 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Knowledge Editing of Neural Networks
Oct 30, 2023Deep neural networks are becoming increasingly pervasive in academia and industry, matching and surpassing human performance on a wide variety of fields and related tasks. However, just as humans, even the largest artificial neural networks make mistakes, and once-correct predictions can become invalid as the world progresses in time. Augmenting datasets with samples that account for mistakes or up-to-date information has become a common workaround in practical applications. However, the well-known phenomenon of catastrophic forgetting poses a challenge in achieving precise changes in the implicitly memorized knowledge of neural network parameters, often requiring a full model re-training to achieve desired behaviors. That is expensive, unreliable, and incompatible with the current trend of large self-supervised pre-training, making it necessary to find more efficient and effective methods for adapting neural network models to changing data. To address this need, knowledge editing is emerging as a novel area of research that aims to enable reliable, data-efficient, and fast changes to a pre-trained target model, without affecting model behaviors on previously learned tasks. In this survey, we provide a brief review of this recent artificial intelligence field of research. We first introduce the problem of editing neural networks, formalize it in a common framework and differentiate it from more notorious branches of research such as continuous learning. Next, we provide a review of the most relevant knowledge editing approaches and datasets proposed so far, grouping works under four different families: regularization techniques, meta-learning, direct model editing, and architectural strategies. Finally, we outline some intersections with other fields of research and potential directions for future works.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022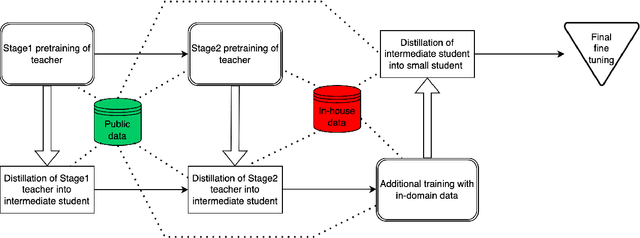
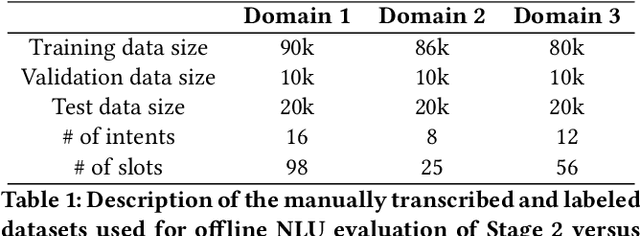
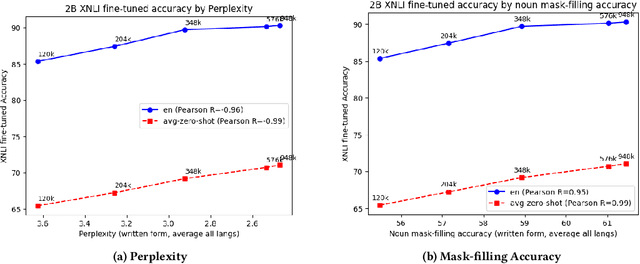
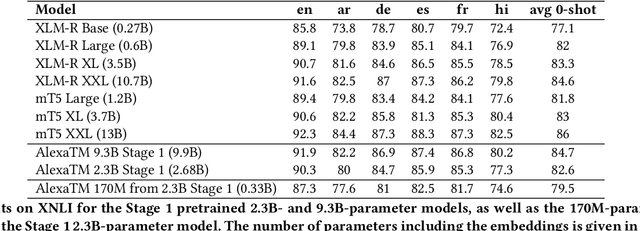
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022