 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcologically Valid Explanations for Label Variation in NLI
Oct 20, 2023



Human label variation, or annotation disagreement, exists in many natural language processing (NLP) tasks, including natural language inference (NLI). To gain direct evidence of how NLI label variation arises, we build LiveNLI, an English dataset of 1,415 ecologically valid explanations (annotators explain the NLI labels they chose) for 122 MNLI items (at least 10 explanations per item). The LiveNLI explanations confirm that people can systematically vary on their interpretation and highlight within-label variation: annotators sometimes choose the same label for different reasons. This suggests that explanations are crucial for navigating label interpretations in general. We few-shot prompt large language models to generate explanations but the results are inconsistent: they sometimes produces valid and informative explanations, but it also generates implausible ones that do not support the label, highlighting directions for improvement.
Understanding and Predicting Human Label Variation in Natural Language Inference through Explanation
Apr 24, 2023Human label variation (Plank 2022), or annotation disagreement, exists in many natural language processing (NLP) tasks. To be robust and trusted, NLP models need to identify such variation and be able to explain it. To this end, we created the first ecologically valid explanation dataset with diverse reasoning, LiveNLI. LiveNLI contains annotators' highlights and free-text explanations for the label(s) of their choice for 122 English Natural Language Inference items, each with at least 10 annotations. We used its explanations for chain-of-thought prompting, and found there is still room for improvement in GPT-3's ability to predict label distribution with in-context learning.
Investigating Reasons for Disagreement in Natural Language Inference
Sep 07, 2022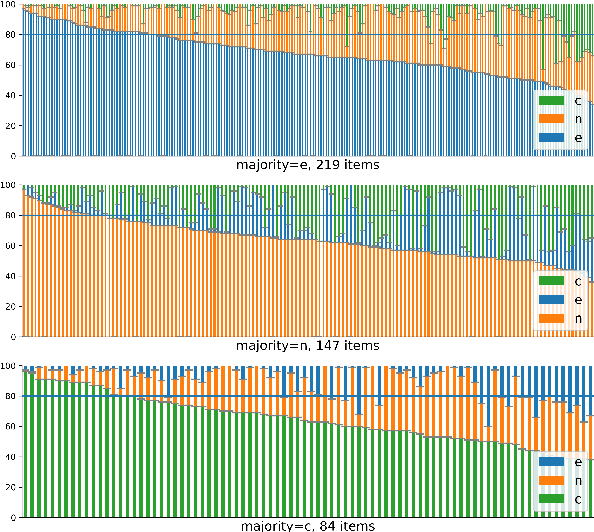
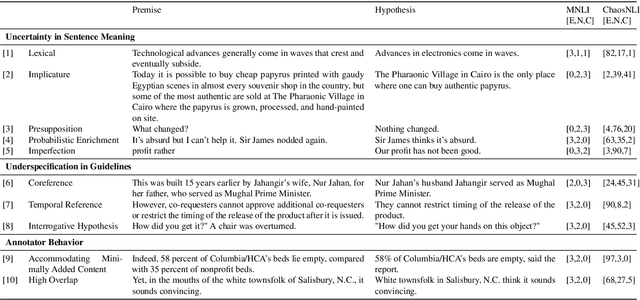
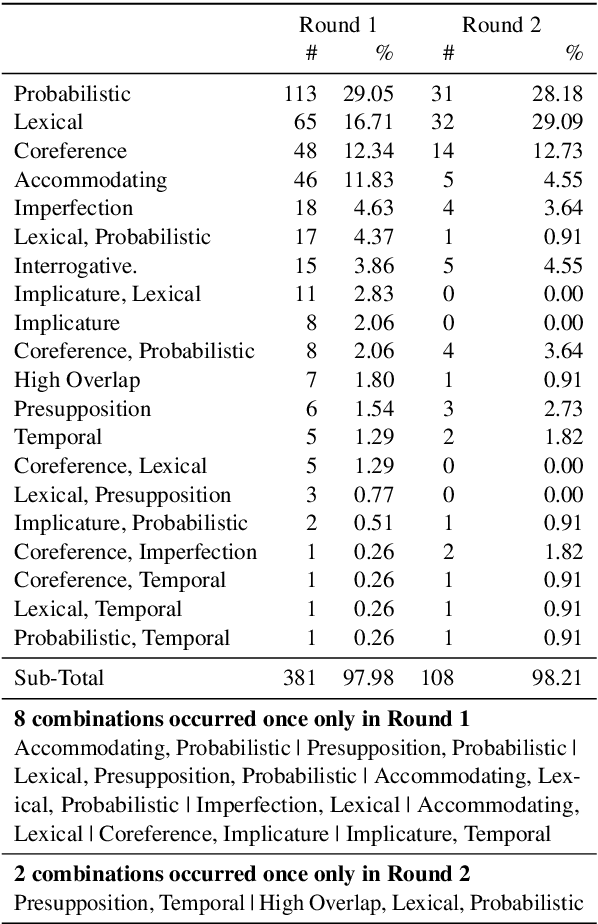
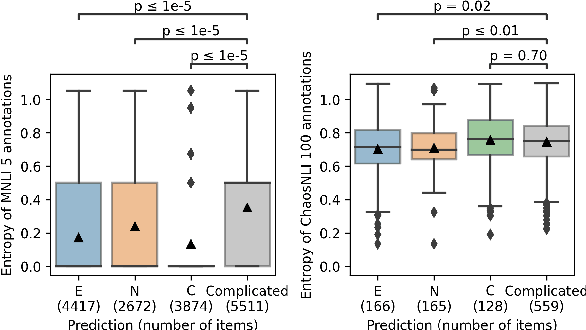
We investigate how disagreement in natural language inference (NLI) annotation arises. We developed a taxonomy of disagreement sources with 10 categories spanning 3 high-level classes. We found that some disagreements are due to uncertainty in the sentence meaning, others to annotator biases and task artifacts, leading to different interpretations of the label distribution. We explore two modeling approaches for detecting items with potential disagreement: a 4-way classification with a "Complicated" label in addition to the three standard NLI labels, and a multilabel classification approach. We found that the multilabel classification is more expressive and gives better recall of the possible interpretations in the data.