 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evaluating LLMs for Multi-Step Tasks: Stepwise Confidence Estimation for Failure Detection
Nov 10, 2025



Reliability and failure detection of large language models (LLMs) is critical for their deployment in high-stakes, multi-step reasoning tasks. Prior work explores confidence estimation for self-evaluating LLM-scorer systems, with confidence scorers estimating the likelihood of errors in LLM responses. However, most methods focus on single-step outputs and overlook the challenges of multi-step reasoning. In this work, we extend self-evaluation techniques to multi-step tasks, testing two intuitive approaches: holistic scoring and step-by-step scoring. Using two multi-step benchmark datasets, we show that stepwise evaluation generally outperforms holistic scoring in detecting potential errors, with up to 15% relative increase in AUC-ROC. Our findings demonstrate that self-evaluating LLM systems provide meaningful confidence estimates in complex reasoning, improving their trustworthiness and providing a practical framework for failure detection.
RMMDet: Road-Side Multitype and Multigroup Sensor Detection System for Autonomous Driving
Mar 10, 2023Autonomous driving has now made great strides thanks to artificial intelligence, and numerous advanced methods have been proposed for vehicle end target detection, including single sensor or multi sensor detection methods. However, the complexity and diversity of real traffic situations necessitate an examination of how to use these methods in real road conditions. In this paper, we propose RMMDet, a road-side multitype and multigroup sensor detection system for autonomous driving. We use a ROS-based virtual environment to simulate real-world conditions, in particular the physical and functional construction of the sensors. Then we implement muti-type sensor detection and multi-group sensors fusion in this environment, including camera-radar and camera-lidar detection based on result-level fusion. We produce local datasets and real sand table field, and conduct various experiments. Furthermore, we link a multi-agent collaborative scheduling system to the fusion detection system. Hence, the whole roadside detection system is formed by roadside perception, fusion detection, and scheduling planning. Through the experiments, it can be seen that RMMDet system we built plays an important role in vehicle-road collaboration and its optimization. The code and supplementary materials can be found at: https://github.com/OrangeSodahub/RMMDet
PIZZA: A new benchmark for complex end-to-end task-oriented parsing
Dec 01, 2022Much recent work in task-oriented parsing has focused on finding a middle ground between flat slots and intents, which are inexpressive but easy to annotate, and powerful representations such as the lambda calculus, which are expressive but costly to annotate. This paper continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents. We perform an extensive evaluation of deep-learning techniques for task-oriented parsing on this dataset, including different flavors of seq2seq systems and RNNGs. The dataset comes in two main versions, one in a recently introduced utterance-level hierarchical notation that we call TOP, and one whose targets are executable representations (EXR). We demonstrate empirically that training the parser to directly generate EXR notation not only solves the problem of entity resolution in one fell swoop and overcomes a number of expressive limitations of TOP notation, but also results in significantly greater parsing accuracy.
Slow Motion Matters: A Slow Motion Enhanced Network for Weakly Supervised Temporal Action Localization
Nov 21, 2022



Weakly supervised temporal action localization (WTAL) aims to localize actions in untrimmed videos with only weak supervision information (e.g. video-level labels). Most existing models handle all input videos with a fixed temporal scale. However, such models are not sensitive to actions whose pace of the movements is different from the ``normal" speed, especially slow-motion action instances, which complete the movements with a much slower speed than their counterparts with a normal speed. Here arises the slow-motion blurred issue: It is hard to explore salient slow-motion information from videos at ``normal" speed. In this paper, we propose a novel framework termed Slow Motion Enhanced Network (SMEN) to improve the ability of a WTAL network by compensating its sensitivity on slow-motion action segments. The proposed SMEN comprises a Mining module and a Localization module. The mining module generates mask to mine slow-motion-related features by utilizing the relationships between the normal motion and slow motion; while the localization module leverages the mined slow-motion features as complementary information to improve the temporal action localization results. Our proposed framework can be easily adapted by existing WTAL networks and enable them be more sensitive to slow-motion actions. Extensive experiments on three benchmarks are conducted, which demonstrate the high performance of our proposed framework.
Cross-TOP: Zero-Shot Cross-Schema Task-Oriented Parsing
Jun 10, 2022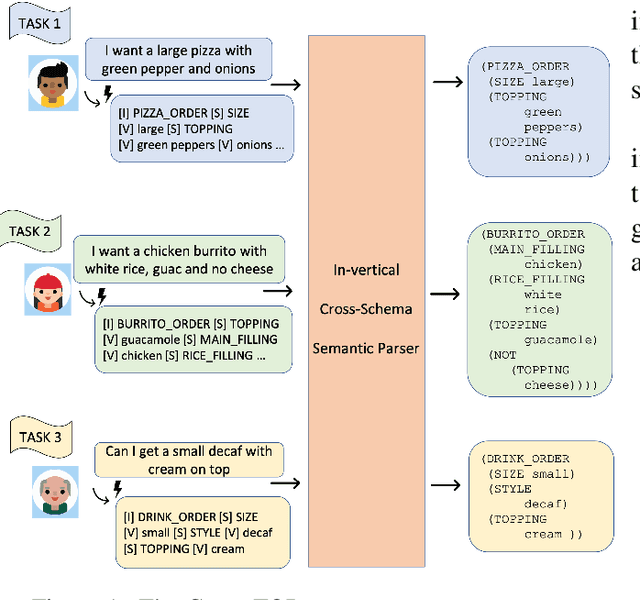


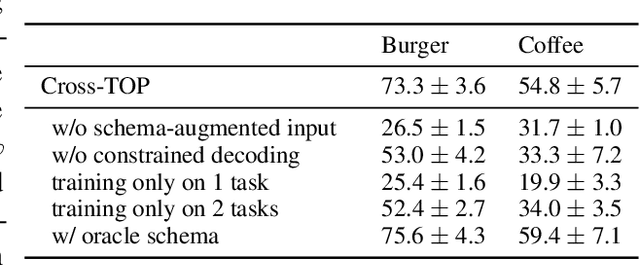
Deep learning methods have enabled task-oriented semantic parsing of increasingly complex utterances. However, a single model is still typically trained and deployed for each task separately, requiring labeled training data for each, which makes it challenging to support new tasks, even within a single business vertical (e.g., food-ordering or travel booking). In this paper we describe Cross-TOP (Cross-Schema Task-Oriented Parsing), a zero-shot method for complex semantic parsing in a given vertical. By leveraging the fact that user requests from the same vertical share lexical and semantic similarities, a single cross-schema parser is trained to service an arbitrary number of tasks, seen or unseen, within a vertical. We show that Cross-TOP can achieve high accuracy on a previously unseen task without requiring any additional training data, thereby providing a scalable way to bootstrap semantic parsers for new tasks. As part of this work we release the FoodOrdering dataset, a task-oriented parsing dataset in the food-ordering vertical, with utterances and annotations derived from five schemas, each from a different restaurant menu.
Compositional Task-Oriented Parsing as Abstractive Question Answering
May 04, 2022
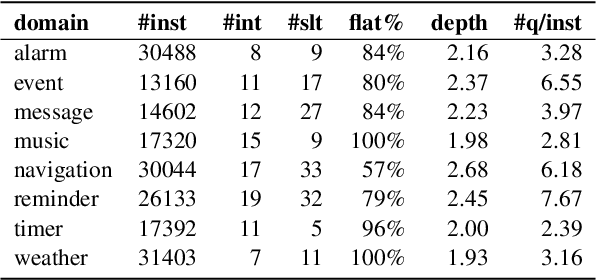
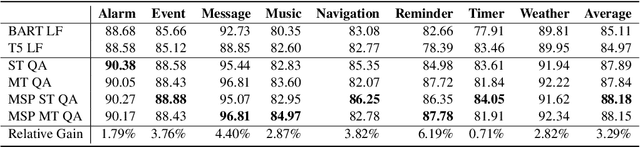

Task-oriented parsing (TOP) aims to convert natural language into machine-readable representations of specific tasks, such as setting an alarm. A popular approach to TOP is to apply seq2seq models to generate linearized parse trees. A more recent line of work argues that pretrained seq2seq models are better at generating outputs that are themselves natural language, so they replace linearized parse trees with canonical natural-language paraphrases that can then be easily translated into parse trees, resulting in so-called naturalized parsers. In this work we continue to explore naturalized semantic parsing by presenting a general reduction of TOP to abstractive question answering that overcomes some limitations of canonical paraphrasing. Experimental results show that our QA-based technique outperforms state-of-the-art methods in full-data settings while achieving dramatic improvements in few-shot settings.
TJ4DRadSet: A 4D Radar Dataset for Autonomous Driving
Apr 30, 2022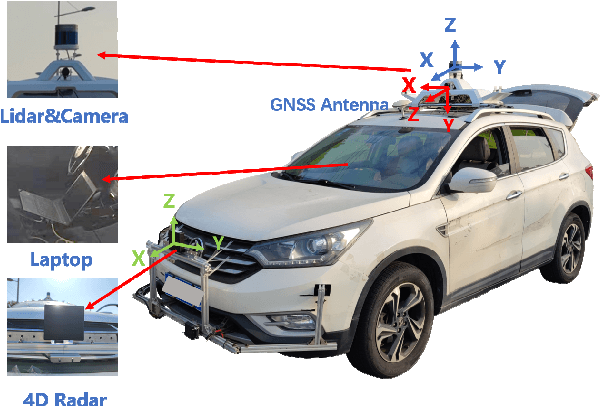
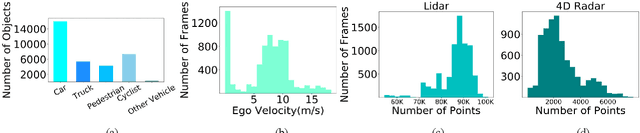

The new generation of 4D high-resolution imaging radar provides not only a huge amount of point cloud but also additional elevation measurement, which has a great potential of 3D sensing in autonomous driving. In this paper, we introduce an autonomous driving dataset named TJ4DRadSet, including multi-modal sensors that are 4D radar, lidar, camera and GNSS, with about 40K frames in total. 7757 frames within 44 consecutive sequences in various driving scenarios are well annotated with 3D bounding boxes and track id. We provide a 4D radar-based 3D object detection baseline for our dataset to demonstrate the effectiveness of deep learning methods for 4D radar point clouds.
Unfreeze with Care: Space-Efficient Fine-Tuning of Semantic Parsing Models
Mar 05, 2022

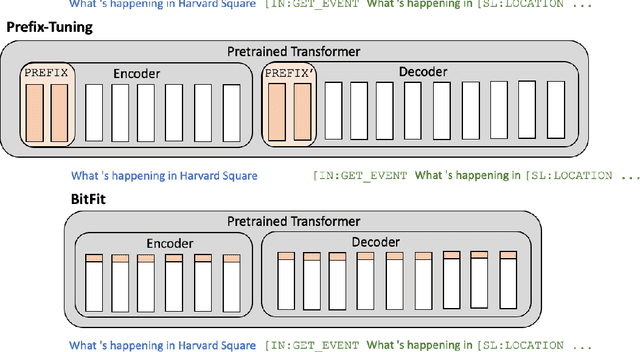
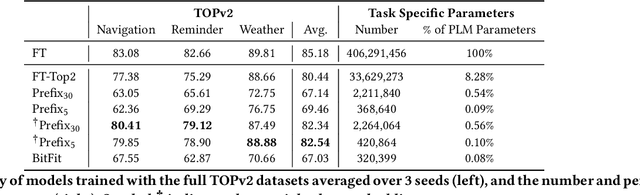
Semantic parsing is a key NLP task that maps natural language to structured meaning representations. As in many other NLP tasks, SOTA performance in semantic parsing is now attained by fine-tuning a large pretrained language model (PLM). While effective, this approach is inefficient in the presence of multiple downstream tasks, as a new set of values for all parameters of the PLM needs to be stored for each task separately. Recent work has explored methods for adapting PLMs to downstream tasks while keeping most (or all) of their parameters frozen. We examine two such promising techniques, prefix tuning and bias-term tuning, specifically on semantic parsing. We compare them against each other on two different semantic parsing datasets, and we also compare them against full and partial fine-tuning, both in few-shot and conventional data settings. While prefix tuning is shown to do poorly for semantic parsing tasks off the shelf, we modify it by adding special token embeddings, which results in very strong performance without compromising parameter savings.