 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4 Can't Reason
Aug 10, 2023GPT-4 was released in March 2023 to wide acclaim, marking a very substantial improvement across the board over GPT-3.5 (OpenAI's previously best model, which had powered the initial release of ChatGPT). However, despite the genuinely impressive improvement, there are good reasons to be highly skeptical of GPT-4's ability to reason. This position paper discusses the nature of reasoning; criticizes the current formulation of reasoning problems in the NLP community, as well as the way in which LLM reasoning performance is currently evaluated; introduces a small collection of 21 diverse reasoning problems; and performs a detailed qualitative evaluation of GPT-4's performance on those problems. Based on this analysis, the paper concludes that, despite its occasional flashes of analytical brilliance, GPT-4 at present is utterly incapable of reasoning.
Low-Resource Compositional Semantic Parsing with Concept Pretraining
Jan 30, 2023Semantic parsing plays a key role in digital voice assistants such as Alexa, Siri, and Google Assistant by mapping natural language to structured meaning representations. When we want to improve the capabilities of a voice assistant by adding a new domain, the underlying semantic parsing model needs to be retrained using thousands of annotated examples from the new domain, which is time-consuming and expensive. In this work, we present an architecture to perform such domain adaptation automatically, with only a small amount of metadata about the new domain and without any new training data (zero-shot) or with very few examples (few-shot). We use a base seq2seq (sequence-to-sequence) architecture and augment it with a concept encoder that encodes intent and slot tags from the new domain. We also introduce a novel decoder-focused approach to pretrain seq2seq models to be concept aware using Wikidata and use it to help our model learn important concepts and perform well in low-resource settings. We report few-shot and zero-shot results for compositional semantic parsing on the TOPv2 dataset and show that our model outperforms prior approaches in few-shot settings for the TOPv2 and SNIPS datasets.
PIZZA: A new benchmark for complex end-to-end task-oriented parsing
Dec 01, 2022Much recent work in task-oriented parsing has focused on finding a middle ground between flat slots and intents, which are inexpressive but easy to annotate, and powerful representations such as the lambda calculus, which are expressive but costly to annotate. This paper continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents. We perform an extensive evaluation of deep-learning techniques for task-oriented parsing on this dataset, including different flavors of seq2seq systems and RNNGs. The dataset comes in two main versions, one in a recently introduced utterance-level hierarchical notation that we call TOP, and one whose targets are executable representations (EXR). We demonstrate empirically that training the parser to directly generate EXR notation not only solves the problem of entity resolution in one fell swoop and overcomes a number of expressive limitations of TOP notation, but also results in significantly greater parsing accuracy.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022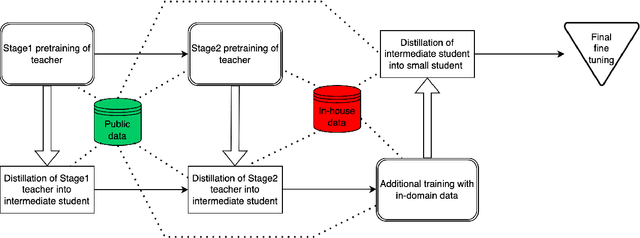
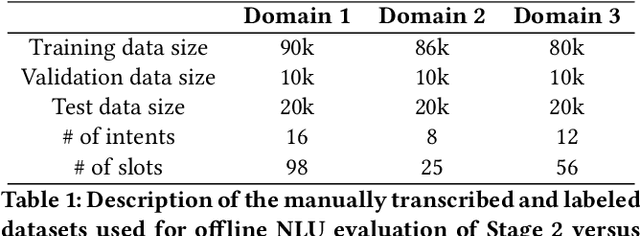
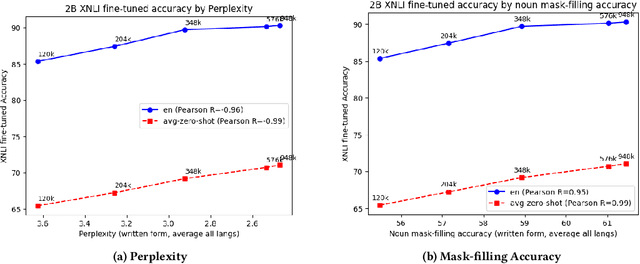
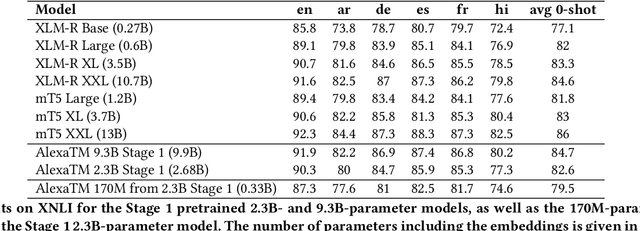
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Cross-TOP: Zero-Shot Cross-Schema Task-Oriented Parsing
Jun 10, 2022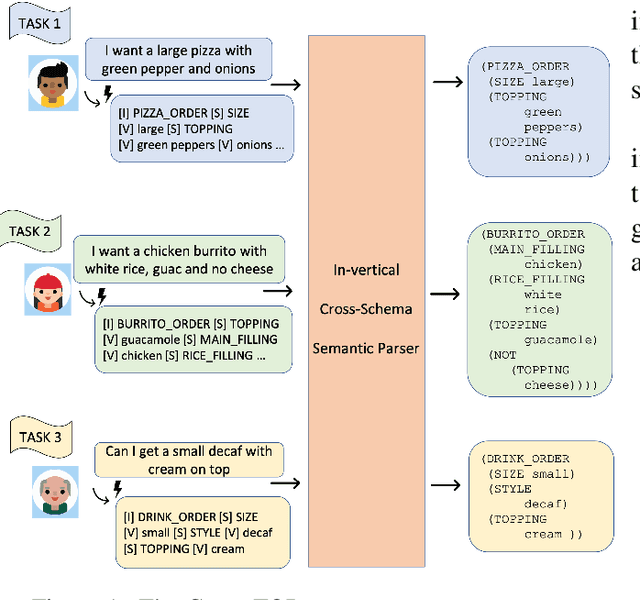


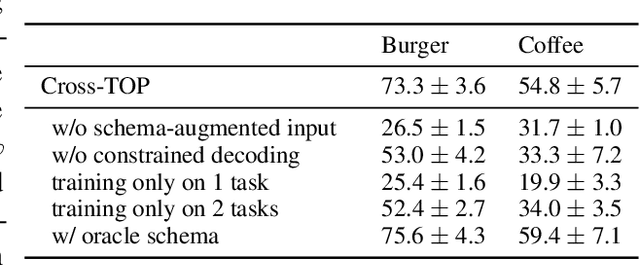
Deep learning methods have enabled task-oriented semantic parsing of increasingly complex utterances. However, a single model is still typically trained and deployed for each task separately, requiring labeled training data for each, which makes it challenging to support new tasks, even within a single business vertical (e.g., food-ordering or travel booking). In this paper we describe Cross-TOP (Cross-Schema Task-Oriented Parsing), a zero-shot method for complex semantic parsing in a given vertical. By leveraging the fact that user requests from the same vertical share lexical and semantic similarities, a single cross-schema parser is trained to service an arbitrary number of tasks, seen or unseen, within a vertical. We show that Cross-TOP can achieve high accuracy on a previously unseen task without requiring any additional training data, thereby providing a scalable way to bootstrap semantic parsers for new tasks. As part of this work we release the FoodOrdering dataset, a task-oriented parsing dataset in the food-ordering vertical, with utterances and annotations derived from five schemas, each from a different restaurant menu.
Training Naturalized Semantic Parsers with Very Little Data
May 04, 2022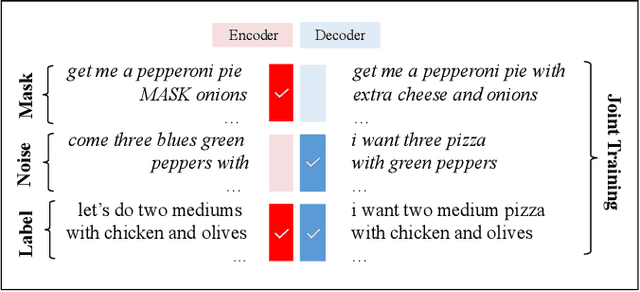
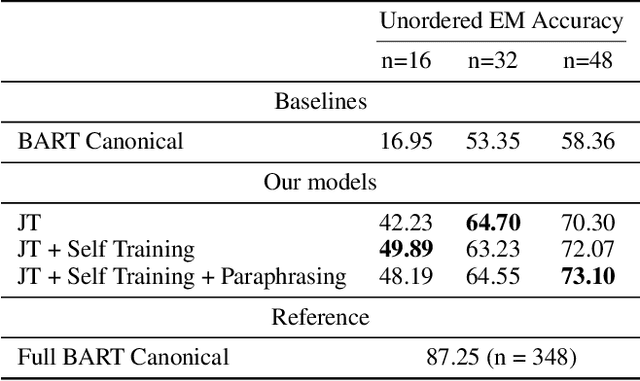
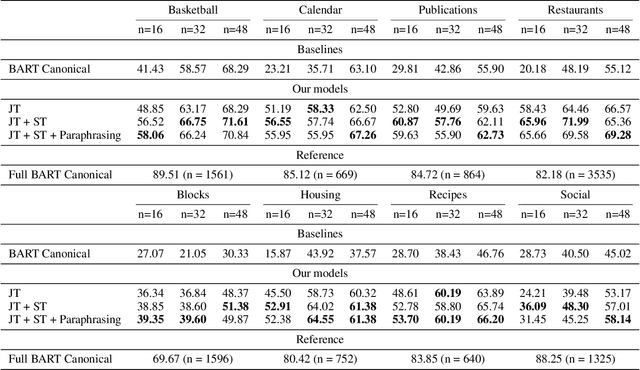
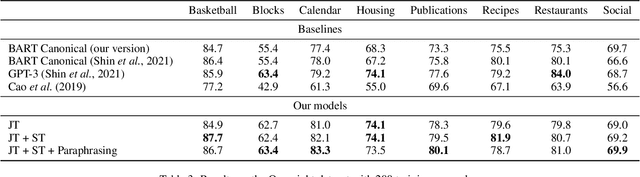
Semantic parsing is an important NLP problem, particularly for voice assistants such as Alexa and Google Assistant. State-of-the-art (SOTA) semantic parsers are seq2seq architectures based on large language models that have been pretrained on vast amounts of text. To better leverage that pretraining, recent work has explored a reformulation of semantic parsing whereby the output sequences are themselves natural language sentences, but in a controlled fragment of natural language. This approach delivers strong results, particularly for few-shot semantic parsing, which is of key importance in practice and the focus of our paper. We push this line of work forward by introducing an automated methodology that delivers very significant additional improvements by utilizing modest amounts of unannotated data, which is typically easy to obtain. Our method is based on a novel synthesis of four techniques: joint training with auxiliary unsupervised tasks; constrained decoding; self-training; and paraphrasing. We show that this method delivers new SOTA few-shot performance on the Overnight dataset, particularly in very low-resource settings, and very compelling few-shot results on a new semantic parsing dataset.
Compositional Task-Oriented Parsing as Abstractive Question Answering
May 04, 2022
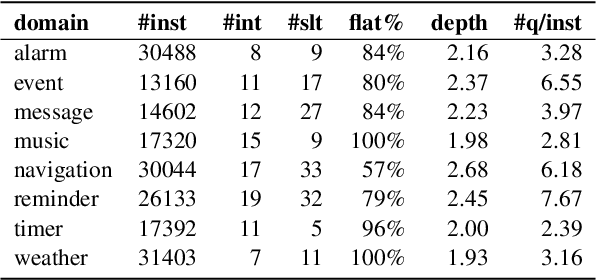
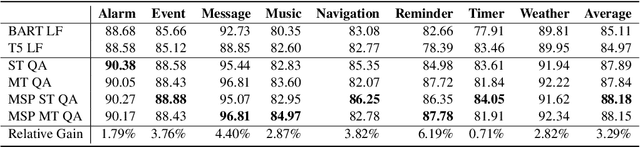

Task-oriented parsing (TOP) aims to convert natural language into machine-readable representations of specific tasks, such as setting an alarm. A popular approach to TOP is to apply seq2seq models to generate linearized parse trees. A more recent line of work argues that pretrained seq2seq models are better at generating outputs that are themselves natural language, so they replace linearized parse trees with canonical natural-language paraphrases that can then be easily translated into parse trees, resulting in so-called naturalized parsers. In this work we continue to explore naturalized semantic parsing by presenting a general reduction of TOP to abstractive question answering that overcomes some limitations of canonical paraphrasing. Experimental results show that our QA-based technique outperforms state-of-the-art methods in full-data settings while achieving dramatic improvements in few-shot settings.
Unfreeze with Care: Space-Efficient Fine-Tuning of Semantic Parsing Models
Mar 05, 2022

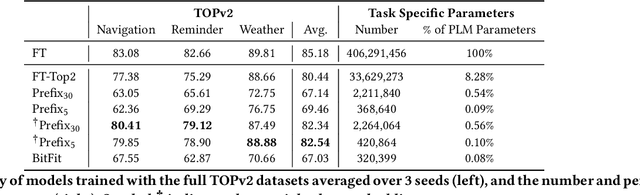
Semantic parsing is a key NLP task that maps natural language to structured meaning representations. As in many other NLP tasks, SOTA performance in semantic parsing is now attained by fine-tuning a large pretrained language model (PLM). While effective, this approach is inefficient in the presence of multiple downstream tasks, as a new set of values for all parameters of the PLM needs to be stored for each task separately. Recent work has explored methods for adapting PLMs to downstream tasks while keeping most (or all) of their parameters frozen. We examine two such promising techniques, prefix tuning and bias-term tuning, specifically on semantic parsing. We compare them against each other on two different semantic parsing datasets, and we also compare them against full and partial fine-tuning, both in few-shot and conventional data settings. While prefix tuning is shown to do poorly for semantic parsing tasks off the shelf, we modify it by adding special token embeddings, which results in very strong performance without compromising parameter savings.
Exploring Transfer Learning For End-to-End Spoken Language Understanding
Dec 15, 2020

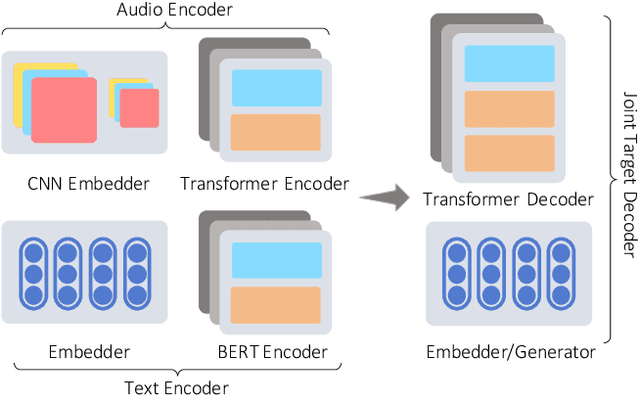

Voice Assistants such as Alexa, Siri, and Google Assistant typically use a two-stage Spoken Language Understanding pipeline; first, an Automatic Speech Recognition (ASR) component to process customer speech and generate text transcriptions, followed by a Natural Language Understanding (NLU) component to map transcriptions to an actionable hypothesis. An end-to-end (E2E) system that goes directly from speech to a hypothesis is a more attractive option. These systems were shown to be smaller, faster, and better optimized. However, they require massive amounts of end-to-end training data and in addition, don't take advantage of the already available ASR and NLU training data. In this work, we propose an E2E system that is designed to jointly train on multiple speech-to-text tasks, such as ASR (speech-transcription) and SLU (speech-hypothesis), and text-to-text tasks, such as NLU (text-hypothesis). We call this the Audio-Text All-Task (AT-AT) Model and we show that it beats the performance of E2E models trained on individual tasks, especially ones trained on limited data. We show this result on an internal music dataset and two public datasets, FluentSpeech and SNIPS Audio, where we achieve state-of-the-art results. Since our model can process both speech and text input sequences and learn to predict a target sequence, it also allows us to do zero-shot E2E SLU by training on only text-hypothesis data (without any speech) from a new domain. We evaluate this ability of our model on the Facebook TOP dataset and set a new benchmark for zeroshot E2E performance. We will soon release the audio data collected for the TOP dataset for future research.
Delexicalized Paraphrase Generation
Dec 04, 2020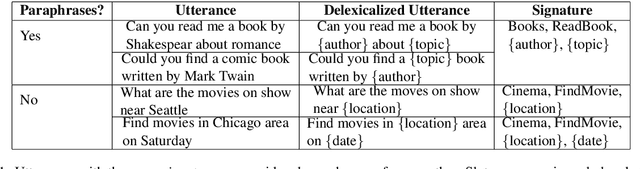
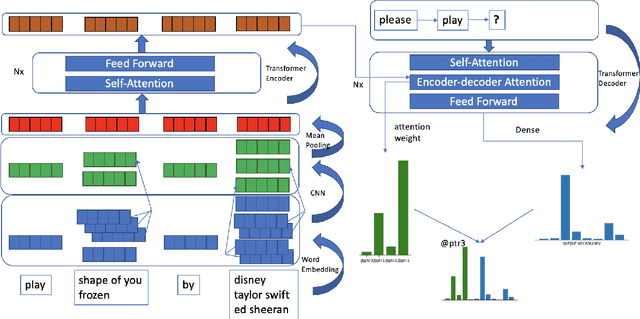

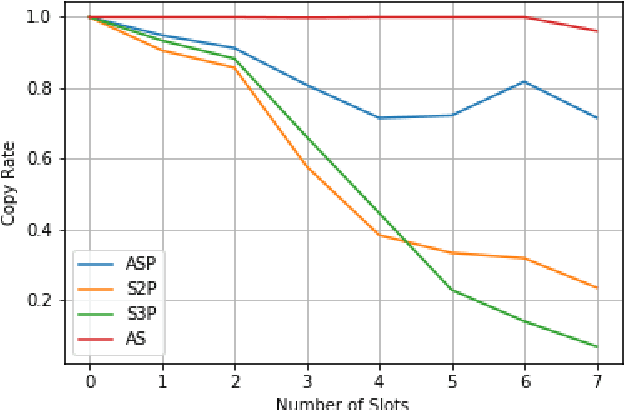
We present a neural model for paraphrasing and train it to generate delexicalized sentences. We achieve this by creating training data in which each input is paired with a number of reference paraphrases. These sets of reference paraphrases represent a weak type of semantic equivalence based on annotated slots and intents. To understand semantics from different types of slots, other than anonymizing slots, we apply convolutional neural networks (CNN) prior to pooling on slot values and use pointers to locate slots in the output. We show empirically that the generated paraphrases are of high quality, leading to an additional 1.29% exact match on live utterances. We also show that natural language understanding (NLU) tasks, such as intent classification and named entity recognition, can benefit from data augmentation using automatically generated paraphrases.