 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Prompt Generation for Semi-supervised Learning with Language Models
Feb 18, 2023

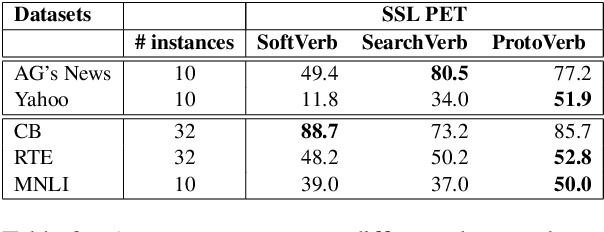

Prompt-based learning methods in semi-supervised learning (SSL) settings have been shown to be effective on multiple natural language understanding (NLU) datasets and tasks in the literature. However, manually designing multiple prompts and verbalizers requires domain knowledge and human effort, making it difficult and expensive to scale across different datasets. In this paper, we propose two methods to automatically design multiple prompts and integrate automatic verbalizer in SSL settings without sacrificing performance. The first method uses various demonstration examples with learnable continuous prompt tokens to create diverse prompt models. The second method uses a varying number of soft prompt tokens to encourage language models to learn different prompts. For the verbalizer, we use the prototypical verbalizer to replace the manual one. In summary, we obtained the best average accuracy of 73.2% (a relative improvement of 2.52% over even the previous state-of-the-art SSL method with manual prompts and verbalizers) in different few-shot learning settings.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022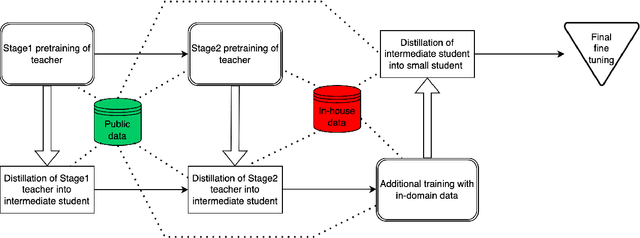
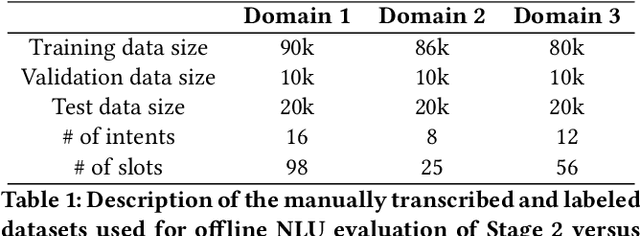
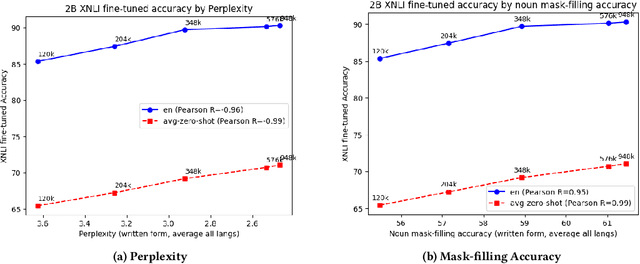
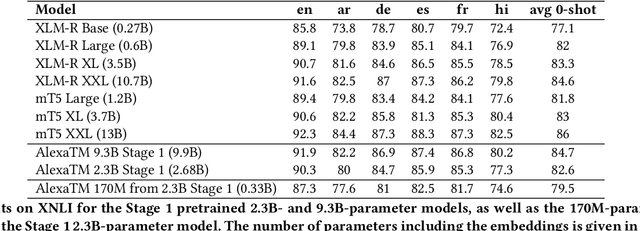
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Exploring Transfer Learning For End-to-End Spoken Language Understanding
Dec 15, 2020

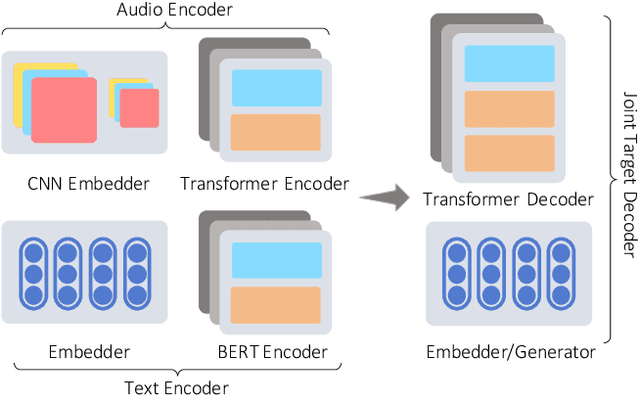

Voice Assistants such as Alexa, Siri, and Google Assistant typically use a two-stage Spoken Language Understanding pipeline; first, an Automatic Speech Recognition (ASR) component to process customer speech and generate text transcriptions, followed by a Natural Language Understanding (NLU) component to map transcriptions to an actionable hypothesis. An end-to-end (E2E) system that goes directly from speech to a hypothesis is a more attractive option. These systems were shown to be smaller, faster, and better optimized. However, they require massive amounts of end-to-end training data and in addition, don't take advantage of the already available ASR and NLU training data. In this work, we propose an E2E system that is designed to jointly train on multiple speech-to-text tasks, such as ASR (speech-transcription) and SLU (speech-hypothesis), and text-to-text tasks, such as NLU (text-hypothesis). We call this the Audio-Text All-Task (AT-AT) Model and we show that it beats the performance of E2E models trained on individual tasks, especially ones trained on limited data. We show this result on an internal music dataset and two public datasets, FluentSpeech and SNIPS Audio, where we achieve state-of-the-art results. Since our model can process both speech and text input sequences and learn to predict a target sequence, it also allows us to do zero-shot E2E SLU by training on only text-hypothesis data (without any speech) from a new domain. We evaluate this ability of our model on the Facebook TOP dataset and set a new benchmark for zeroshot E2E performance. We will soon release the audio data collected for the TOP dataset for future research.
Group Scissor: Scaling Neuromorphic Computing Design to Large Neural Networks
Jun 17, 2017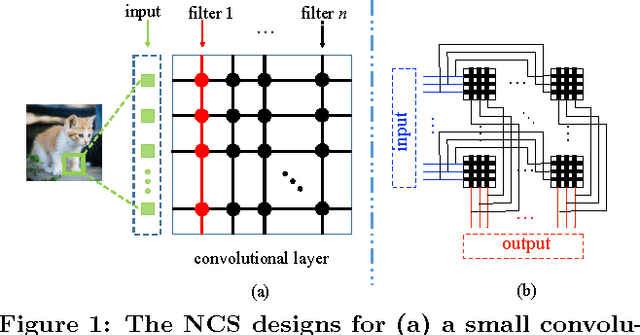
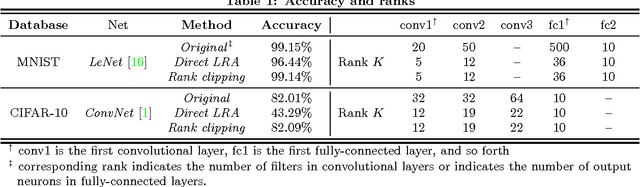
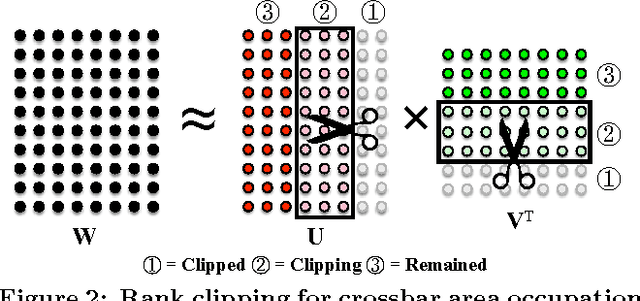

Synapse crossbar is an elementary structure in Neuromorphic Computing Systems (NCS). However, the limited size of crossbars and heavy routing congestion impedes the NCS implementations of big neural networks. In this paper, we propose a two-step framework (namely, group scissor) to scale NCS designs to big neural networks. The first step is rank clipping, which integrates low-rank approximation into the training to reduce total crossbar area. The second step is group connection deletion, which structurally prunes connections to reduce routing congestion between crossbars. Tested on convolutional neural networks of LeNet on MNIST database and ConvNet on CIFAR-10 database, our experiments show significant reduction of crossbar area and routing area in NCS designs. Without accuracy loss, rank clipping reduces total crossbar area to 13.62\% and 51.81\% in the NCS designs of LeNet and ConvNet, respectively. Following rank clipping, group connection deletion further reduces the routing area of LeNet and ConvNet to 8.1\% and 52.06\%, respectively.