 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Compositional Semantic Parsing with Concept Pretraining
Jan 30, 2023Semantic parsing plays a key role in digital voice assistants such as Alexa, Siri, and Google Assistant by mapping natural language to structured meaning representations. When we want to improve the capabilities of a voice assistant by adding a new domain, the underlying semantic parsing model needs to be retrained using thousands of annotated examples from the new domain, which is time-consuming and expensive. In this work, we present an architecture to perform such domain adaptation automatically, with only a small amount of metadata about the new domain and without any new training data (zero-shot) or with very few examples (few-shot). We use a base seq2seq (sequence-to-sequence) architecture and augment it with a concept encoder that encodes intent and slot tags from the new domain. We also introduce a novel decoder-focused approach to pretrain seq2seq models to be concept aware using Wikidata and use it to help our model learn important concepts and perform well in low-resource settings. We report few-shot and zero-shot results for compositional semantic parsing on the TOPv2 dataset and show that our model outperforms prior approaches in few-shot settings for the TOPv2 and SNIPS datasets.
Training Naturalized Semantic Parsers with Very Little Data
May 04, 2022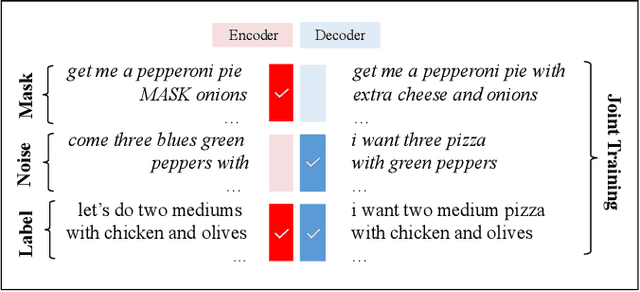
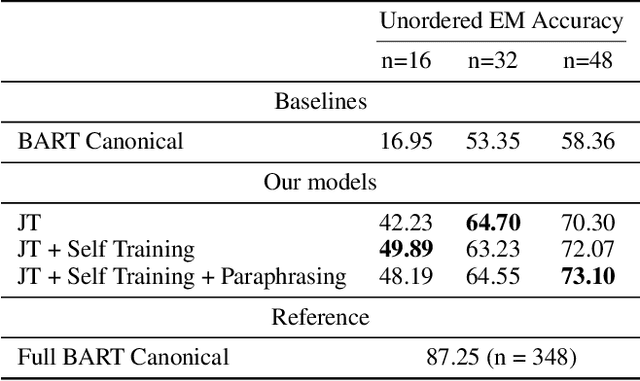
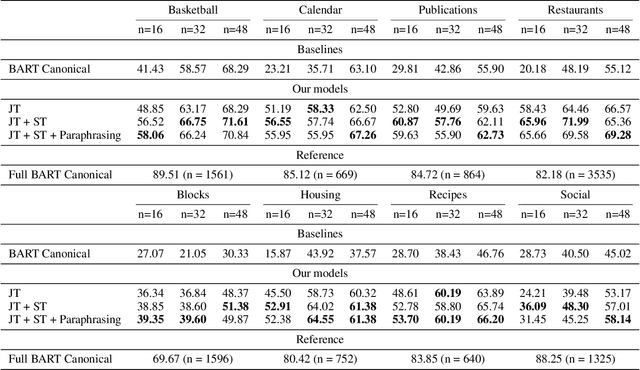
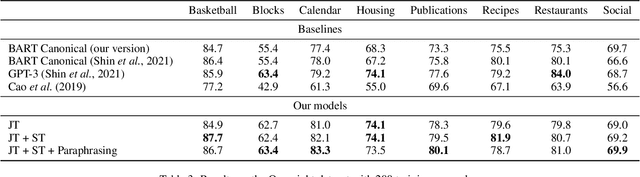
Semantic parsing is an important NLP problem, particularly for voice assistants such as Alexa and Google Assistant. State-of-the-art (SOTA) semantic parsers are seq2seq architectures based on large language models that have been pretrained on vast amounts of text. To better leverage that pretraining, recent work has explored a reformulation of semantic parsing whereby the output sequences are themselves natural language sentences, but in a controlled fragment of natural language. This approach delivers strong results, particularly for few-shot semantic parsing, which is of key importance in practice and the focus of our paper. We push this line of work forward by introducing an automated methodology that delivers very significant additional improvements by utilizing modest amounts of unannotated data, which is typically easy to obtain. Our method is based on a novel synthesis of four techniques: joint training with auxiliary unsupervised tasks; constrained decoding; self-training; and paraphrasing. We show that this method delivers new SOTA few-shot performance on the Overnight dataset, particularly in very low-resource settings, and very compelling few-shot results on a new semantic parsing dataset.
Improved Latent Tree Induction with Distant Supervision via Span Constraints
Sep 10, 2021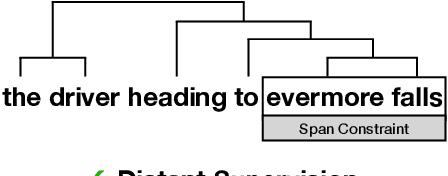

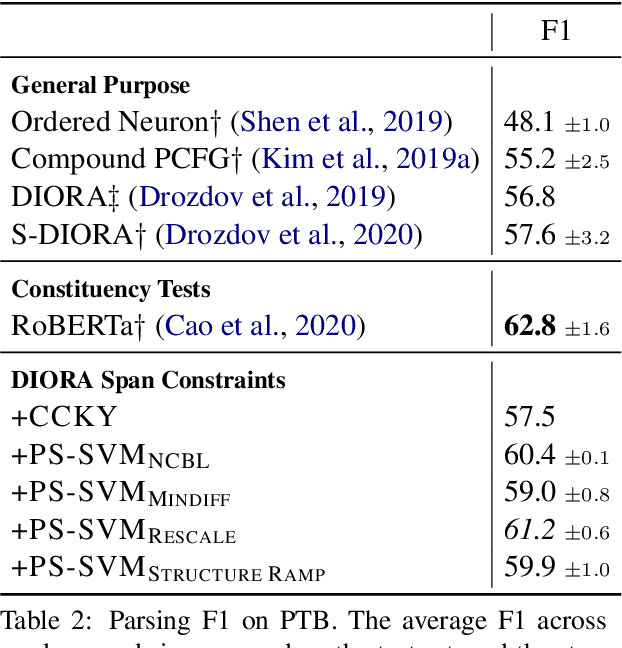
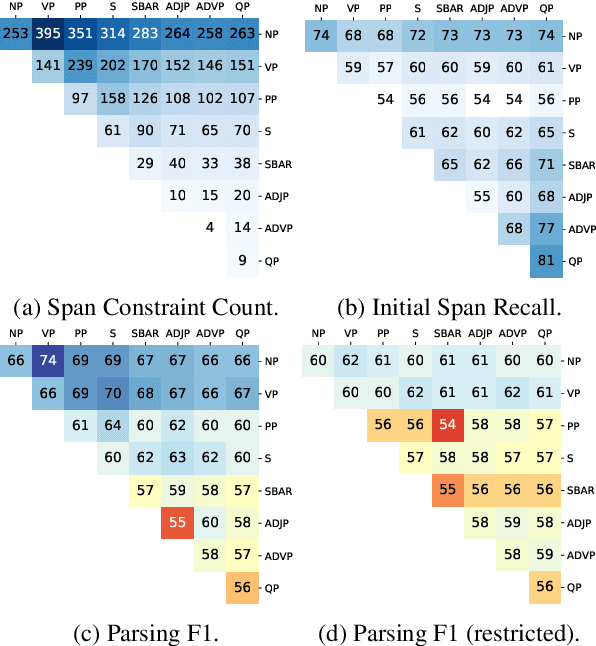
For over thirty years, researchers have developed and analyzed methods for latent tree induction as an approach for unsupervised syntactic parsing. Nonetheless, modern systems still do not perform well enough compared to their supervised counterparts to have any practical use as structural annotation of text. In this work, we present a technique that uses distant supervision in the form of span constraints (i.e. phrase bracketing) to improve performance in unsupervised constituency parsing. Using a relatively small number of span constraints we can substantially improve the output from DIORA, an already competitive unsupervised parsing system. Compared with full parse tree annotation, span constraints can be acquired with minimal effort, such as with a lexicon derived from Wikipedia, to find exact text matches. Our experiments show span constraints based on entities improves constituency parsing on English WSJ Penn Treebank by more than 5 F1. Furthermore, our method extends to any domain where span constraints are easily attainable, and as a case study we demonstrate its effectiveness by parsing biomedical text from the CRAFT dataset.
Exploring Transfer Learning For End-to-End Spoken Language Understanding
Dec 15, 2020

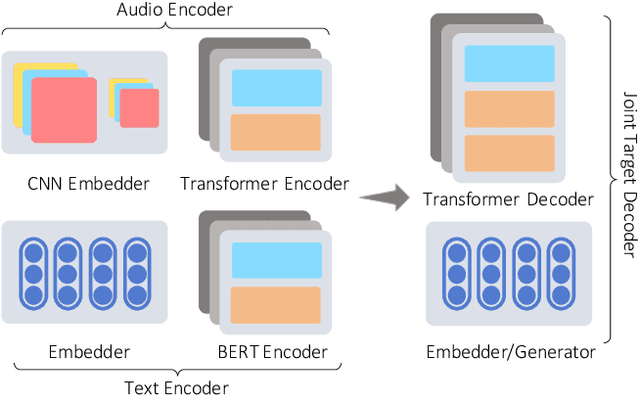

Voice Assistants such as Alexa, Siri, and Google Assistant typically use a two-stage Spoken Language Understanding pipeline; first, an Automatic Speech Recognition (ASR) component to process customer speech and generate text transcriptions, followed by a Natural Language Understanding (NLU) component to map transcriptions to an actionable hypothesis. An end-to-end (E2E) system that goes directly from speech to a hypothesis is a more attractive option. These systems were shown to be smaller, faster, and better optimized. However, they require massive amounts of end-to-end training data and in addition, don't take advantage of the already available ASR and NLU training data. In this work, we propose an E2E system that is designed to jointly train on multiple speech-to-text tasks, such as ASR (speech-transcription) and SLU (speech-hypothesis), and text-to-text tasks, such as NLU (text-hypothesis). We call this the Audio-Text All-Task (AT-AT) Model and we show that it beats the performance of E2E models trained on individual tasks, especially ones trained on limited data. We show this result on an internal music dataset and two public datasets, FluentSpeech and SNIPS Audio, where we achieve state-of-the-art results. Since our model can process both speech and text input sequences and learn to predict a target sequence, it also allows us to do zero-shot E2E SLU by training on only text-hypothesis data (without any speech) from a new domain. We evaluate this ability of our model on the Facebook TOP dataset and set a new benchmark for zeroshot E2E performance. We will soon release the audio data collected for the TOP dataset for future research.
Compressing Transformer-Based Semantic Parsing Models using Compositional Code Embeddings
Oct 10, 2020
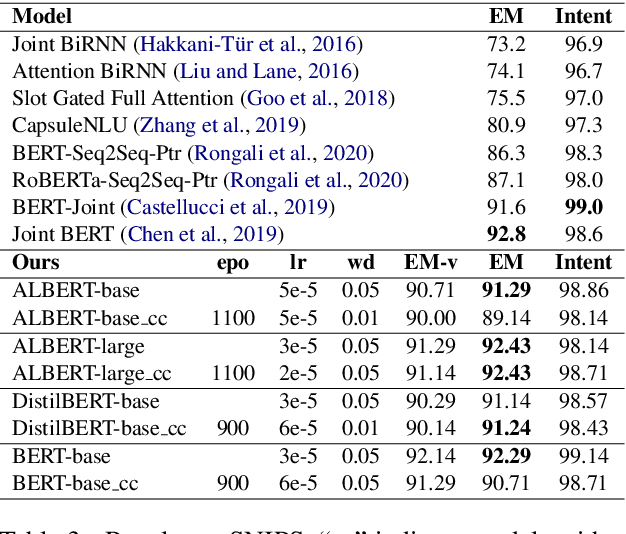
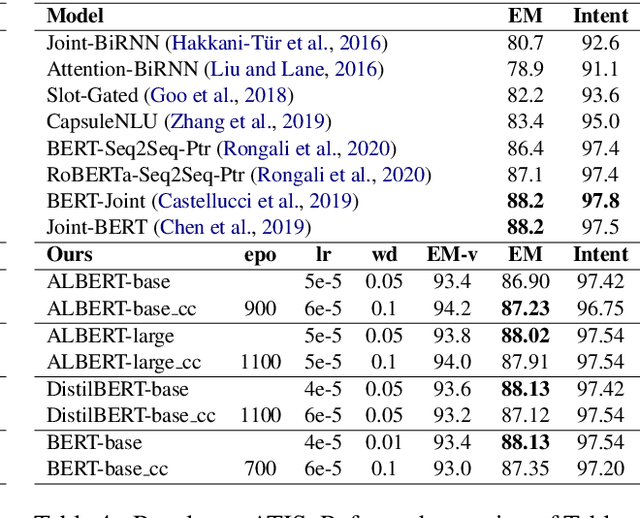
The current state-of-the-art task-oriented semantic parsing models use BERT or RoBERTa as pretrained encoders; these models have huge memory footprints. This poses a challenge to their deployment for voice assistants such as Amazon Alexa and Google Assistant on edge devices with limited memory budgets. We propose to learn compositional code embeddings to greatly reduce the sizes of BERT-base and RoBERTa-base. We also apply the technique to DistilBERT, ALBERT-base, and ALBERT-large, three already compressed BERT variants which attain similar state-of-the-art performances on semantic parsing with much smaller model sizes. We observe 95.15% ~ 98.46% embedding compression rates and 20.47% ~ 34.22% encoder compression rates, while preserving greater than 97.5% semantic parsing performances. We provide the recipe for training and analyze the trade-off between code embedding sizes and downstream performances.
Improved Pretraining for Domain-specific Contextual Embedding Models
Apr 05, 2020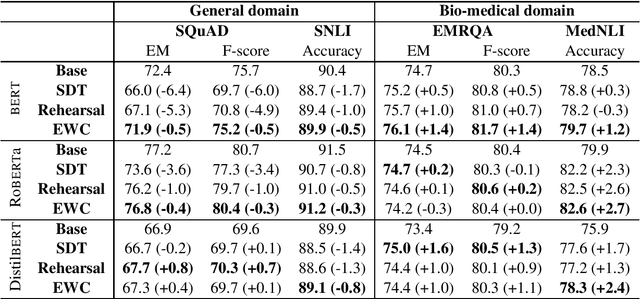
We investigate methods to mitigate catastrophic forgetting during domain-specific pretraining of contextual embedding models such as BERT, DistilBERT, and RoBERTa. Recently proposed domain-specific models such as BioBERT, SciBERT and ClinicalBERT are constructed by continuing the pretraining phase on a domain-specific text corpus. Such pretraining is susceptible to catastrophic forgetting, where the model forgets some of the information learned in the general domain. We propose the use of two continual learning techniques (rehearsal and elastic weight consolidation) to improve domain-specific training. Our results show that models trained by our proposed approaches can better maintain their performance on the general domain tasks, and at the same time, outperform domain-specific baseline models on downstream domain tasks.
Don't Parse, Generate! A Sequence to Sequence Architecture for Task-Oriented Semantic Parsing
Jan 30, 2020

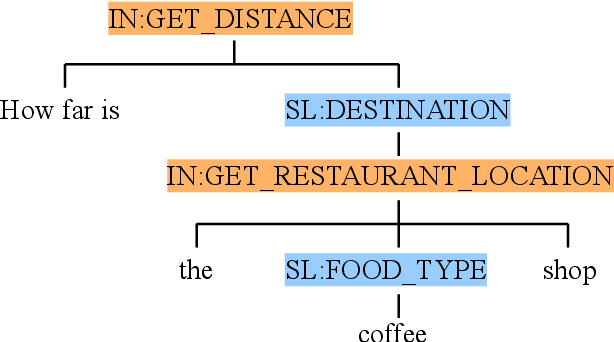
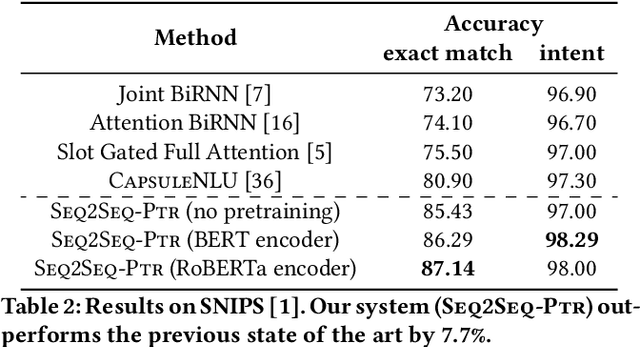
Virtual assistants such as Amazon Alexa, Apple Siri, and Google Assistant often rely on a semantic parsing component to understand which action(s) to execute for an utterance spoken by its users. Traditionally, rule-based or statistical slot-filling systems have been used to parse "simple" queries; that is, queries that contain a single action and can be decomposed into a set of non-overlapping entities. More recently, shift-reduce parsers have been proposed to process more complex utterances. These methods, while powerful, impose specific limitations on the type of queries that can be parsed; namely, they require a query to be representable as a parse tree. In this work, we propose a unified architecture based on Sequence to Sequence models and Pointer Generator Network to handle both simple and complex queries. Unlike other works, our approach does not impose any restriction on the semantic parse schema. Furthermore, experiments show that it achieves state of the art performance on three publicly available datasets (ATIS, SNIPS, Facebook TOP), relatively improving between 3.3% and 7.7% in exact match accuracy over previous systems. Finally, we show the effectiveness of our approach on two internal datasets.
Taxonomy grounded aggregation of classifiers with different label sets
Dec 01, 2015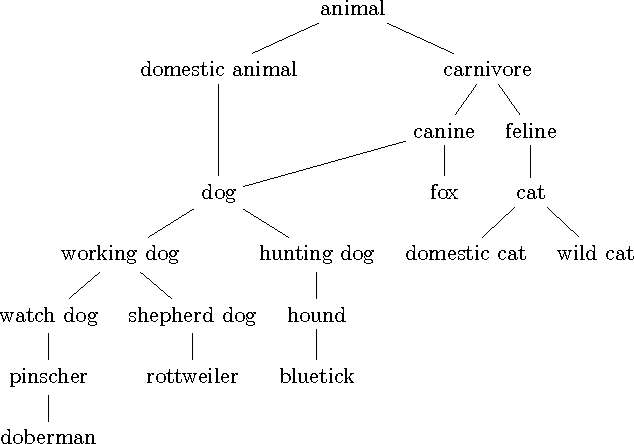
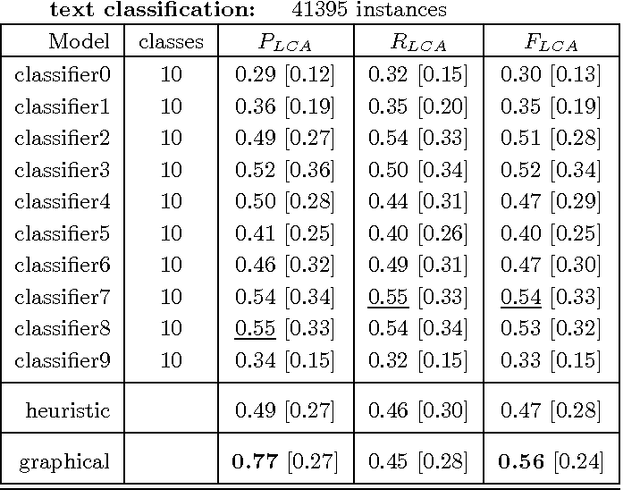
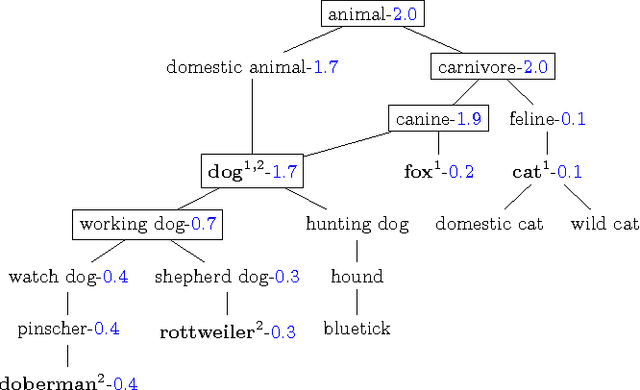
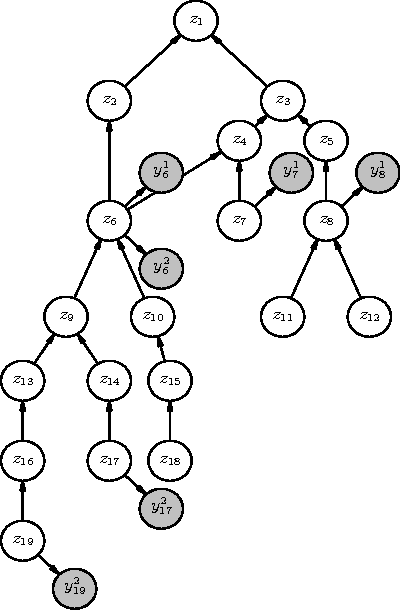
We describe the problem of aggregating the label predictions of diverse classifiers using a class taxonomy. Such a taxonomy may not have been available or referenced when the individual classifiers were designed and trained, yet mapping the output labels into the taxonomy is desirable to integrate the effort spent in training the constituent classifiers. A hierarchical taxonomy representing some domain knowledge may be different from, but partially mappable to, the label sets of the individual classifiers. We present a heuristic approach and a principled graphical model to aggregate the label predictions by grounding them into the available taxonomy. Our model aggregates the labels using the taxonomy structure as constraints to find the most likely hierarchically consistent class. We experimentally validate our proposed method on image and text classification tasks.