 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Non-English Papers Reviewed Fairly? Language-of-Study Bias in NLP Peer Reviews
Apr 08, 2026Peer review plays a central role in the NLP publication process, but is susceptible to various biases. Here, we study language-of-study (LoS) bias: the tendency for reviewers to evaluate a paper differently based on the language(s) it studies, rather than its scientific merit. Despite being explicitly flagged in reviewing guidelines, such biases are poorly understood. Prior work treats such comments as part of broader categories of weak or unconstructive reviews without defining them as a distinct form of bias. We present the first systematic characterization of LoS bias, distinguishing negative and positive forms, and introduce the human-annotated dataset LOBSTER (Language-Of-study Bias in ScienTific pEer Review) and a method achieving 87.37 macro F1 for detection. We analyze 15,645 reviews to estimate how negative and positive biases differ with respect to the LoS, and find that non-English papers face substantially higher bias rates than English-only ones, with negative bias consistently outweighing positive bias. Finally, we identify four subcategories of negative bias, and find that demanding unjustified cross-lingual generalization is the most dominant form. We publicly release all resources to support work on fairer reviewing practices in NLP and beyond.
A survey of diversity quantification in natural language processing: The why, what, where and how
Jul 28, 2025The concept of diversity has received increased consideration in Natural Language Processing (NLP) in recent years. This is due to various motivations like promoting and inclusion, approximating human linguistic behavior, and increasing systems' performance. Diversity has however often been addressed in an ad hoc manner in NLP, and with few explicit links to other domains where this notion is better theorized. We survey articles in the ACL Anthology from the past 6 years, with "diversity" or "diverse" in their title. We find a wide range of settings in which diversity is quantified, often highly specialized and using inconsistent terminology. We put forward a unified taxonomy of why, what on, where, and how diversity is measured in NLP. Diversity measures are cast upon a unified framework from ecology and economy (Stirling, 2007) with 3 dimensions of diversity: variety, balance and disparity. We discuss the trends which emerge due to this systematized approach. We believe that this study paves the way towards a better formalization of diversity in NLP, which should bring a better understanding of this notion and a better comparability between various approaches.
LiTEx: A Linguistic Taxonomy of Explanations for Understanding Within-Label Variation in Natural Language Inference
May 28, 2025



There is increasing evidence of Human Label Variation (HLV) in Natural Language Inference (NLI), where annotators assign different labels to the same premise-hypothesis pair. However, within-label variation--cases where annotators agree on the same label but provide divergent reasoning--poses an additional and mostly overlooked challenge. Several NLI datasets contain highlighted words in the NLI item as explanations, but the same spans on the NLI item can be highlighted for different reasons, as evidenced by free-text explanations, which offer a window into annotators' reasoning. To systematically understand this problem and gain insight into the rationales behind NLI labels, we introduce LITEX, a linguistically-informed taxonomy for categorizing free-text explanations. Using this taxonomy, we annotate a subset of the e-SNLI dataset, validate the taxonomy's reliability, and analyze how it aligns with NLI labels, highlights, and explanations. We further assess the taxonomy's usefulness in explanation generation, demonstrating that conditioning generation on LITEX yields explanations that are linguistically closer to human explanations than those generated using only labels or highlights. Our approach thus not only captures within-label variation but also shows how taxonomy-guided generation for reasoning can bridge the gap between human and model explanations more effectively than existing strategies.
Explanation sensitivity to the randomness of large language models: the case of journalistic text classification
Oct 07, 2024Large language models (LLMs) perform very well in several natural language processing tasks but raise explainability challenges. In this paper, we examine the effect of random elements in the training of LLMs on the explainability of their predictions. We do so on a task of opinionated journalistic text classification in French. Using a fine-tuned CamemBERT model and an explanation method based on relevance propagation, we find that training with different random seeds produces models with similar accuracy but variable explanations. We therefore claim that characterizing the explanations' statistical distribution is needed for the explainability of LLMs. We then explore a simpler model based on textual features which offers stable explanations but is less accurate. Hence, this simpler model corresponds to a different tradeoff between accuracy and explainability. We show that it can be improved by inserting features derived from CamemBERT's explanations. We finally discuss new research directions suggested by our results, in particular regarding the origin of the sensitivity observed in the training randomness.
* This paper is a faithful translation of a paper which was peer-reviewed and published in the French journal Traitement Automatique des Langues, n. 64
VariErr NLI: Separating Annotation Error from Human Label Variation
Mar 04, 2024



Human label variation arises when annotators assign different labels to the same item for valid reasons, while annotation errors occur when labels are assigned for invalid reasons. These two issues are prevalent in NLP benchmarks, yet existing research has studied them in isolation. To the best of our knowledge, there exists no prior work that focuses on teasing apart error from signal, especially in cases where signal is beyond black-and-white. To fill this gap, we introduce a systematic methodology and a new dataset, VariErr (variation versus error), focusing on the NLI task in English. We propose a 2-round annotation scheme with annotators explaining each label and subsequently judging the validity of label-explanation pairs. \name{} contains 7,574 validity judgments on 1,933 explanations for 500 re-annotated NLI items. We assess the effectiveness of various automatic error detection (AED) methods and GPTs in uncovering errors versus human label variation. We find that state-of-the-art AED methods significantly underperform compared to GPTs and humans. While GPT-4 is the best system, it still falls short of human performance. Our methodology is applicable beyond NLI, offering fertile ground for future research on error versus plausible variation, which in turn can yield better and more trustworthy NLP systems.
Ecologically Valid Explanations for Label Variation in NLI
Oct 20, 2023



Human label variation, or annotation disagreement, exists in many natural language processing (NLP) tasks, including natural language inference (NLI). To gain direct evidence of how NLI label variation arises, we build LiveNLI, an English dataset of 1,415 ecologically valid explanations (annotators explain the NLI labels they chose) for 122 MNLI items (at least 10 explanations per item). The LiveNLI explanations confirm that people can systematically vary on their interpretation and highlight within-label variation: annotators sometimes choose the same label for different reasons. This suggests that explanations are crucial for navigating label interpretations in general. We few-shot prompt large language models to generate explanations but the results are inconsistent: they sometimes produces valid and informative explanations, but it also generates implausible ones that do not support the label, highlighting directions for improvement.
Understanding and Predicting Human Label Variation in Natural Language Inference through Explanation
Apr 24, 2023Human label variation (Plank 2022), or annotation disagreement, exists in many natural language processing (NLP) tasks. To be robust and trusted, NLP models need to identify such variation and be able to explain it. To this end, we created the first ecologically valid explanation dataset with diverse reasoning, LiveNLI. LiveNLI contains annotators' highlights and free-text explanations for the label(s) of their choice for 122 English Natural Language Inference items, each with at least 10 annotations. We used its explanations for chain-of-thought prompting, and found there is still room for improvement in GPT-3's ability to predict label distribution with in-context learning.
Investigating Reasons for Disagreement in Natural Language Inference
Sep 07, 2022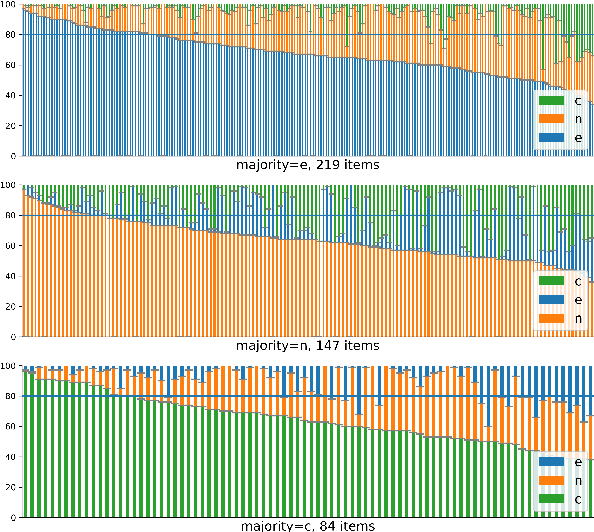
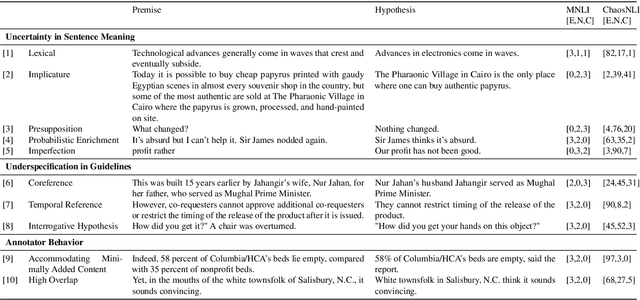
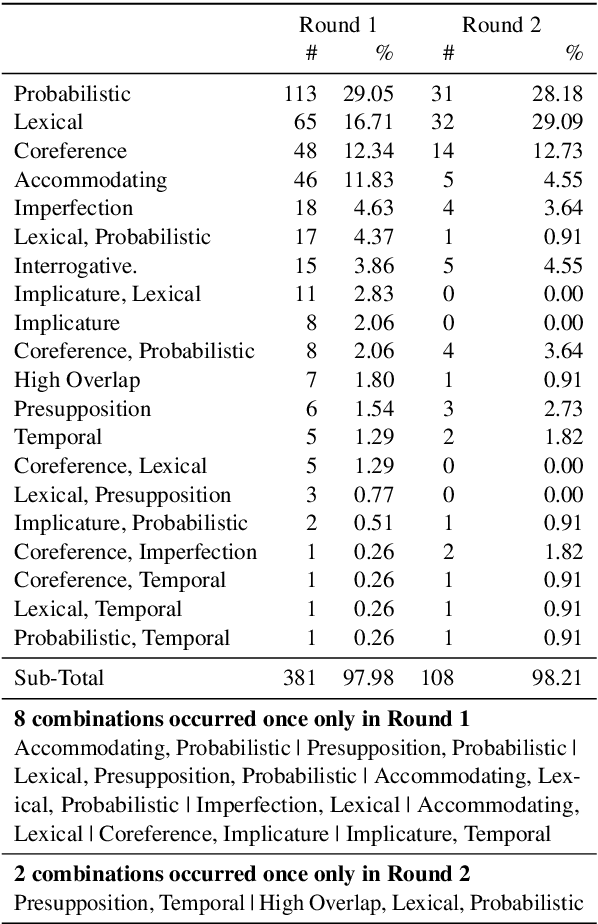
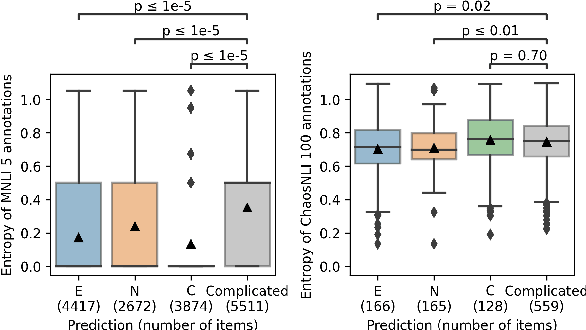
We investigate how disagreement in natural language inference (NLI) annotation arises. We developed a taxonomy of disagreement sources with 10 categories spanning 3 high-level classes. We found that some disagreements are due to uncertainty in the sentence meaning, others to annotator biases and task artifacts, leading to different interpretations of the label distribution. We explore two modeling approaches for detecting items with potential disagreement: a 4-way classification with a "Complicated" label in addition to the three standard NLI labels, and a multilabel classification approach. We found that the multilabel classification is more expressive and gives better recall of the possible interpretations in the data.
He Thinks He Knows Better than the Doctors: BERT for Event Factuality Fails on Pragmatics
Jul 02, 2021
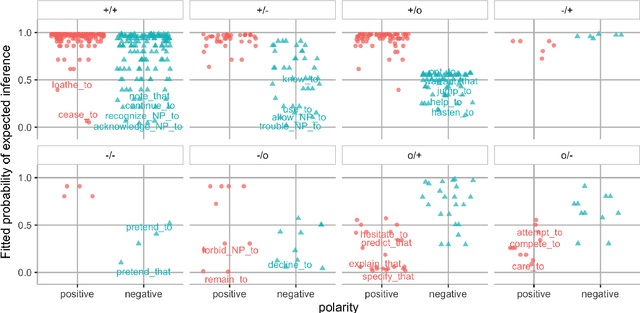

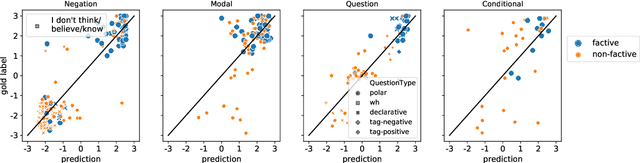
We investigate how well BERT performs on predicting factuality in several existing English datasets, encompassing various linguistic constructions. Although BERT obtains a strong performance on most datasets, it does so by exploiting common surface patterns that correlate with certain factuality labels, and it fails on instances where pragmatic reasoning is necessary. Contrary to what the high performance suggests, we are still far from having a robust system for factuality prediction.
Universal Dependencies v2: An Evergrowing Multilingual Treebank Collection
Apr 22, 2020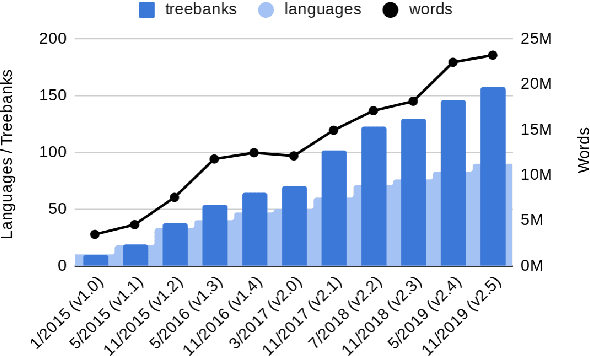
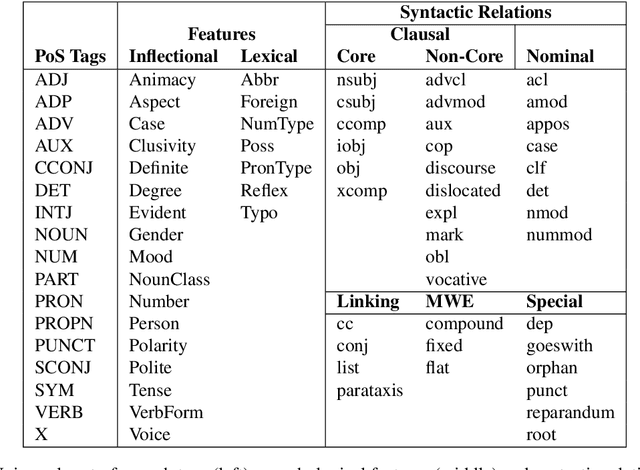
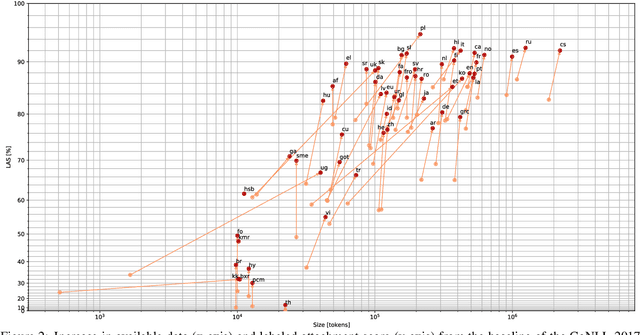
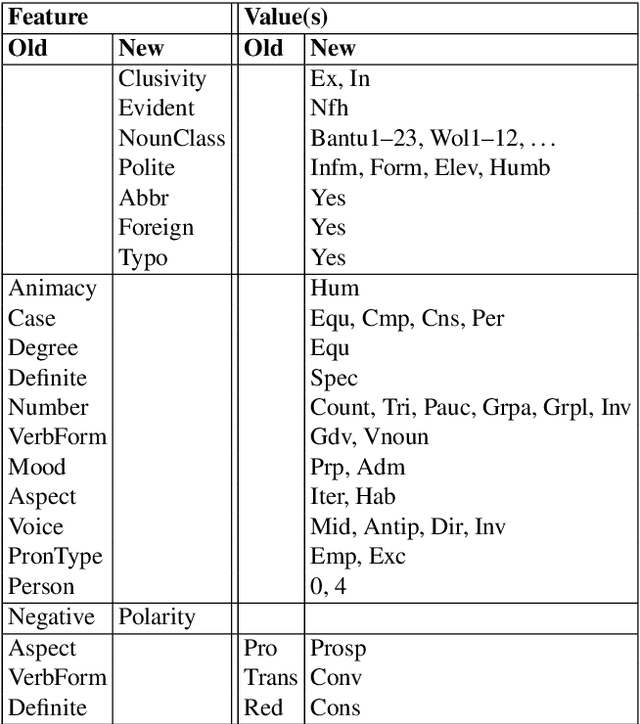
Universal Dependencies is an open community effort to create cross-linguistically consistent treebank annotation for many languages within a dependency-based lexicalist framework. The annotation consists in a linguistically motivated word segmentation; a morphological layer comprising lemmas, universal part-of-speech tags, and standardized morphological features; and a syntactic layer focusing on syntactic relations between predicates, arguments and modifiers. In this paper, we describe version 2 of the guidelines (UD v2), discuss the major changes from UD v1 to UD v2, and give an overview of the currently available treebanks for 90 languages.