 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation sensitivity to the randomness of large language models: the case of journalistic text classification
Oct 07, 2024Large language models (LLMs) perform very well in several natural language processing tasks but raise explainability challenges. In this paper, we examine the effect of random elements in the training of LLMs on the explainability of their predictions. We do so on a task of opinionated journalistic text classification in French. Using a fine-tuned CamemBERT model and an explanation method based on relevance propagation, we find that training with different random seeds produces models with similar accuracy but variable explanations. We therefore claim that characterizing the explanations' statistical distribution is needed for the explainability of LLMs. We then explore a simpler model based on textual features which offers stable explanations but is less accurate. Hence, this simpler model corresponds to a different tradeoff between accuracy and explainability. We show that it can be improved by inserting features derived from CamemBERT's explanations. We finally discuss new research directions suggested by our results, in particular regarding the origin of the sensitivity observed in the training randomness.
* This paper is a faithful translation of a paper which was peer-reviewed and published in the French journal Traitement Automatique des Langues, n. 64
User Preferences for Large Language Model versus Template-Based Explanations of Movie Recommendations: A Pilot Study
Sep 10, 2024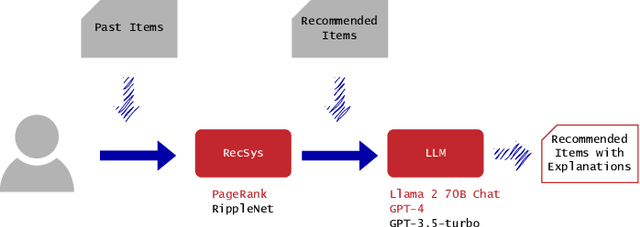
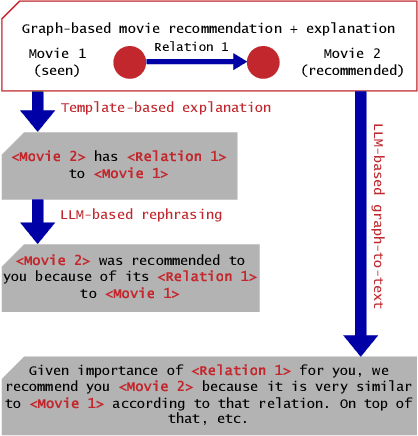

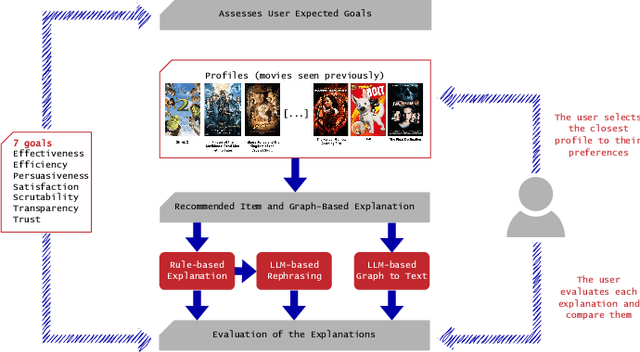
Recommender systems have become integral to our digital experiences, from online shopping to streaming platforms. Still, the rationale behind their suggestions often remains opaque to users. While some systems employ a graph-based approach, offering inherent explainability through paths associating recommended items and seed items, non-experts could not easily understand these explanations. A popular alternative is to convert graph-based explanations into textual ones using a template and an algorithm, which we denote here as ''template-based'' explanations. Yet, these can sometimes come across as impersonal or uninspiring. A novel method would be to employ large language models (LLMs) for this purpose, which we denote as ''LLM-based''. To assess the effectiveness of LLMs in generating more resonant explanations, we conducted a pilot study with 25 participants. They were presented with three explanations: (1) traditional template-based, (2) LLM-based rephrasing of the template output, and (3) purely LLM-based explanations derived from the graph-based explanations. Although subject to high variance, preliminary findings suggest that LLM-based explanations may provide a richer and more engaging user experience, further aligning with user expectations. This study sheds light on the potential limitations of current explanation methods and offers promising directions for leveraging large language models to improve user satisfaction and trust in recommender systems.
A Question on the Explainability of Large Language Models and the Word-Level Univariate First-Order Plausibility Assumption
Mar 15, 2024



The explanations of large language models have recently been shown to be sensitive to the randomness used for their training, creating a need to characterize this sensitivity. In this paper, we propose a characterization that questions the possibility to provide simple and informative explanations for such models. To this end, we give statistical definitions for the explanations' signal, noise and signal-to-noise ratio. We highlight that, in a typical case study where word-level univariate explanations are analyzed with first-order statistical tools, the explanations of simple feature-based models carry more signal and less noise than those of transformer ones. We then discuss the possibility to improve these results with alternative definitions of signal and noise that would capture more complex explanations and analysis methods, while also questioning the tradeoff with their plausibility for readers.