 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlled Text Generation for Data Augmentation in Intelligent Artificial Agents
Paper and Code
Oct 04, 2019
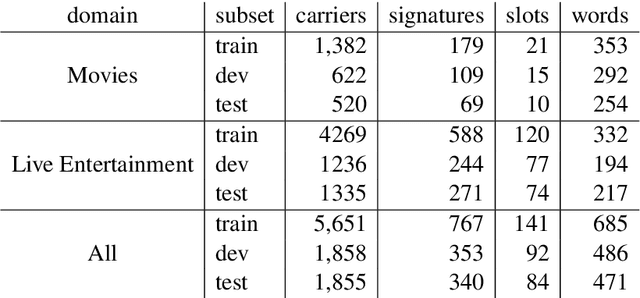
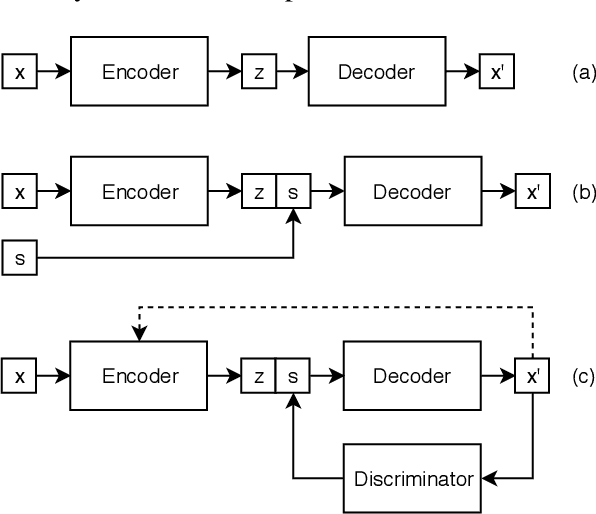
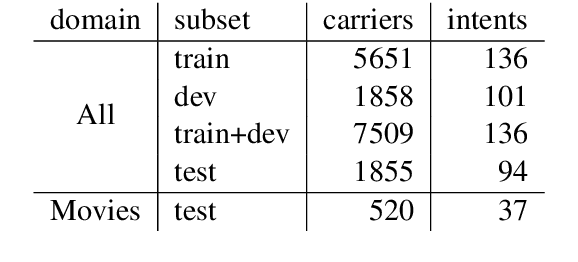
Data availability is a bottleneck during early stages of development of new capabilities for intelligent artificial agents. We investigate the use of text generation techniques to augment the training data of a popular commercial artificial agent across categories of functionality, with the goal of faster development of new functionality. We explore a variety of encoder-decoder generative models for synthetic training data generation and propose using conditional variational auto-encoders. Our approach requires only direct optimization, works well with limited data and significantly outperforms the previous controlled text generation techniques. Further, the generated data are used as additional training samples in an extrinsic intent classification task, leading to improved performance by up to 5\% absolute f-score in low-resource cases, validating the usefulness of our approach.