimized adversarial example, i.e., similarity-based adversarial attack. This technique applies to both white-box and gray-box attacks against authentication systems that determine genuine or imposter users using the dissimilarity score. To validate the effectiveness of SGADV, we conduct extensive experiments on face datasets of LFW, CelebA, and CelebA-HQ against deep face recognition models of FaceNet and InsightFace in both white-box and gray-box settings. The results suggest that the proposed method significantly outperforms the existing adversarial attack techniques in the gray-box setting. We hence summarize that the similarity-base approaches to develop the adversarial example could satisfactorily cater to the gray-box attack scenarios for de-authentication.
SmoothOut: Smoothing Out Sharp Minima to Improve Generalization in Deep Learning
Sep 01, 2018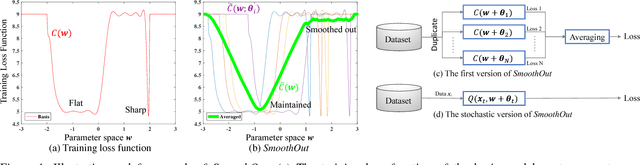
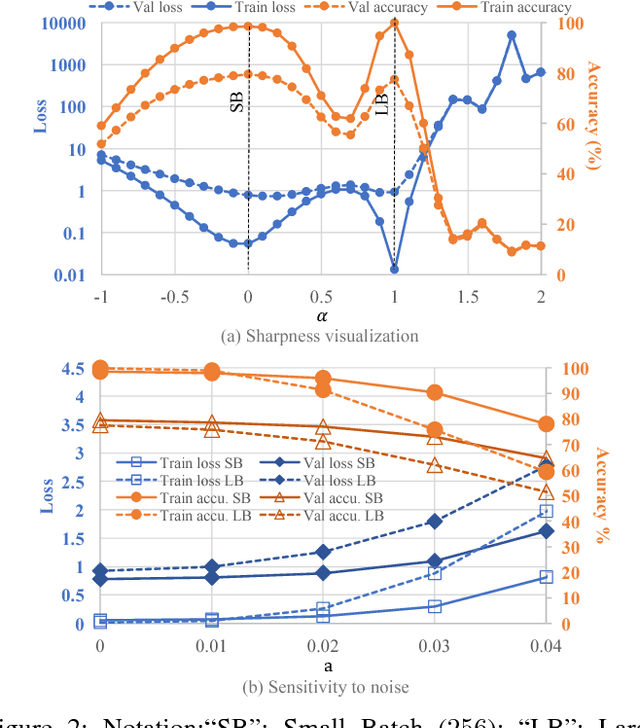
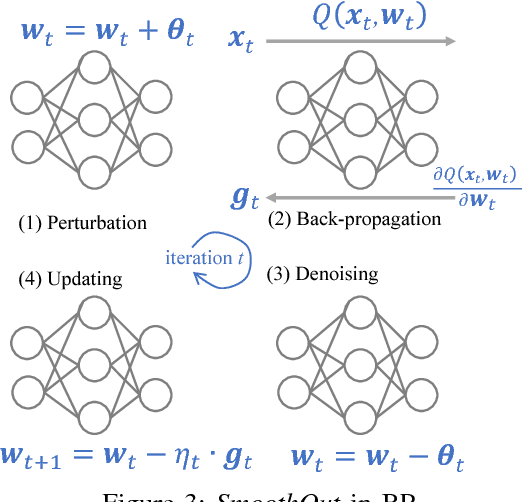
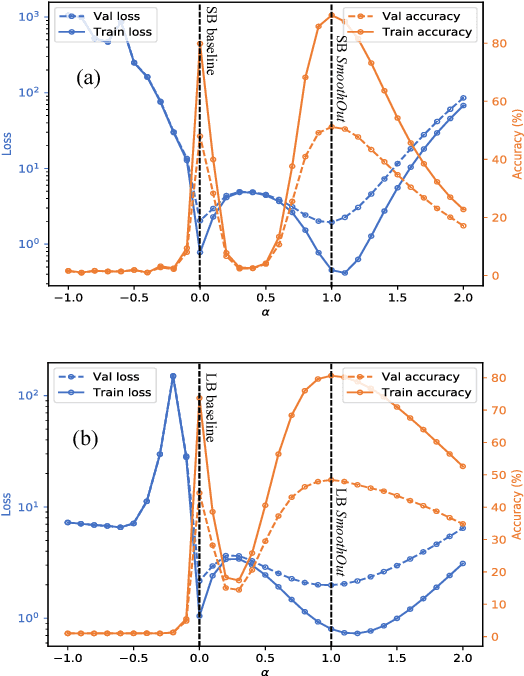
In Deep Learning, Stochastic Gradient Descent (SGD) is usually selected as the training method because of its efficiency and scalability; however, recently, a problem in SGD gains research interest: sharp minima in Deep Neural Networks (DNNs) have poor generalization [1][2]; especially, large-batch SGD tends to converge to sharp minima. It becomes an open question whether escaping sharp minima can improve the generalization. To answer this question, we proposed SmoothOut to smooth out sharp minima in DNNs and thereby improve generalization. In a nutshell, SmoothOut perturbs multiple copies of the DNN by noise injection and averages these copies. Injecting noises to SGD is widely for exploration, but SmoothOut differs in lots of ways: (1) de-noising process is applied before parameter updating; (2) uniform noises are injected instead of Gaussian noises; (3) the goal is to obtain an auxiliary function without sharp minima for better generalization, instead of higher exploration. We prove that SmoothOut can eliminate sharp minima. Training multiple DNN copies is inefficient, we further propose a stochastic version of SmoothOut which only introduces the overhead of noise injecting and de-noising per batch. We prove that the Stochastic SmoothOut is an unbiased approximation of the original SmoothOut. In experiments on a variety of DNNs and datasets, SmoothOut consistently improve generalization in both small-batch and large-batch training on the top of state-of-the-art solutions. Our source code is in https://github.com/wenwei202/smoothout
TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning
Dec 29, 2017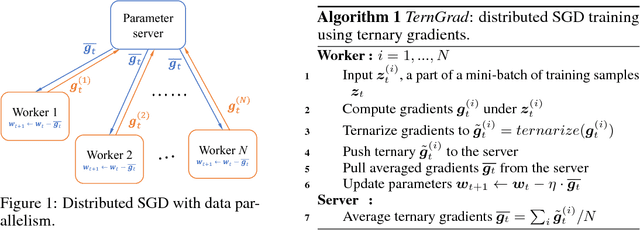
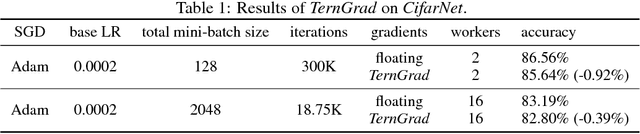
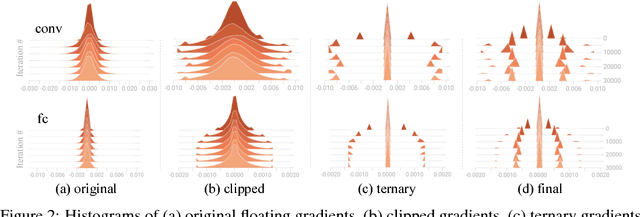

High network communication cost for synchronizing gradients and parameters is the well-known bottleneck of distributed training. In this work, we propose TernGrad that uses ternary gradients to accelerate distributed deep learning in data parallelism. Our approach requires only three numerical levels {-1,0,1}, which can aggressively reduce the communication time. We mathematically prove the convergence of TernGrad under the assumption of a bound on gradients. Guided by the bound, we propose layer-wise ternarizing and gradient clipping to improve its convergence. Our experiments show that applying TernGrad on AlexNet does not incur any accuracy loss and can even improve accuracy. The accuracy loss of GoogLeNet induced by TernGrad is less than 2% on average. Finally, a performance model is proposed to study the scalability of TernGrad. Experiments show significant speed gains for various deep neural networks. Our source code is available.
Coordinating Filters for Faster Deep Neural Networks
Jul 25, 2017
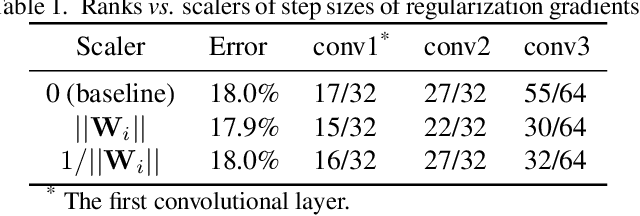
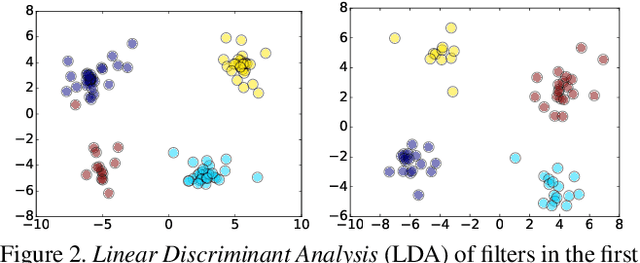
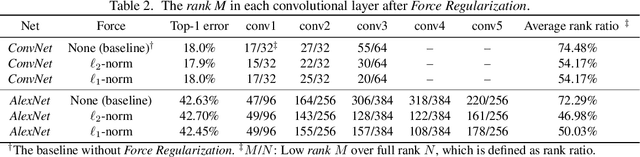
Very large-scale Deep Neural Networks (DNNs) have achieved remarkable successes in a large variety of computer vision tasks. However, the high computation intensity of DNNs makes it challenging to deploy these models on resource-limited systems. Some studies used low-rank approaches that approximate the filters by low-rank basis to accelerate the testing. Those works directly decomposed the pre-trained DNNs by Low-Rank Approximations (LRA). How to train DNNs toward lower-rank space for more efficient DNNs, however, remains as an open area. To solve the issue, in this work, we propose Force Regularization, which uses attractive forces to enforce filters so as to coordinate more weight information into lower-rank space. We mathematically and empirically verify that after applying our technique, standard LRA methods can reconstruct filters using much lower basis and thus result in faster DNNs. The effectiveness of our approach is comprehensively evaluated in ResNets, AlexNet, and GoogLeNet. In AlexNet, for example, Force Regularization gains 2x speedup on modern GPU without accuracy loss and 4.05x speedup on CPU by paying small accuracy degradation. Moreover, Force Regularization better initializes the low-rank DNNs such that the fine-tuning can converge faster toward higher accuracy. The obtained lower-rank DNNs can be further sparsified, proving that Force Regularization can be integrated with state-of-the-art sparsity-based acceleration methods. Source code is available in https://github.com/wenwei202/caffe
Group Scissor: Scaling Neuromorphic Computing Design to Large Neural Networks
Jun 17, 2017
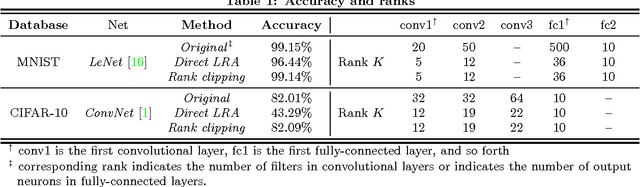
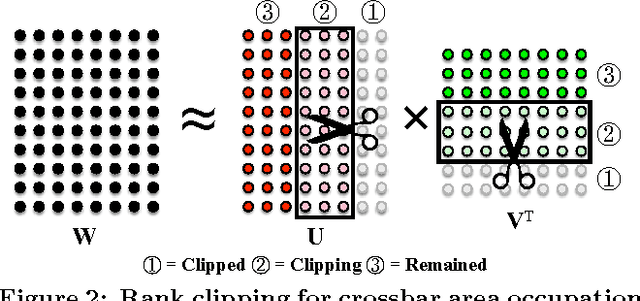

Synapse crossbar is an elementary structure in Neuromorphic Computing Systems (NCS). However, the limited size of crossbars and heavy routing congestion impedes the NCS implementations of big neural networks. In this paper, we propose a two-step framework (namely, group scissor) to scale NCS designs to big neural networks. The first step is rank clipping, which integrates low-rank approximation into the training to reduce total crossbar area. The second step is group connection deletion, which structurally prunes connections to reduce routing congestion between crossbars. Tested on convolutional neural networks of LeNet on MNIST database and ConvNet on CIFAR-10 database, our experiments show significant reduction of crossbar area and routing area in NCS designs. Without accuracy loss, rank clipping reduces total crossbar area to 13.62\% and 51.81\% in the NCS designs of LeNet and ConvNet, respectively. Following rank clipping, group connection deletion further reduces the routing area of LeNet and ConvNet to 8.1\% and 52.06\%, respectively.
Classification Accuracy Improvement for Neuromorphic Computing Systems with One-level Precision Synapses
Jan 07, 2017
Brain inspired neuromorphic computing has demonstrated remarkable advantages over traditional von Neumann architecture for its high energy efficiency and parallel data processing. However, the limited resolution of synaptic weights degrades system accuracy and thus impedes the use of neuromorphic systems. In this work, we propose three orthogonal methods to learn synapses with one-level precision, namely, distribution-aware quantization, quantization regularization and bias tuning, to make image classification accuracy comparable to the state-of-the-art. Experiments on both multi-layer perception and convolutional neural networks show that the accuracy drop can be well controlled within 0.19% (5.53%) for MNIST (CIFAR-10) database, compared to an ideal system without quantization.
Learning Structured Sparsity in Deep Neural Networks
Oct 18, 2016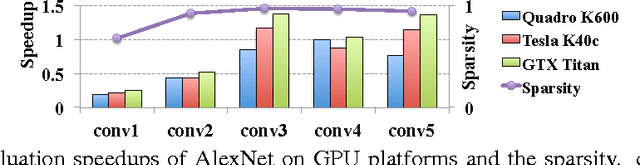
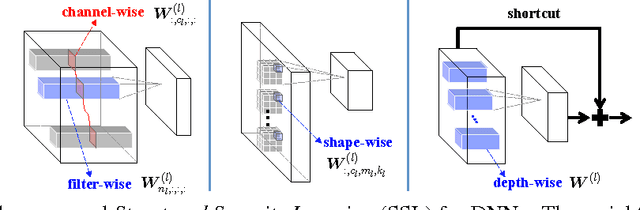
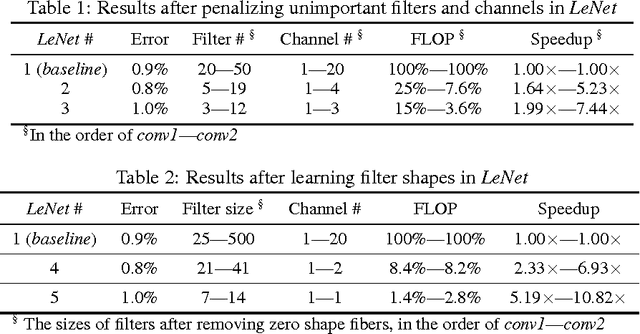

High demand for computation resources severely hinders deployment of large-scale Deep Neural Networks (DNN) in resource constrained devices. In this work, we propose a Structured Sparsity Learning (SSL) method to regularize the structures (i.e., filters, channels, filter shapes, and layer depth) of DNNs. SSL can: (1) learn a compact structure from a bigger DNN to reduce computation cost; (2) obtain a hardware-friendly structured sparsity of DNN to efficiently accelerate the DNNs evaluation. Experimental results show that SSL achieves on average 5.1x and 3.1x speedups of convolutional layer computation of AlexNet against CPU and GPU, respectively, with off-the-shelf libraries. These speedups are about twice speedups of non-structured sparsity; (3) regularize the DNN structure to improve classification accuracy. The results show that for CIFAR-10, regularization on layer depth can reduce 20 layers of a Deep Residual Network (ResNet) to 18 layers while improve the accuracy from 91.25% to 92.60%, which is still slightly higher than that of original ResNet with 32 layers. For AlexNet, structure regularization by SSL also reduces the error by around ~1%. Open source code is in https://github.com/wenwei202/caffe/tree/scnn
A New Learning Method for Inference Accuracy, Core Occupation, and Performance Co-optimization on TrueNorth Chip
Jul 16, 2016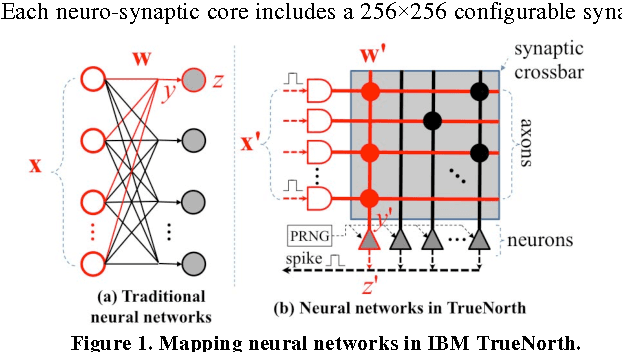
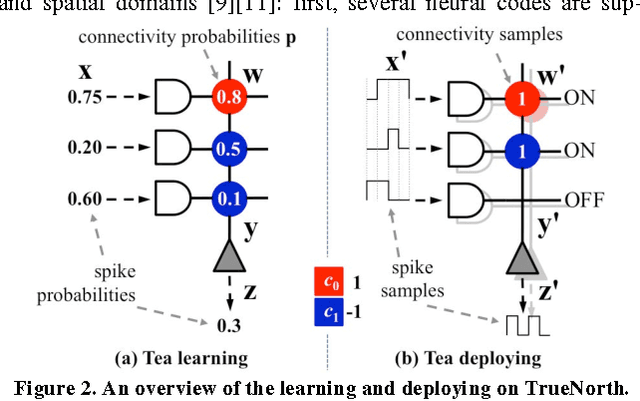
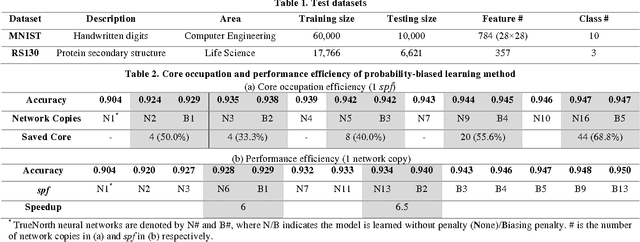
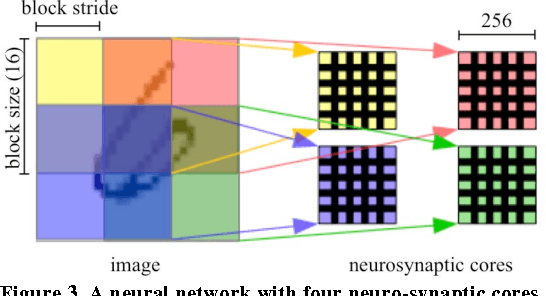
IBM TrueNorth chip uses digital spikes to perform neuromorphic computing and achieves ultrahigh execution parallelism and power efficiency. However, in TrueNorth chip, low quantization resolution of the synaptic weights and spikes significantly limits the inference (e.g., classification) accuracy of the deployed neural network model. Existing workaround, i.e., averaging the results over multiple copies instantiated in spatial and temporal domains, rapidly exhausts the hardware resources and slows down the computation. In this work, we propose a novel learning method on TrueNorth platform that constrains the random variance of each computation copy and reduces the number of needed copies. Compared to the existing learning method, our method can achieve up to 68.8% reduction of the required neuro-synaptic cores or 6.5X speedup, with even slightly improved inference accuracy.