 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIZZA: A new benchmark for complex end-to-end task-oriented parsing
Dec 01, 2022Much recent work in task-oriented parsing has focused on finding a middle ground between flat slots and intents, which are inexpressive but easy to annotate, and powerful representations such as the lambda calculus, which are expressive but costly to annotate. This paper continues the exploration of task-oriented parsing by introducing a new dataset for parsing pizza and drink orders, whose semantics cannot be captured by flat slots and intents. We perform an extensive evaluation of deep-learning techniques for task-oriented parsing on this dataset, including different flavors of seq2seq systems and RNNGs. The dataset comes in two main versions, one in a recently introduced utterance-level hierarchical notation that we call TOP, and one whose targets are executable representations (EXR). We demonstrate empirically that training the parser to directly generate EXR notation not only solves the problem of entity resolution in one fell swoop and overcomes a number of expressive limitations of TOP notation, but also results in significantly greater parsing accuracy.
Cross-TOP: Zero-Shot Cross-Schema Task-Oriented Parsing
Jun 10, 2022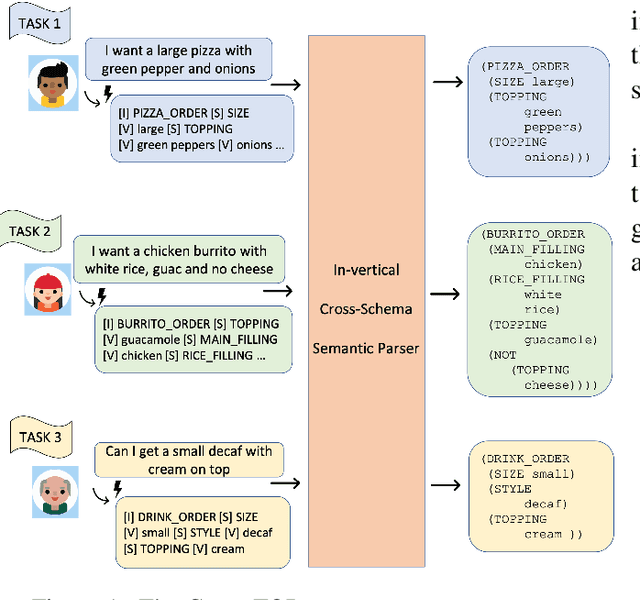


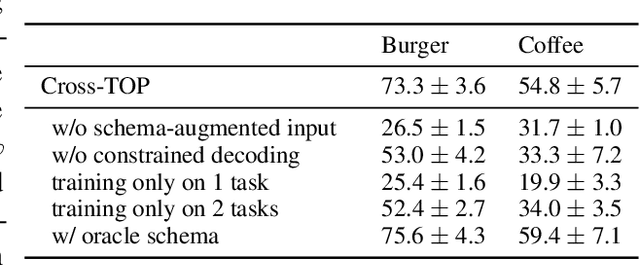
Deep learning methods have enabled task-oriented semantic parsing of increasingly complex utterances. However, a single model is still typically trained and deployed for each task separately, requiring labeled training data for each, which makes it challenging to support new tasks, even within a single business vertical (e.g., food-ordering or travel booking). In this paper we describe Cross-TOP (Cross-Schema Task-Oriented Parsing), a zero-shot method for complex semantic parsing in a given vertical. By leveraging the fact that user requests from the same vertical share lexical and semantic similarities, a single cross-schema parser is trained to service an arbitrary number of tasks, seen or unseen, within a vertical. We show that Cross-TOP can achieve high accuracy on a previously unseen task without requiring any additional training data, thereby providing a scalable way to bootstrap semantic parsers for new tasks. As part of this work we release the FoodOrdering dataset, a task-oriented parsing dataset in the food-ordering vertical, with utterances and annotations derived from five schemas, each from a different restaurant menu.
Training Naturalized Semantic Parsers with Very Little Data
May 04, 2022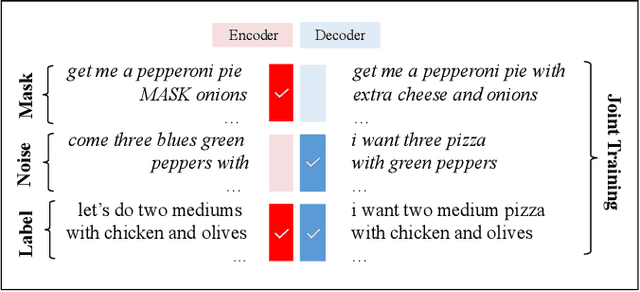
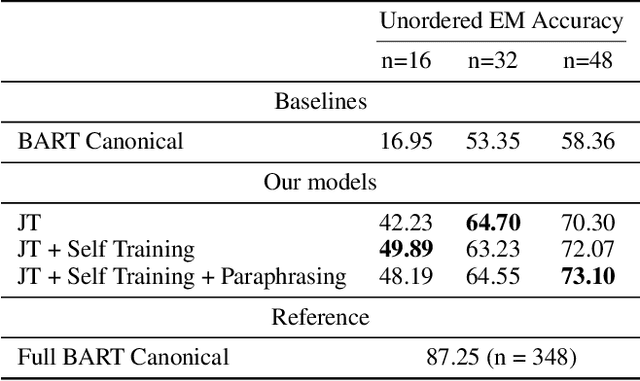
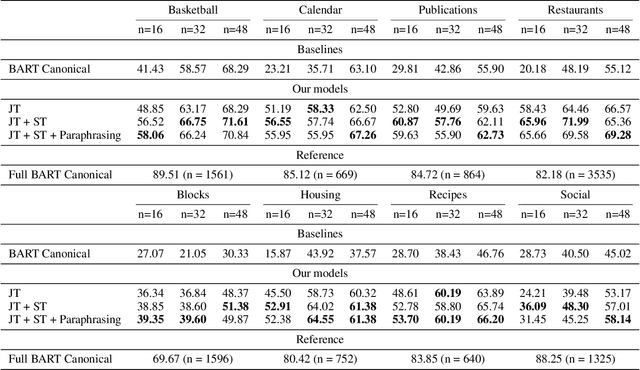
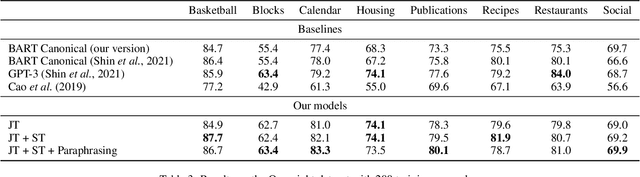
Semantic parsing is an important NLP problem, particularly for voice assistants such as Alexa and Google Assistant. State-of-the-art (SOTA) semantic parsers are seq2seq architectures based on large language models that have been pretrained on vast amounts of text. To better leverage that pretraining, recent work has explored a reformulation of semantic parsing whereby the output sequences are themselves natural language sentences, but in a controlled fragment of natural language. This approach delivers strong results, particularly for few-shot semantic parsing, which is of key importance in practice and the focus of our paper. We push this line of work forward by introducing an automated methodology that delivers very significant additional improvements by utilizing modest amounts of unannotated data, which is typically easy to obtain. Our method is based on a novel synthesis of four techniques: joint training with auxiliary unsupervised tasks; constrained decoding; self-training; and paraphrasing. We show that this method delivers new SOTA few-shot performance on the Overnight dataset, particularly in very low-resource settings, and very compelling few-shot results on a new semantic parsing dataset.
Unfreeze with Care: Space-Efficient Fine-Tuning of Semantic Parsing Models
Mar 05, 2022

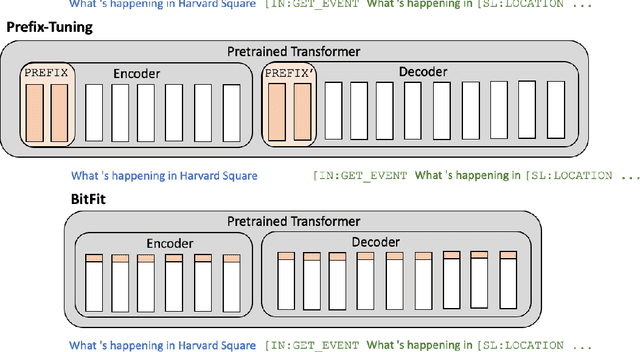
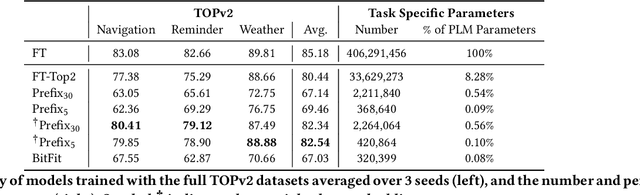
Semantic parsing is a key NLP task that maps natural language to structured meaning representations. As in many other NLP tasks, SOTA performance in semantic parsing is now attained by fine-tuning a large pretrained language model (PLM). While effective, this approach is inefficient in the presence of multiple downstream tasks, as a new set of values for all parameters of the PLM needs to be stored for each task separately. Recent work has explored methods for adapting PLMs to downstream tasks while keeping most (or all) of their parameters frozen. We examine two such promising techniques, prefix tuning and bias-term tuning, specifically on semantic parsing. We compare them against each other on two different semantic parsing datasets, and we also compare them against full and partial fine-tuning, both in few-shot and conventional data settings. While prefix tuning is shown to do poorly for semantic parsing tasks off the shelf, we modify it by adding special token embeddings, which results in very strong performance without compromising parameter savings.