 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022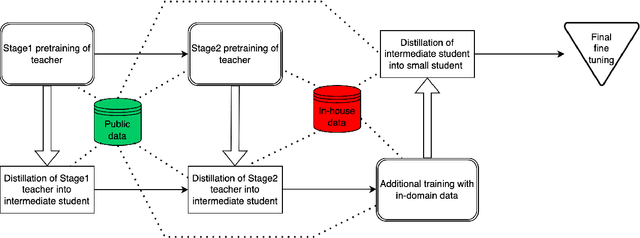
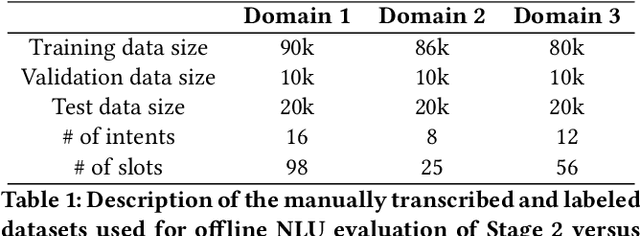
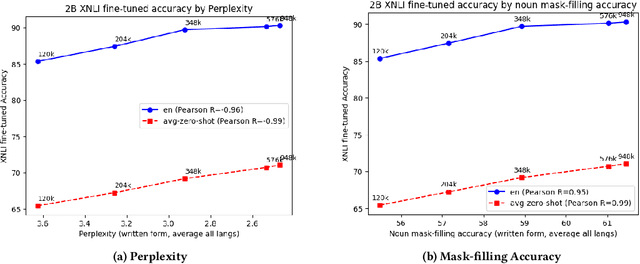
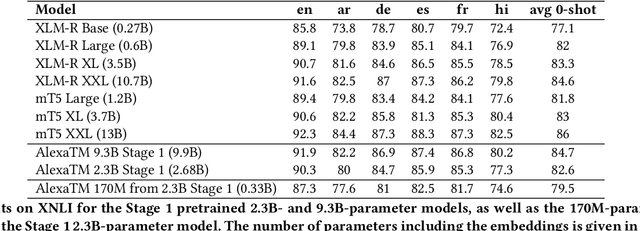
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
A Large-Scale Multilingual Disambiguation of Glosses
Aug 24, 2016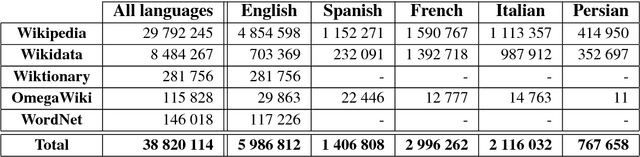


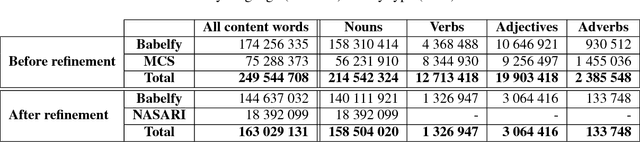
Linking concepts and named entities to knowledge bases has become a crucial Natural Language Understanding task. In this respect, recent works have shown the key advantage of exploiting textual definitions in various Natural Language Processing applications. However, to date there are no reliable large-scale corpora of sense-annotated textual definitions available to the research community. In this paper we present a large-scale high-quality corpus of disambiguated glosses in multiple languages, comprising sense annotations of both concepts and named entities from a unified sense inventory. Our approach for the construction and disambiguation of the corpus builds upon the structure of a large multilingual semantic network and a state-of-the-art disambiguation system; first, we gather complementary information of equivalent definitions across different languages to provide context for disambiguation, and then we combine it with a semantic similarity-based refinement. As a result we obtain a multilingual corpus of textual definitions featuring over 38 million definitions in 263 languages, and we make it freely available at http://lcl.uniroma1.it/disambiguated-glosses. Experiments on Open Information Extraction and Sense Clustering show how two state-of-the-art approaches improve their performance by integrating our disambiguated corpus into their pipeline.
* Accepted in LREC 2016