 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Small Language Models Help Large Language Models Reason Better?: LM-Guided Chain-of-Thought
Apr 04, 2024



We introduce a novel framework, LM-Guided CoT, that leverages a lightweight (i.e., <1B) language model (LM) for guiding a black-box large (i.e., >10B) LM in reasoning tasks. Specifically, the lightweight LM first generates a rationale for each input instance. The Frozen large LM is then prompted to predict a task output based on the rationale generated by the lightweight LM. Our approach is resource-efficient in the sense that it only requires training the lightweight LM. We optimize the model through 1) knowledge distillation and 2) reinforcement learning from rationale-oriented and task-oriented reward signals. We assess our method with multi-hop extractive question answering (QA) benchmarks, HotpotQA, and 2WikiMultiHopQA. Experimental results show that our approach outperforms all baselines regarding answer prediction accuracy. We also find that reinforcement learning helps the model to produce higher-quality rationales with improved QA performance.
Building Goal-Oriented Dialogue Systems with Situated Visual Context
Nov 22, 2021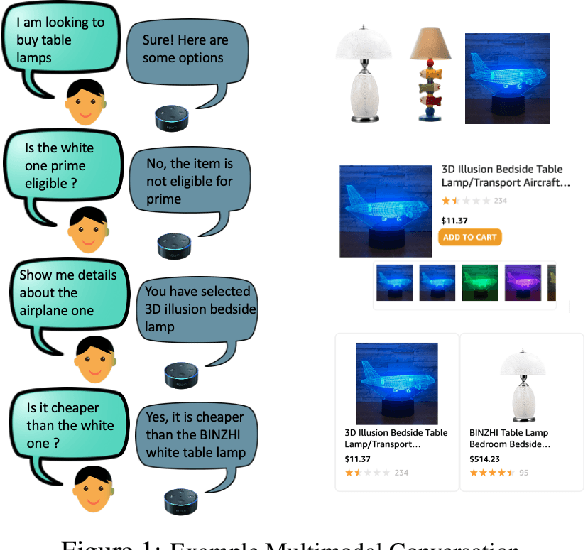
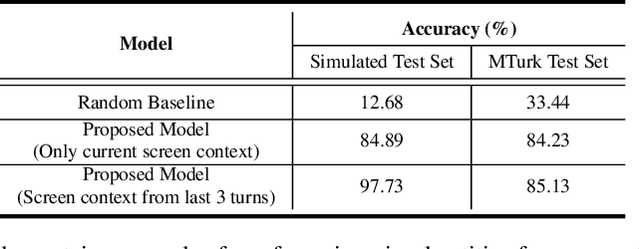
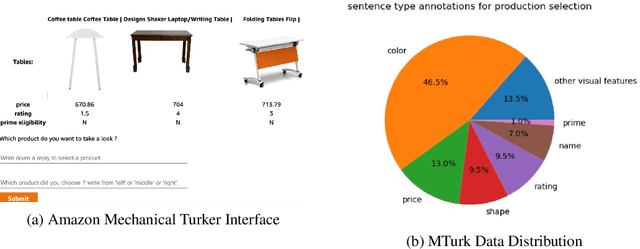
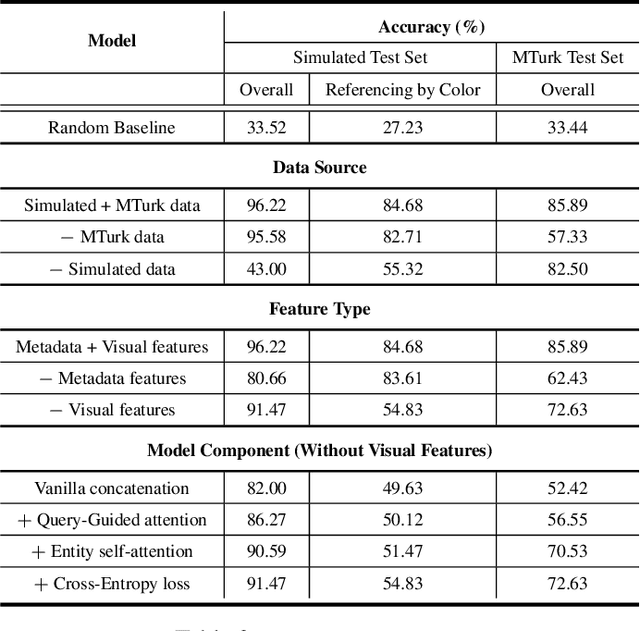
Most popular goal-oriented dialogue agents are capable of understanding the conversational context. However, with the surge of virtual assistants with screen, the next generation of agents are required to also understand screen context in order to provide a proper interactive experience, and better understand users' goals. In this paper, we propose a novel multimodal conversational framework, where the dialogue agent's next action and their arguments are derived jointly conditioned both on the conversational and the visual context. Specifically, we propose a new model, that can reason over the visual context within a conversation and populate API arguments with visual entities given the user query. Our model can recognize visual features such as color and shape as well as the metadata based features such as price or star rating associated with a visual entity. In order to train our model, due to a lack of suitable multimodal conversational datasets, we also propose a novel multimodal dialog simulator to generate synthetic data and also collect realistic user data from MTurk to improve model robustness. The proposed model achieves a reasonable 85% model accuracy, without high inference latency. We also demonstrate the proposed approach in a prototypical furniture shopping experience for a multimodal virtual assistant.