 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Low-Resource Dialogue State Tracking by Prompt Tuning
Jan 26, 2023



Dialogue state tracking (DST) is an important step in dialogue management to keep track of users' beliefs. Existing works fine-tune all language model (LM) parameters to tackle the DST task, which requires significant data and computing resources for training and hosting. The cost grows exponentially in the real-world deployment where dozens of fine-tuned LM are used for different domains and tasks. To reduce parameter size and better utilize cross-task shared information, we propose to use soft prompt token embeddings to learn task properties. Without tuning LM parameters, our method drastically reduces the number of parameters needed to less than 0.5% of prior works while achieves better low-resource DST performance.
Context-Situated Pun Generation
Oct 24, 2022


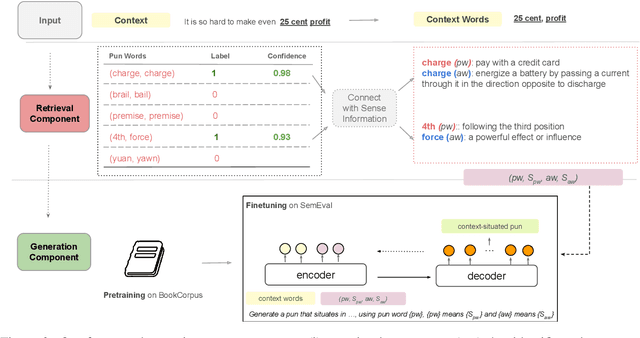
Previous work on pun generation commonly begins with a given pun word (a pair of homophones for heterographic pun generation and a polyseme for homographic pun generation) and seeks to generate an appropriate pun. While this may enable efficient pun generation, we believe that a pun is most entertaining if it fits appropriately within a given context, e.g., a given situation or dialogue. In this work, we propose a new task, context-situated pun generation, where a specific context represented by a set of keywords is provided, and the task is to first identify suitable pun words that are appropriate for the context, then generate puns based on the context keywords and the identified pun words. We collect CUP (Context-sitUated Pun), containing 4.5k tuples of context words and pun pairs. Based on the new data and setup, we propose a pipeline system for context-situated pun generation, including a pun word retrieval module that identifies suitable pun words for a given context, and a generation module that generates puns from context keywords and pun words. Human evaluation shows that 69% of our top retrieved pun words can be used to generate context-situated puns, and our generation module yields successful puns 31% of the time given a plausible tuple of context words and pun pair, almost tripling the yield of a state-of-the-art pun generation model. With an end-to-end evaluation, our pipeline system with the top-1 retrieved pun pair for a given context can generate successful puns 40% of the time, better than all other modeling variations but 32% lower than the human success rate. This highlights the difficulty of the task, and encourages more research in this direction.
Towards Textual Out-of-Domain Detection without In-Domain Labels
Mar 22, 2022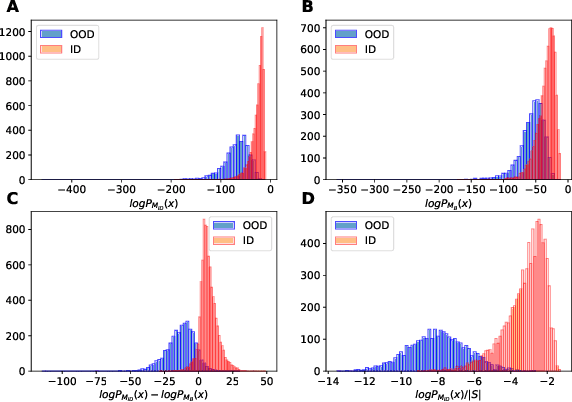
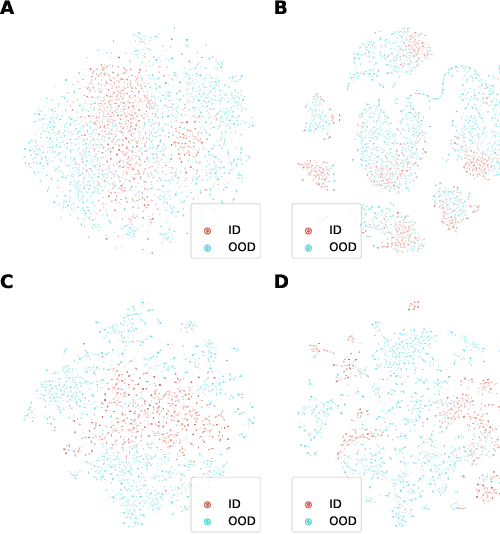
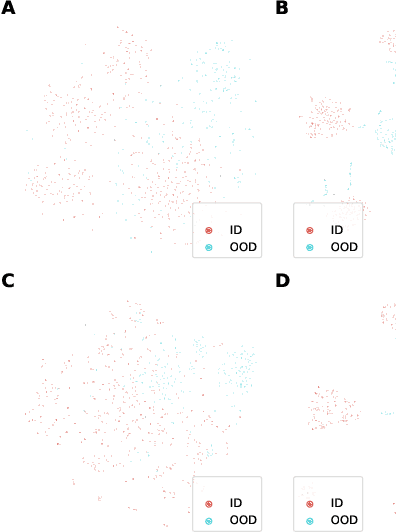
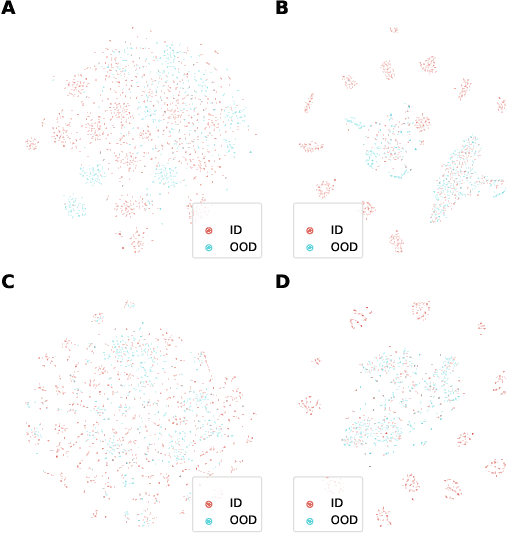
In many real-world settings, machine learning models need to identify user inputs that are out-of-domain (OOD) so as to avoid performing wrong actions. This work focuses on a challenging case of OOD detection, where no labels for in-domain data are accessible (e.g., no intent labels for the intent classification task). To this end, we first evaluate different language model based approaches that predict likelihood for a sequence of tokens. Furthermore, we propose a novel representation learning based method by combining unsupervised clustering and contrastive learning so that better data representations for OOD detection can be learned. Through extensive experiments, we demonstrate that this method can significantly outperform likelihood-based methods and can be even competitive to the state-of-the-art supervised approaches with label information.
Building Goal-Oriented Dialogue Systems with Situated Visual Context
Nov 22, 2021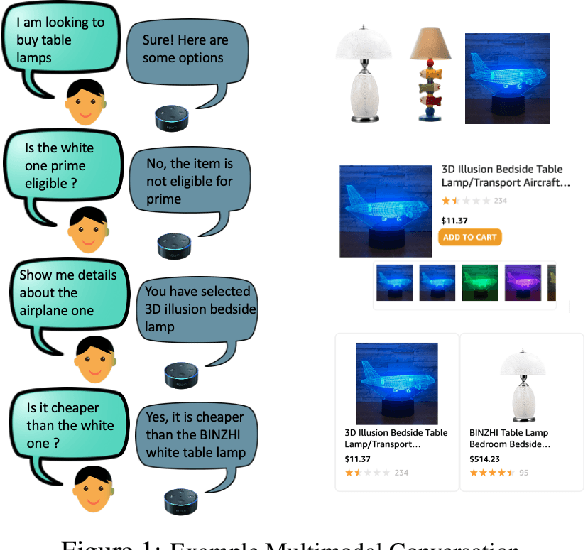
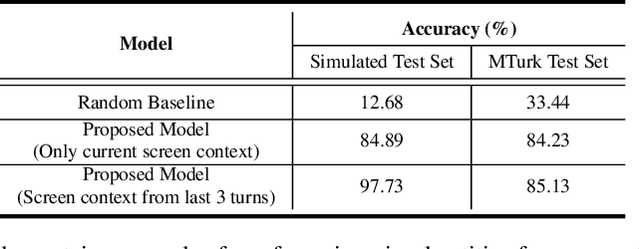
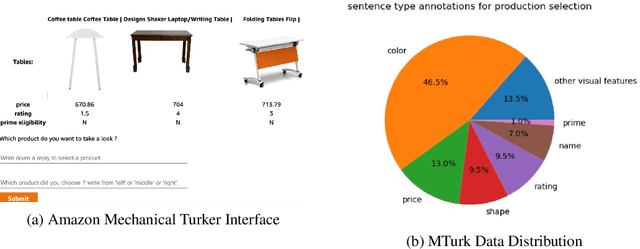
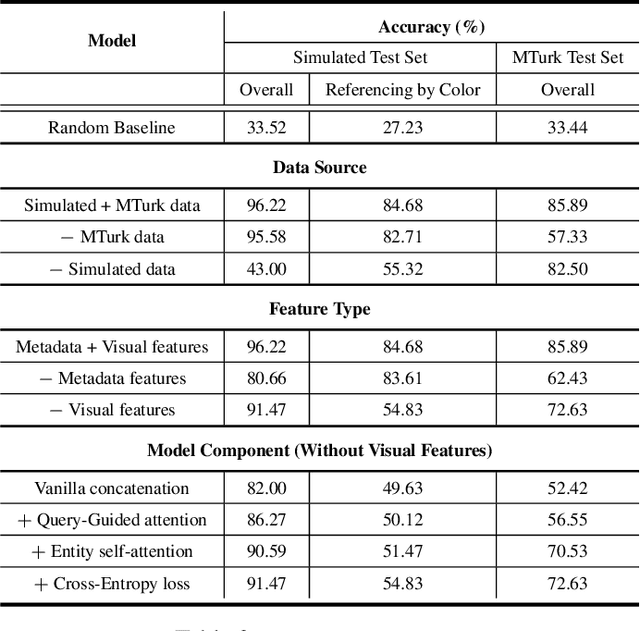
Most popular goal-oriented dialogue agents are capable of understanding the conversational context. However, with the surge of virtual assistants with screen, the next generation of agents are required to also understand screen context in order to provide a proper interactive experience, and better understand users' goals. In this paper, we propose a novel multimodal conversational framework, where the dialogue agent's next action and their arguments are derived jointly conditioned both on the conversational and the visual context. Specifically, we propose a new model, that can reason over the visual context within a conversation and populate API arguments with visual entities given the user query. Our model can recognize visual features such as color and shape as well as the metadata based features such as price or star rating associated with a visual entity. In order to train our model, due to a lack of suitable multimodal conversational datasets, we also propose a novel multimodal dialog simulator to generate synthetic data and also collect realistic user data from MTurk to improve model robustness. The proposed model achieves a reasonable 85% model accuracy, without high inference latency. We also demonstrate the proposed approach in a prototypical furniture shopping experience for a multimodal virtual assistant.
Towards Zero and Few-shot Knowledge-seeking Turn Detection in Task-orientated Dialogue Systems
Sep 18, 2021
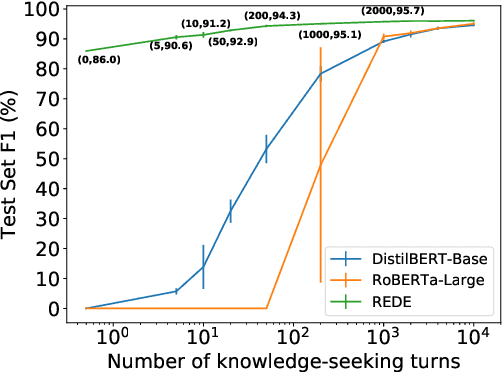
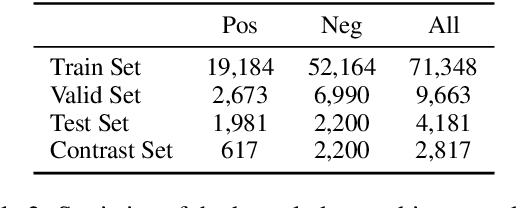
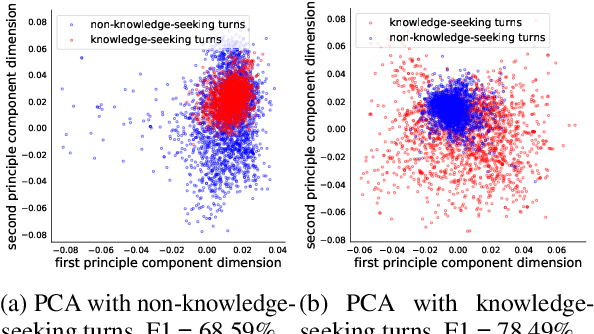
Most prior work on task-oriented dialogue systems is restricted to supporting domain APIs. However, users may have requests that are out of the scope of these APIs. This work focuses on identifying such user requests. Existing methods for this task mainly rely on fine-tuning pre-trained models on large annotated data. We propose a novel method, REDE, based on adaptive representation learning and density estimation. REDE can be applied to zero-shot cases, and quickly learns a high-performing detector with only a few shots by updating less than 3K parameters. We demonstrate REDE's competitive performance on DSTC9 data and our newly collected test set.
Simpler, Faster, Stronger: Breaking The log-K Curse On Contrastive Learners With FlatNCE
Jul 02, 2021



InfoNCE-based contrastive representation learners, such as SimCLR, have been tremendously successful in recent years. However, these contrastive schemes are notoriously resource demanding, as their effectiveness breaks down with small-batch training (i.e., the log-K curse, whereas K is the batch-size). In this work, we reveal mathematically why contrastive learners fail in the small-batch-size regime, and present a novel simple, non-trivial contrastive objective named FlatNCE, which fixes this issue. Unlike InfoNCE, our FlatNCE no longer explicitly appeals to a discriminative classification goal for contrastive learning. Theoretically, we show FlatNCE is the mathematical dual formulation of InfoNCE, thus bridging the classical literature on energy modeling; and empirically, we demonstrate that, with minimal modification of code, FlatNCE enables immediate performance boost independent of the subject-matter engineering efforts. The significance of this work is furthered by the powerful generalization of contrastive learning techniques, and the introduction of new tools to monitor and diagnose contrastive training. We substantiate our claims with empirical evidence on CIFAR10, ImageNet, and other datasets, where FlatNCE consistently outperforms InfoNCE.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
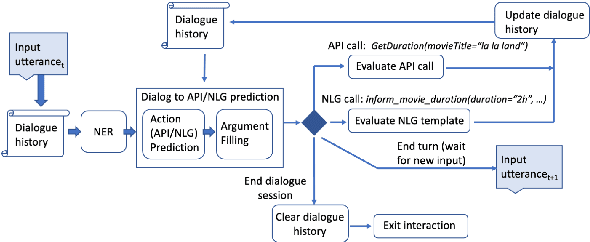

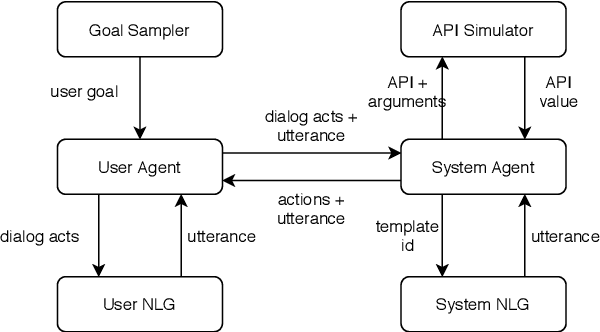
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
From Machine Reading Comprehension to Dialogue State Tracking: Bridging the Gap
Apr 13, 2020



Dialogue state tracking (DST) is at the heart of task-oriented dialogue systems. However, the scarcity of labeled data is an obstacle to building accurate and robust state tracking systems that work across a variety of domains. Existing approaches generally require some dialogue data with state information and their ability to generalize to unknown domains is limited. In this paper, we propose using machine reading comprehension (RC) in state tracking from two perspectives: model architectures and datasets. We divide the slot types in dialogue state into categorical or extractive to borrow the advantages from both multiple-choice and span-based reading comprehension models. Our method achieves near the current state-of-the-art in joint goal accuracy on MultiWOZ 2.1 given full training data. More importantly, by leveraging machine reading comprehension datasets, our method outperforms the existing approaches by many a large margin in few-shot scenarios when the availability of in-domain data is limited. Lastly, even without any state tracking data, i.e., zero-shot scenario, our proposed approach achieves greater than 90% average slot accuracy in 12 out of 30 slots in MultiWOZ 2.1.
Controlled Text Generation for Data Augmentation in Intelligent Artificial Agents
Oct 04, 2019
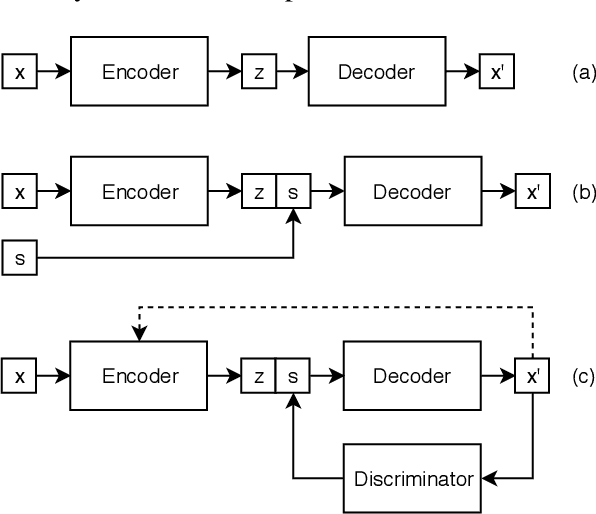
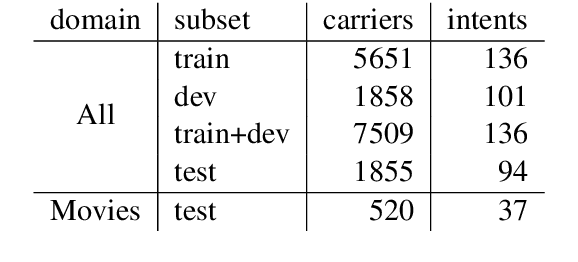
Data availability is a bottleneck during early stages of development of new capabilities for intelligent artificial agents. We investigate the use of text generation techniques to augment the training data of a popular commercial artificial agent across categories of functionality, with the goal of faster development of new functionality. We explore a variety of encoder-decoder generative models for synthetic training data generation and propose using conditional variational auto-encoders. Our approach requires only direct optimization, works well with limited data and significantly outperforms the previous controlled text generation techniques. Further, the generated data are used as additional training samples in an extrinsic intent classification task, leading to improved performance by up to 5\% absolute f-score in low-resource cases, validating the usefulness of our approach.
MMM: Multi-stage Multi-task Learning for Multi-choice Reading Comprehension
Oct 01, 2019
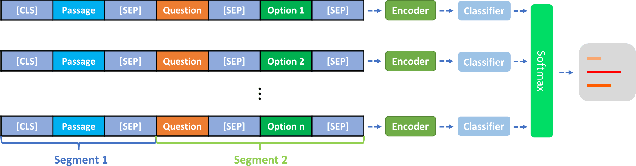
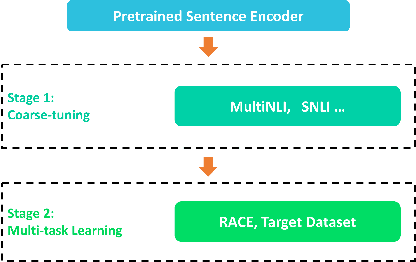

Machine Reading Comprehension (MRC) for question answering (QA), which aims to answer a question given the relevant context passages, is an important way to test the ability of intelligence systems to understand human language. Multiple-Choice QA (MCQA) is one of the most difficult tasks in MRC because it often requires more advanced reading comprehension skills such as logical reasoning, summarization, and arithmetic operations, compared to the extractive counterpart where answers are usually spans of text within given passages. Moreover, most existing MCQA datasets are small in size, making the learning task even harder. We introduce MMM, a Multi-stage Multi-task learning framework for Multi-choice reading comprehension. Our method involves two sequential stages: coarse-tuning stage using out-of-domain datasets and multi-task learning stage using a larger in-domain dataset to help model generalize better with limited data. Furthermore, we propose a novel multi-step attention network (MAN) as the top-level classifier for this task. We demonstrate MMM significantly advances the state-of-the-art on four representative MCQA datasets.