 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJourney Before Destination: On the importance of Visual Faithfulness in Slow Thinking
Dec 19, 2025Reasoning-augmented vision language models (VLMs) generate explicit chains of thought that promise greater capability and transparency but also introduce new failure modes: models may reach correct answers via visually unfaithful intermediate steps, or reason faithfully yet fail on the final prediction. Standard evaluations that only measure final-answer accuracy cannot distinguish these behaviors. We introduce the visual faithfulness of reasoning chains as a distinct evaluation dimension, focusing on whether the perception steps of a reasoning chain are grounded in the image. We propose a training- and reference-free framework that decomposes chains into perception versus reasoning steps and uses off-the-shelf VLM judges for step-level faithfulness, additionally verifying this approach through a human meta-evaluation. Building on this metric, we present a lightweight self-reflection procedure that detects and locally regenerates unfaithful perception steps without any training. Across multiple reasoning-trained VLMs and perception-heavy benchmarks, our method reduces Unfaithful Perception Rate while preserving final-answer accuracy, improving the reliability of multimodal reasoning.
User Persona Identification and New Service Adaptation Recommendation
Nov 15, 2023Providing a personalized user experience on information dense webpages helps users in reaching their end-goals sooner. We explore an automated approach to identifying user personas by leveraging high dimensional trajectory information from user sessions on webpages. While neural collaborative filtering (NCF) approaches pay little attention to token semantics, our method introduces SessionBERT, a Transformer-backed language model trained from scratch on the masked language modeling (mlm) objective for user trajectories (pages, metadata, billing in a session) aiming to capture semantics within them. Our results show that representations learned through SessionBERT are able to consistently outperform a BERT-base model providing a 3% and 1% relative improvement in F1-score for predicting page links and next services. We leverage SessionBERT and extend it to provide recommendations (top-5) for the next most-relevant services that a user would be likely to use. We achieve a HIT@5 of 58% from our recommendation model.
Contextual Dynamic Prompting for Response Generation in Task-oriented Dialog Systems
Feb 10, 2023



Response generation is one of the critical components in task-oriented dialog systems. Existing studies have shown that large pre-trained language models can be adapted to this task. The typical paradigm of adapting such extremely large language models would be by fine-tuning on the downstream tasks which is not only time-consuming but also involves significant resources and access to fine-tuning data. Prompting (Schick and Sch\"utze, 2020) has been an alternative to fine-tuning in many NLP tasks. In our work, we explore the idea of using prompting for response generation in task-oriented dialog systems. Specifically, we propose an approach that performs contextual dynamic prompting where the prompts are learnt from dialog contexts. We aim to distill useful prompting signals from the dialog context. On experiments with MultiWOZ 2.2 dataset (Zang et al., 2020), we show that contextual dynamic prompts improve response generation in terms of combined score (Mehri et al., 2019) by 3 absolute points, and a massive 20 points when dialog states are incorporated. Furthermore, human annotation on these conversations found that agents which incorporate context were preferred over agents with vanilla prefix-tuning.
PIZZA: A new benchmark for complex end-to-end task-oriented parsing
Dec 01, 2022Much recent work in task-oriented parsing has focused on finding a middle ground between flat slots and intents, which are inexpressive but easy to annotate, and powerful representations such as the lambda calculus, which are expressive but costly to annotate. This paper continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents. We perform an extensive evaluation of deep-learning techniques for task-oriented parsing on this dataset, including different flavors of seq2seq systems and RNNGs. The dataset comes in two main versions, one in a recently introduced utterance-level hierarchical notation that we call TOP, and one whose targets are executable representations (EXR). We demonstrate empirically that training the parser to directly generate EXR notation not only solves the problem of entity resolution in one fell swoop and overcomes a number of expressive limitations of TOP notation, but also results in significantly greater parsing accuracy.
"i have a feeling trump will win": Forecasting Winners and Losers from User Predictions on Twitter
Sep 01, 2017


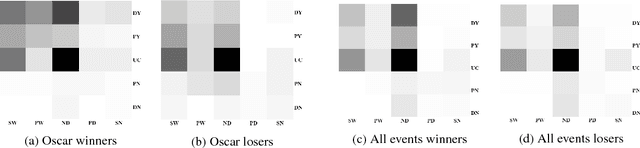
Social media users often make explicit predictions about upcoming events. Such statements vary in the degree of certainty the author expresses toward the outcome:"Leonardo DiCaprio will win Best Actor" vs. "Leonardo DiCaprio may win" or "No way Leonardo wins!". Can popular beliefs on social media predict who will win? To answer this question, we build a corpus of tweets annotated for veridicality on which we train a log-linear classifier that detects positive veridicality with high precision. We then forecast uncertain outcomes using the wisdom of crowds, by aggregating users' explicit predictions. Our method for forecasting winners is fully automated, relying only on a set of contenders as input. It requires no training data of past outcomes and outperforms sentiment and tweet volume baselines on a broad range of contest prediction tasks. We further demonstrate how our approach can be used to measure the reliability of individual accounts' predictions and retrospectively identify surprise outcomes.