 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Multilingual Disambiguation of Glosses
Paper and Code
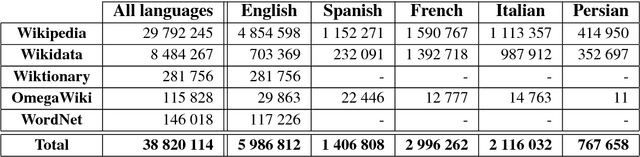


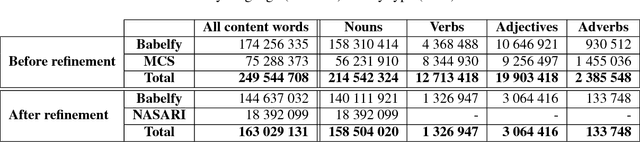
Linking concepts and named entities to knowledge bases has become a crucial Natural Language Understanding task. In this respect, recent works have shown the key advantage of exploiting textual definitions in various Natural Language Processing applications. However, to date there are no reliable large-scale corpora of sense-annotated textual definitions available to the research community. In this paper we present a large-scale high-quality corpus of disambiguated glosses in multiple languages, comprising sense annotations of both concepts and named entities from a unified sense inventory. Our approach for the construction and disambiguation of the corpus builds upon the structure of a large multilingual semantic network and a state-of-the-art disambiguation system; first, we gather complementary information of equivalent definitions across different languages to provide context for disambiguation, and then we combine it with a semantic similarity-based refinement. As a result we obtain a multilingual corpus of textual definitions featuring over 38 million definitions in 263 languages, and we make it freely available at http://lcl.uniroma1.it/disambiguated-glosses. Experiments on Open Information Extraction and Sense Clustering show how two state-of-the-art approaches improve their performance by integrating our disambiguated corpus into their pipeline.