 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Apr 04, 2024



We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., <1B) language model (LM) for guiding a black-box large (i.e., >10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
Exploring Transfer Learning For End-to-End Spoken Language Understanding
Dec 15, 2020

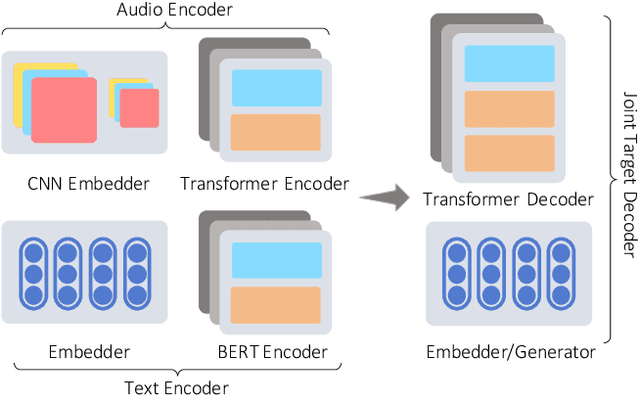

Voice Assistants such as Alexa, Siri, and Google Assistant typically use a two-stage Spoken Language Understanding pipeline; first, an Automatic Speech Recognition (ASR) component to process customer speech and generate text transcriptions, followed by a Natural Language Understanding (NLU) component to map transcriptions to an actionable hypothesis. An end-to-end (E2E) system that goes directly from speech to a hypothesis is a more attractive option. These systems were shown to be smaller, faster, and better optimized. However, they require massive amounts of end-to-end training data and in addition, don't take advantage of the already available ASR and NLU training data. In this work, we propose an E2E system that is designed to jointly train on multiple speech-to-text tasks, such as ASR (speech-transcription) and SLU (speech-hypothesis), and text-to-text tasks, such as NLU (text-hypothesis). We call this the Audio-Text All-Task (AT-AT) Model and we show that it beats the performance of E2E models trained on individual tasks, especially ones trained on limited data. We show this result on an internal music dataset and two public datasets, FluentSpeech and SNIPS Audio, where we achieve state-of-the-art results. Since our model can process both speech and text input sequences and learn to predict a target sequence, it also allows us to do zero-shot E2E SLU by training on only text-hypothesis data (without any speech) from a new domain. We evaluate this ability of our model on the Facebook TOP dataset and set a new benchmark for zeroshot E2E performance. We will soon release the audio data collected for the TOP dataset for future research.
Improving Spoken Language Understanding By Exploiting ASR N-best Hypotheses
Jan 11, 2020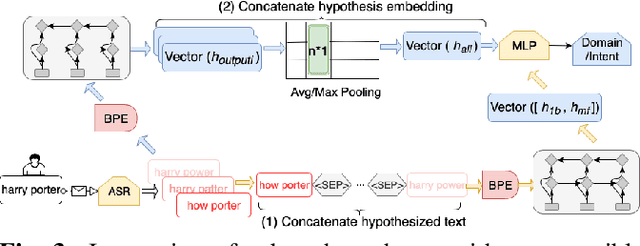
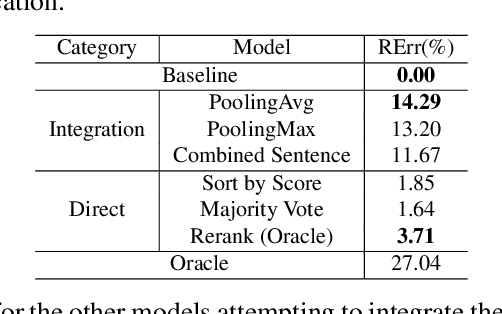
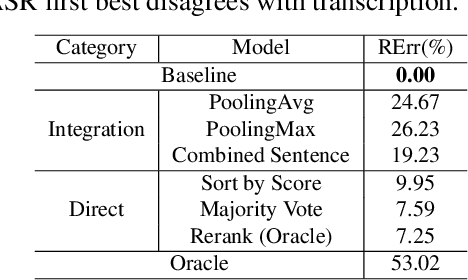
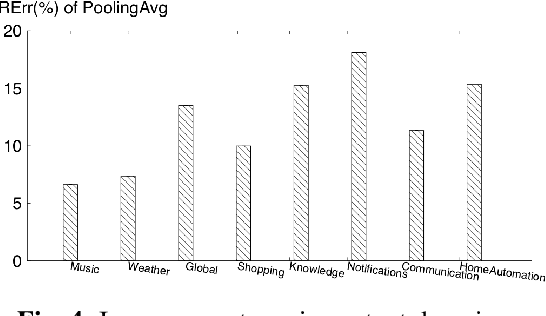
In a modern spoken language understanding (SLU) system, the natural language understanding (NLU) module takes interpretations of a speech from the automatic speech recognition (ASR) module as the input. The NLU module usually uses the first best interpretation of a given speech in downstream tasks such as domain and intent classification. However, the ASR module might misrecognize some speeches and the first best interpretation could be erroneous and noisy. Solely relying on the first best interpretation could make the performance of downstream tasks non-optimal. To address this issue, we introduce a series of simple yet efficient models for improving the understanding of semantics of the input speeches by collectively exploiting the n-best speech interpretations from the ASR module.
A Re-ranker Scheme for Integrating Large Scale NLU models
Sep 25, 2018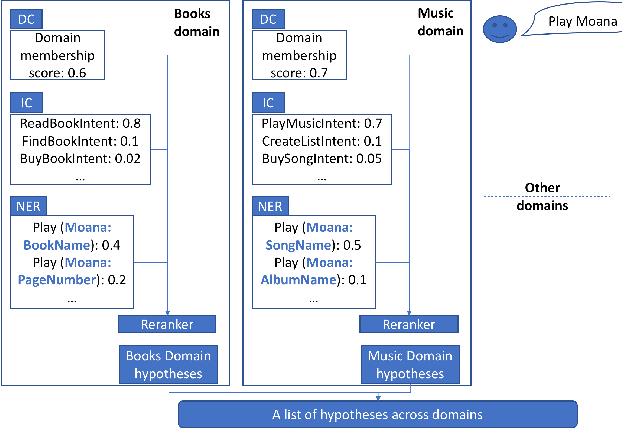
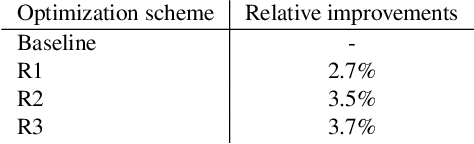


Large scale Natural Language Understanding (NLU) systems are typically trained on large quantities of data, requiring a fast and scalable training strategy. A typical design for NLU systems consists of domain-level NLU modules (domain classifier, intent classifier and named entity recognizer). Hypotheses (NLU interpretations consisting of various intent+slot combinations) from these domain specific modules are typically aggregated with another downstream component. The re-ranker integrates outputs from domain-level recognizers, returning a scored list of cross domain hypotheses. An ideal re-ranker will exhibit the following two properties: (a) it should prefer the most relevant hypothesis for the given input as the top hypothesis and, (b) the interpretation scores corresponding to each hypothesis produced by the re-ranker should be calibrated. Calibration allows the final NLU interpretation score to be comparable across domains. We propose a novel re-ranker strategy that addresses these aspects, while also maintaining domain specific modularity. We design optimization loss functions for such a modularized re-ranker and present results on decreasing the top hypothesis error rate as well as maintaining the model calibration. We also experiment with an extension involving training the domain specific re-rankers on datasets curated independently by each domain to allow further asynchronization. %The proposed re-ranker design showcases the following: (i) improved NLU performance over an unweighted aggregation strategy, (ii) cross-domain calibrated performance and, (iii) support for use cases involving training each re-ranker on datasets curated by each domain independently.